
Acidi nucleici
Acidi nucleici
di Erwin Chargaff
Acidi nucleici
sommario: 1. Introduzione. a) Il problema della cellula vivente. b) Le sostanze presenti in una cellula sono uguali a quelle che ne vengono estratte? c) Le ricerche sulla struttura e sulla funzione. d) L'organizzazione della cellula. 2. La scoperta degli acidi nucleici. 3. Due classi di acidi nucleici. 4. La scoperta dei costituenti degli acidi nucleici. 5. Proprietà chimiche dei costituenti degli acidi nucleici. a) Zuccheri. b) Purine e pirimidine. c) Nucleosidi e nucleotidi. 6. La linea di sviluppo fino ai nostri attuali concetti. 7. Nucleoproteine e chimica generale degli acidi nucleici. a) Nucleoproteine. b) Chimica generale. 8. Acidi desossiribonucleici. a) Composizione del DNA e illustrazione del principio di appaiamento delle basi. b) Struttura e proprietà fisiche. c) Prodotti di degradazione parziale e studio della sequenza dei nucleotidi. 9. Acidi ribonucleici. a) I vari tipi di RNA nelle cellule. b) RNA ribosomiale. c) RNA messaggero. d) Il codice genetico. e) RNA transfer. 10. Enzimi che intervengono nella biosintesi degli acidi nucleici. a) Biosintesi dei ribonucleotidi. b) Biosintesi dei desossiribonucleotidi. c) Meccanismi di recupero e altre ‛scorciatoie' . d) Enzimi della sintesi dei polinucleotidi. 11. Enzimi che intervengono nel catabolismo degli acidi nucleici. 12. Conclusioni. □ Bibliografia.
1. Introduzione
a) Il problema della cellula vivente
Molte scienze naturali si ritengono impegnate nello studio dei sistemi viventi: per la biologia l'attributo della vita si riflette nel suo stesso nome; per altre scienze questa relazione con la vita viene indicata dal prefisso ‛bio', come nel caso della biofisica o della biochimica. Numerose altre scienze si sono via via concentrate sullo studio della vita e vengono incluse nella generica categoria di ‛scienze della vita'; ma questa convergenza di sforzi, spesso coronati da clamorosi successi, non deve nasconderci il fatto che non possediamo, e non saremo in grado di possedere per molto tempo ancora, una definizione scientificamente accettabile della vita: in verità si potrebbe affermare che la vita è uno stato intorno al quale il teologo, il filosofo od il poeta possono dissertare con maggior competenza dello scienziato. Soltanto un'epoca in cui l'ampiezza della scienza è pari al suo potere può trovare sorprendente tale affermazione.
Se esaminiamo una pietra, per esempio, possiamo affidarci ad alcune scienze per ottenere una descrizione abbastanza dettagliata delle sostanze che la compongono (chimica), oppure delle forze che la tengono insieme (fisica), o della sua forma e struttura (mineralogia, cristallografia); e la geologia può anche dirci perché quella pietra si trovi in quel luogo. Ma anche in questo semplice caso vi sono domande alle quali non si può rispondere, e che quindi non vengono poste, come, ad esempio: ‟qual è la funzione di quella pietra?" Vi sono molte domande proibite nelle scienze: in alcuni casi è proibito chiedere ‟perché?", in altri ‟a quale scopo?". Tuttavia, i sistemi inanimati si prestano generalmente ad una descrizione abbastanza soddisfacente: se ne può cogliere l'essenza, e quando ciò non è possibile si confida che lo diverrà prima o poi. A questo punto, resta ancora il rischio che il nostro compiacimento derivi semplicemente dal fatto che la pietra non è in grado di rispondere.
Le considerazioni precedenti non sono affatto valide, invece, nel caso della cellula vivente. Anche se chiedessimo l'ausilio di tutte le scienze, con e senza il prefisso ‛bio', che possono darci un'esauriente descrizione nei limiti delle loro rispettive possibilità, la vera essenza della cellula vivente continuerebbe ancora a sfuggirci. Nel migliore dei casi, ci ritroveremmo con la descrizione di una cellula morta.
È allora il prefisso ‛bio', a rigor di termini, lo scoglio del nostro naufragio? Sì e no. È vero che il biochimico deve uccidere la cellula per esaminarne la composizione, ma egli crede che i composti da lui estratti, purificati e studiati siano stati sintetizzati dalla cellula nel corso della vita della cellula stessa, e che essi rappresentino il materiale di cui la cellula è fatta. Infine, il biochimico è convinto che, quali che siano le funzioni attribuibili in vitro a tali composti, le medesime funzioni vengano svolte anche in vivo. Ma tale convinzione è giustificata?
b) Le sostanze presenti in una cellula sono uguali a quelle che ne vengono estratte?
Sembra una domanda sciocca: ma sarebbe sbagliato adontarsene. In verità, sarebbe stato tutt'altro che privo di senso porsi questa domanda nelle prime fasi della ricerca biochimica. Quando le cellule vengono usate in un liquido - come l'acqua, o una soluzione acquosa salina o di zucchero, oppure un solvente organico - il loro contenuto passa in soluzione o sospensione: le sostanze solubili nel mezzo in questione vengono disciolte in esso, le altre rimangono indisciolte. Ma questo non è tutto: poiché la cellula vivente non può essere descritta né come un solido né come un liquido - essa è un campo di interazioni ancora indefinibile - l'introduzione di qualsiasi liquido di estrazione, e ancor più l'evento irreversibile della distruzione delle strutture che si accompagna all'apertura della cellula, provocano necessariamente un numero indefinito, ma certamente enorme, di alterazioni a cui si può sfuggire solo parzialmente. Generalmente si prendono precauzioni di vario tipo: si lavora, per esempio, ad una bassa temperatura, a cui la maggior parte degli enzimi non è attiva o agisce molto lentamente; si introducono alcuni inibitori o si allontanano alcuni cofattori, per ostacolare reazioni enzimatiche indesiderabili; si procede il più rapidamente possibile ad un frazionamento preliminare dell'estratto, così da concentrare la sostanza in esame in una frazione, e quindi proteggerla dall'attacco di almeno alcune delle altre sostanze presenti nell'estratto originario. Eppure, resta sempre il fatto che abbiamo distrutto una impalcatura incredibilmente raffinata; che abbiamo interferito con un ordine il cui grado è insondabile; che, con il fatto stesso di separare i componenti cellulari, abbiamo distrutto la loro coesione entelechiale. Tutto ciò è ben noto ai biologi; ma la confusione babelica dei linguaggi scientifici e delle varie linee di pensiero ha precluso a molti biochimici finanche di porsi tali problemi, cosicché quando leggo titoli circa ‛la struttura e la funzione' di qualche macromolecola cellulare, so già che apprenderò molto sulla prima parte del titolo, ma quasi niente sulla seconda.
c) Le ricerche sulla struttura e sulla funzione
La struttura chimica e quella biologica non coincidono necessariamente, anche se si prende in considerazione una stessa molecola. Separazione, purificazione, cristallizzazione, analisi, sintesi: questi sono gli strumenti del chimico, ed effettuando queste operazioni egli resta fedele ai principî della propria scienza. I problemi che si pongono ad un biologo sono completamente differenti; egli deve preoccuparsi delle conseguenze che derivano dal raggruppamento di una moltitudine di composti e di complessi, i quali, benché spesso antagonisti l'uno dell'altro in soluzione, trovano un modo di coesistenza pacifica all'interno della cellula; una dimensione dell'omeostasi per la quale non si potrebbe proporre un termine scientifico più adatto di quello stesso di ‛vita'.
Al contrario di quanto accadde nei numerosi decenni di duro e ingegnoso lavoro che furono spesi per l'identificazione e la sintesi dei costituenti chimici di macromolecole - come gli acidi nucleici, le proteine, i polisaccaridi - si può dire che oggi la struttura chimica non rappresenta più un gran problema. Il grande affinamento della strumentazione fisica, come ad esempio la spettroscopia nell'ultravioletto e nell'infrarosso, la spettrografia di massa, la risonanza magnetica nucleare, il dicroismo circolare, l'ultracentrifugazione, la diffusione della luce, la cromatografia di adsorbimento e di affinità, l'applicazione di traccianti isotopici ecc., facilita il raggiungimento di obiettivi inimmaginabili fino a pochi anni fa. Questa meccanizzazione, questa automazione ha tolto alla ricerca scientifica molto del suo sapore, e oggi il chimico organico spesso non è altro che un calcolatore con la libera docenza. Se c'è una cosa chiara, è che nella scienza la capacità professionale frequentemente limita o addirittura distrugge l'immaginazione.
Ma è al biologo che il problema della funzione si pone in tutta la sua complessità. Egli può nascondersi, naturalmente, dietro il baluardo della teleologia evoluzionistica, asserendo che tutto ciò che si trova nella cellula vivente deve esserci con uno scopo; e, quando è sollecitato ad essere più preciso, egli dirà infine che non è compito suo rispondere a domande sciocche. La maggior parte delle discussioni di questo tipo termina con la conclusione peregrina che tutto ciò che esiste è ragionevole, trascurando così interamente l'elemento imprevedibile nella creazione.
Le funzioni in biologia non sono di solito il prodotto di un ragionamento induttivo, ma esse vengono attribuite, e spesso sulla base di prove piuttosto deboli. Possiamo estrarre, ad esempio, una frazione proteica da una cellula e poi cominciare a porre alcune domande alla proteina stessa. Ciò si realizza, in concreto, presentando a tale proteina un limitatissimo numero di composti chimici, i substrati. Se l'una o l'altra di queste sostanze viene attaccata o modificata cataliticamente dalla proteina, diremo che abbiamo scoperto un enzima e gli assegneremo una specifica funzione enzimatica, che esso presumibilmente svolge anche nella cellula vivente. Ciò può essere vero o falso: in ogni caso non sono molti gli enzimi dei quali si possa asserire senza ambiguità che la loro funzione nella cellula vivente è la stessa che in provetta. La difficoltà di attribuire una certa funzione, inoltre, è enormemente accresciuta quando ci troviamo in presenza di enzimi capaci di sintetizzare eteropolimeri dalla sequenza specifica - come proteine, polisaccaridi ed acidi nucleici - dal momento che le condizioni in cui tali enzimi vengono saggiati in vitro sono, nel migliore dei casi, un modello molto vago e semplificato di ciò che avviene in vivo.
L'estrazione, la purificazione e l'analisi chimica dell'elevatissimo numero di enzimi isolati da molti sistemi viventi, come pure il riconoscimento della loro funzione biologica, costituiscono in effetti uno dei vanti della biochimica contemporanea. Però molte di queste funzioni sono antagoniste fra loro: se si trova un enzima capace di edificare una macromolecola molto complessa, se ne troveranno anche molti altri capaci di decomporla o degradarla. È proprio questo eterno fare e disfare, è questo flusso e riflusso eracliteo, è questa compatibilità fra incompatibili che costituisce uno degli attributi della vita. Questa misteriosa coesistenza nella cellula di tanti nemici mortali, la cui stessa lotta sembra tenere in piedi l'edificio della vita, è solo insufficientemente spiegata con l'ipotesi di compartimenti intracellulari, di interspazi e membrane, di repressori e inibitori. Per superare tutte queste difficoltà, si ricorre di solito al concetto di organizzazione cellulare, un'organizzazione che deve esistere a livello macroscopico, microscopico, submicroscopico e perfino molecolare.
d) L'organizzazione della cellula
La cellula rappresenta certamente un sistema con un enorme numero di superfici di separazione, molte delle quali statiche, ma molte di più dinamiche. La maggior parte di esse dev'essere distrutta o fortemente deformata dal biochimico, se egli vuol procedere nel suo lavoro. La distinzione più semplice che si potrebbe fare è quella tra regioni idrofile e idrofobe, ma anch'essa è, a rigor di termini, difficilmente effettuabile: molte di queste regioni sono presumibilmente in costante flusso, affinché la cellula sia in grado di compiere le sue operazioni biologicamente rilevanti. Tuttavia, è possibile costruire una mappa strutturale della cellula, che si è dimostrata molto utile anche per la ricerca biochimica. È opportuno rammentare, ai fini del presente articolo, che gli acidi nucleici sono componenti ubiquitari della cellula: l'acido desossiribonucleico (DNA) si trova prevalentemente nella zona cromatinica ed eterocromatinica del nucleo, essendo uno dei costituenti principali dei cromosomi, ma si trova anche nel citoplasma, per esempio come componente dei mitocondri, dei cloroplasti, eccetera. L'acido ribonucleico (RNA) è più abbondante nel citoplasma, specialmente come componente dei ribosomi, e nelle regioni non particolate del citoplasma, ma si trova anche nel nucleo, in particolar modo nel nucleolo. Come vedremo subito, DNA ed RNA non sono designazioni al singolare, bensì collettive, poiché comprendono un grandissimo numero di specie e varietà diverse. Da questo punto di vista, i due nomi sono paragonabili a quelli di altri importanti costituenti cellulari, come le proteine, i polisaccaridi, i lipidi.
2. La scoperta degli acidi nucleici
Il giovane svizzero F. Miescher entrò nel 1868, all'età di 24 anni, in quello che era a quel tempo il più noto laboratorio biochimico, cioè quello di F. Hoppe-Seyler a Tubinga. Egli vi si era recato con il proposito di studiare il protoplasma delle cellule animali ed in particolare la chimica del nucleo cellulare. Appena un anno dopo, Miescher fu in grado di comunicare l'isolamento della ‛nucleina'. Si trattava, in termini attuali, della scoperta del primo acido nucleico, il desossiribonucleico (DNA), e della descrizione di una delle forme in cui esso esiste nel nucleo cellulare, cioè come nucleoproteina, il desossiribonucleoistone.
Questo lavoro, inviato da Miescher al suo ex maestro nel 1869, dopo il suo ritorno a Basilea, descriveva l'estrazione, dal nucleo di cellule di pus, di una sostanza organica che sembrava di nuovo tipo: infatti, era molto acida e conteneva fosforo. A quel tempo si conosceva, essenzialmente, un solo tipo di composti fosforilati cellulari ubiquitari: i fosfatidi chiamati ‛lecitine', nome oggi riservato ad un solo tipo di lipidi. Hoppe-Seyler, forse un po' incredulo, non pubblicò subito il lavoro, ma decise di ripetere e verificare le osservazioni fatte da Miescher. Due anni dopo, nel 1871, egli pubblicò il lavoro originale di Miescher aggiungendovi la descrizione dell'estrazione di sostanze analoghe dagli eritrociti di uccelli e dal lievito. Questa descrizione era già, di fatto, quella del secondo tipo di acido nucleico oggi noto, cioè l'acido ribonucleico (RNA). Così, mediante la collaborazione di due grandi biochimici, fu creato, in brevissimo tempo, un campo fondamentale e interamente nuovo della biochimica, una scienza allora assai giovane.
3. Due classi di acidi nucleici
Se Miescher e Hoppe-Seyler avessero avuto a loro disposizione metodi per l'idrolisi completa dei due tipi di acidi nucleici che avevano separato e se avessero potuto identificare tutti i frammenti prodotti dalla scissione delle molecole di acido nucleico - impresa a quel tempo ancora impensabile - essi avrebbero trovato sei componenti essenziali: quattro sostanze contenenti azoto, uno zucchero e, infine, acido fosforico. I nomi di questi componenti sono elencati nella tab. I; la loro struttura chimica verrà considerata in seguito. Ho omesso alcuni componenti minori che si possono incontrare occasionalmente; alcuni di essi saranno menzionati in seguito.
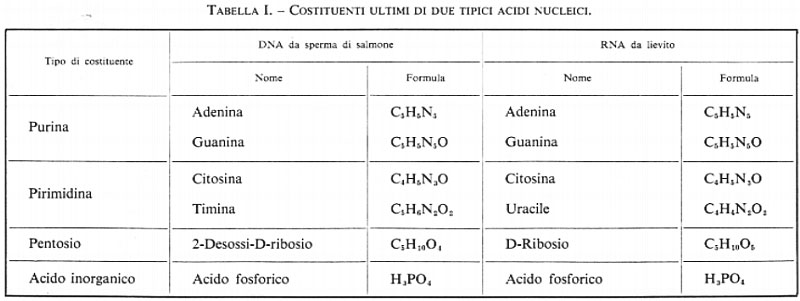
Come si può vedere nella tabella, tre dei quattro componenti azotati sono identici nei due tipi di acidi nucleici, una delle pirimidine, invece, è diversa: uracile nell'RNA, 5-metiluracile (timina) nel DNA. Entrambi gli acidi nucleici sono fosforilati. La loro principale differenza chimica - che poi è di grande importanza per le loro proprietà chimiche e biologiche - consiste nel diverso componente glicidico: ribosio nell'RNA e desossiribosio nel DNA. Da ciò si comprende che i due acidi nucleici derivano le loro diverse denominazioni dal tipo di zucchero che contengono. Un'altra differenza veramente notevole tra i due acidi nucleici, cioè il fatto che il peso molecolare del DNA sia molto maggiore di quello dell'RNA, non avrebbe potuto essere prevista dalla loro composizione chimica. Infatti, tale differenza è connessa con i rispettivi meccanismi di biosintesi o, se si vuole fare un discorso teleologico, con la loro diversa funzione biologica. Di ciò si parlerà più a lungo in seguito.
4. La scoperta dei costituenti degli acidi nucleici
Al tempo del loro isolamento e della loro caratterizzazione preliminare, la definizione del concetto di acidi nucleici non era, naturalmente, completa. Ci vollero molti anni per identificare i vari componenti e molti di più perché fossero sintetizzati. Anche il solo fatto di decidere quale delle molte purine e pirimidine facesse realmente parte del DNA e dell'RNA fu un compito estremamente laborioso. In qualche caso l'isolamento dei componenti avvenne prima della scoperta degli acidi nucleici.
Dei quattro principali costituenti azotati del DNA, la guanina era conosciuta molto prima dell'isolamento degli acidi nucleici (fin dal 1844). L'adenina (1885), la timina (1893) e la citosina (1894) furono riconosciute nel laboratorio di A. Kossel. L'unica pirimidina specifica dell'RNA, l'uracile, fu scoperta nel 1900. L'espressione ‛acidi nucleici' per il materiale designato come ‛nucleina' da Miescher fu introdotta da R. Altmann nel 1889.
Nessuna ulteriore aggiunta è stata fatta durante questo periodo allo scarno elenco delle basi contenute negli acidi nucleici: due purine, due pirimidine. I pochi altri costituenti azotati di cui si conosce oggi la presenza per lo più in piccole quantità, in alcune specie di acidi nucleici, sono stati scoperti molto più tardi.
La parte più importante delle ricerche sui composti base-zucchero, i nucleosidi, e sui loro derivati fosforilati, i nucleotidi (i quali, come sarà chiarito in seguito, sono gli elementi costitutivi degli acidi nucleici) è stata compiuta nei laboratori di S.J. Thannhauser e P.A. Levene. Il secondo ha il merito maggiore nel riconoscimento della parte glicidica del DNA e dell'RNA, cioè il 2-desossi-D-ribosio ed il D-ribosio rispettivamente.
5. Proprietà chimiche dei costituenti degli acidi nucleici
a) Zuccheri
Le strutture chimiche del D-ribosio (1) e del 2-desossi-D-ribosio (2) sono presentate in due forme, quella lineare (1a e 2a) e quella furanosica (1b e 2b), nella quale saranno rappresentati come componenti dei nucleosidi e dei nucleotidi.
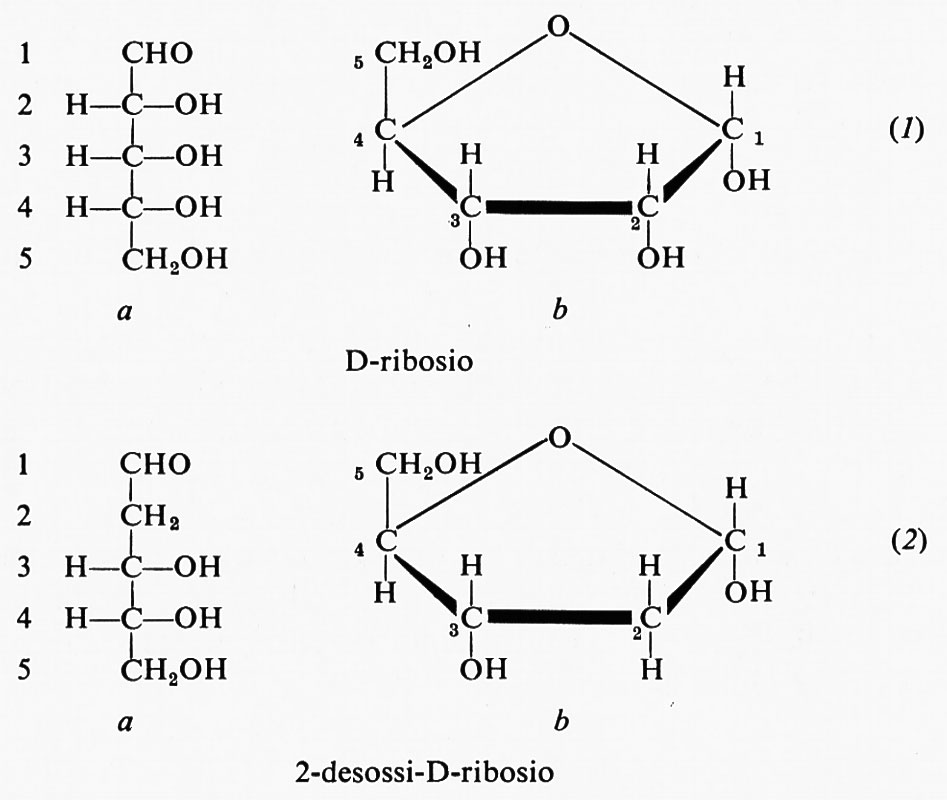
Non risulta che altri zuccheri siano presenti negli acidi nucleici. La differenza tra il composto (1), che si trova nell'RNA, e quello (2), presente nel DNA, è tutt'altro che banale: l'assenza di un gruppo idrossilico sul carbonio 2 del desossiribosio è di grande importanza per le differenze nel comportamento chimico dei due acidi nucleici.
La presenza del ribosio si riconosce generalmente per mezzo della comune reazione colorata dei pentosi con l'orcinolo; quella del desossiribosio attraverso una specifica reazione colorata con la difenilammina, scoperta da Z. Dische.
b) Purine e pirimidine
Il sistema di numerazione impiegato qui per i vari derivati purinici e pirimidinici riscontrabili negli acidi nucleici è illustrato nelle strutture (3) e (4), nelle quali sono omessi gli atomi di carbonio.

Le due purine che si trovano negli acidi nucleici sono derivati della struttura (3) e cioè l'adenina (5) e la guanina (6).
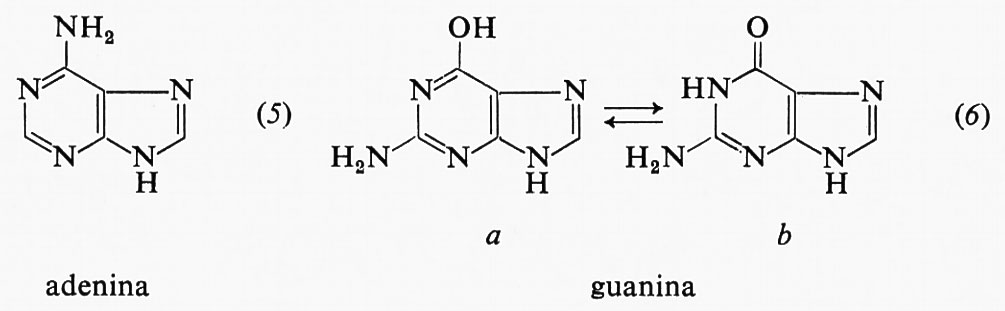
La guanina è rappresentata in due forme tautomere, poiché è nella forma ‛cheto' (6b) che si trova negli acidi nucleici. In pochi casi isolati, derivati metilici di queste purine entrano a far parte degli acidi nucleici come componenti secondari.
I due principali derivati pirimidinici del DNA, come già detto, sono la citosina (7) e la timina (8), mentre nell'RNA si trovano la citosina (7) e l'uracile (9).
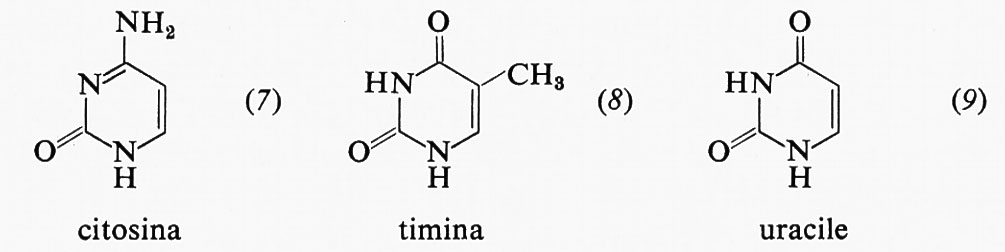
Queste pirimidine sono riportate qui ciascuna in una delle due forme tautomere, e precisamente quella in cui esse si presentano negli acidi nucleici. Poche altre pirimidine possono trovarsi negli acidi nucleici, talvolta in quantità rilevanti, come la 5-idrossimetilcitosina ed il 5-idrossimetiluracile ed anche la 5-metilcitosina, presente soprattutto in acidi nucleici di origine vegetale.
Un'importante proprietà fisica di tutti questi composti azotati consiste nel loro caratteristico e specifico assorbimento di luce nell'ultravioletto. Parleremo dei relativi spettri nel paragrafo successivo. Infatti, è stata proprio la suddetta proprietà fisica a facilitare la separazione e la determinazione quantitativa delle purine e delle pirimidine in piccole quantità. Preparati idrolizzati di acidi nucleici possono essere analizzati quantitativamente mediante separazione cromatografica su carta da filtro, seguita dalla rivelazione a luce ultravioletta delle macchie separate, dall'estrazione delle zone di assorbimento e dalla determinazione spettrofotometrica delle basi. Sono stati impiegati anche altri metodi, come la cromatografia su strato sottile, le colonne di resine scambiatrici, ecc.
c) Nucleosidi e nucleotidi
I derivati glicosidici delle purine e delle pirimidine si chiamano nucleosidi. In questi composti lo zucchero, ribosio o desossiribosio, si lega, tramite il suo atomo di carbonio 1, alla posizione 9 delle purine o alla posizione 3 delle pirimidine. Si tratta quindi di cosiddetti N-glicosidi. Sono riportati qui di seguito due esempi di ribonucleosidi, l'adenosina (10) e la citidina (11), insieme con due desossiribonucleosidi, e cioè la desossiguanosina (12) e la timidina (13).
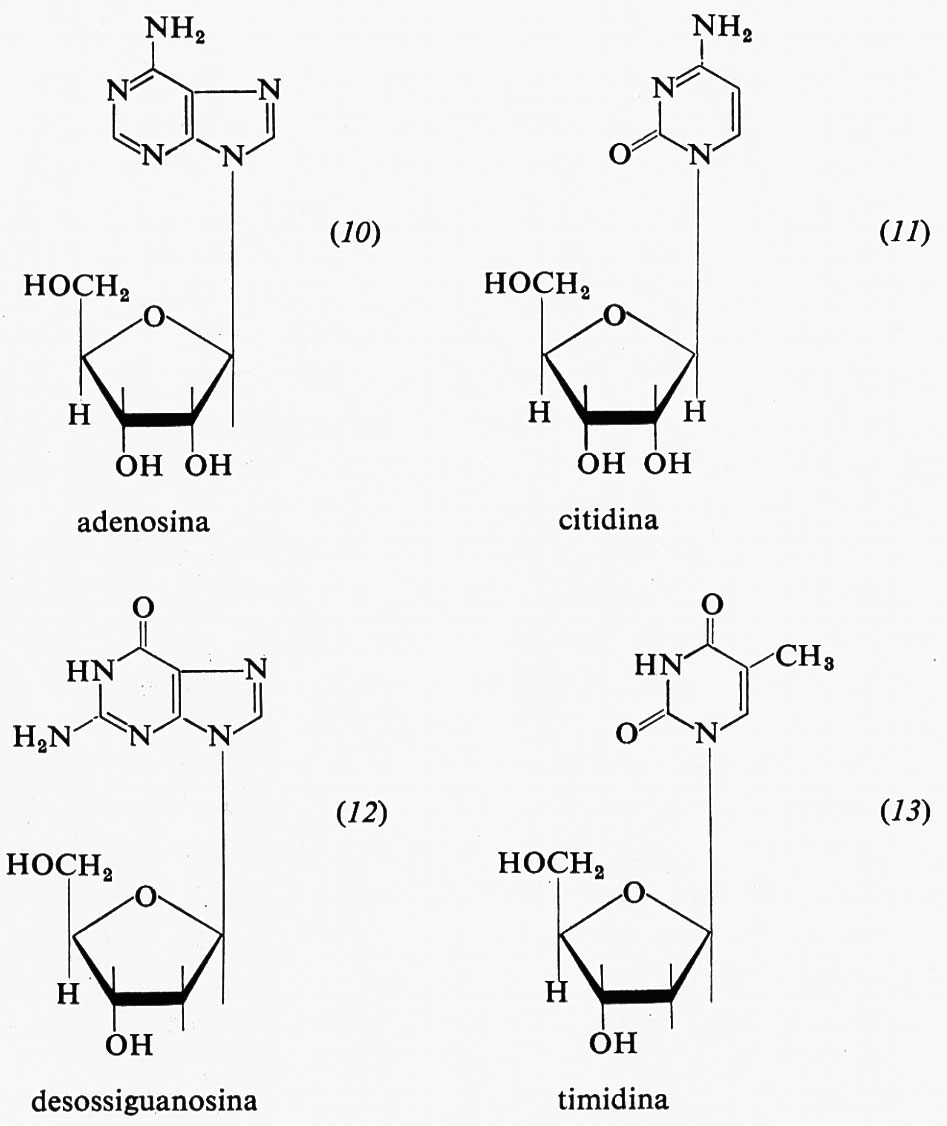
Le denominazioni dei nucleosidi, che si ritiene siano tutti N-glicosidi dalla configurazione β, è la seguente: a) nella serie del ribosio: adenosina (10), guanosina (1 + 6), citidina (11), uridina (1 + 9); b) nella serie del desossiribosio: la desossiadenosina (2 + 5), la desossiguanosina (12), la desossicitidina (2 + 7) e la timidina (13).
Bisogna anche menzionare un insolito ribonucleoside presente in alcuni acidi ribonucleici: la pseudouridina (14), un isomero della ubiquitaria uridina, in cui lo zucchero non si trova come N-glicoside, ma è legato ad un atomo di carbonio dell'uracile in posizione 5.

Il legame glicosidico dei nucleosidi purinici è piuttosto labile; questi composti, per trattamento con acidi, sono rapidamente idrolizzati in purina e zucchero. I nucleosidi pirimidinici sono molto più resistenti, ma possono essere idrolizzati dopo idrogenazione del nucleo pirimidinico. La loro analisi vien fatta in modo simile a quello riportato in precedenza per le purine e le pirimidine e a quello dei nucleotidi che verrà adesso esposto.
Gli esteri dei nucleosidi con l'acido fosforico prendono il nome di ‛nucleotidi'. Poiché il radicale ribosidico di un ribonucleoside possiede tre idrossili esterificabili, in posizione 2, 3 e 5, si può prevedere l'esistenza di tre diversi ribonucleotidi. Analogamente, i desossiribonucleotidi, che hanno un idrossile in meno (quello in posizione 2), devono esistere in due forme. Tutte queste forme possono essere isolate mediante opportuna degradazione degli acidi nucleici e molte di esse sono state anche sintetizzate in laboratorio.
Dei molti possibili nucleotidi, o nucleosidi monofosfati, ne riportiamo qui due, e cioè l'acido 5′-adenilico o adenosin-5′-fosfato (15) e l'acido timidilico (16). Abbiamo preferito un modo un po' differente di rappresentazione, così da rendere chiaro il tipo di numerazione impiegato nel riferirci a queste sostanze. Gli atomi che costituiscono l'anello purinico, come si vede, sono numerati da 1 a 9, quelli dell'anello pirimidinico da 1 a 6, mentre gli atomi di carbonio della parte glicidica di un nucleotide o di un nucleoside sono numerati da 1′ a 5′. È quindi possibile indicare senza ambiguità sia i sostituenti delle basi, sia quelli delle componenti glicidiche.
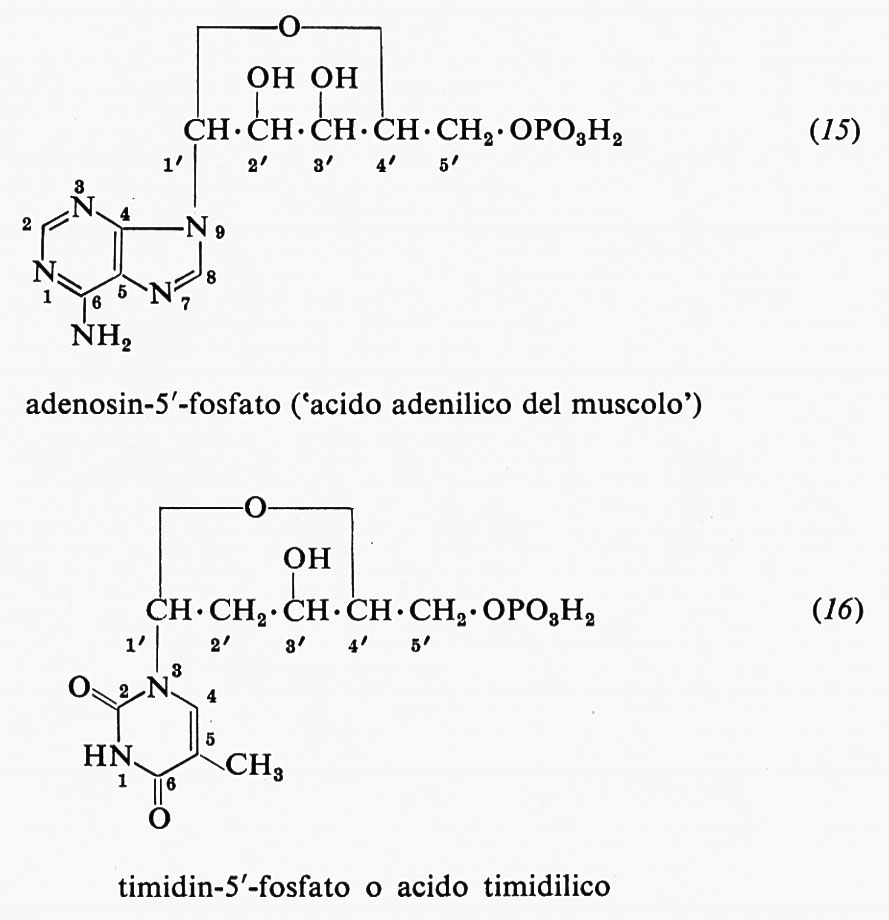
I nomi correnti dei nucleotidi che costituiscono le unità fondamentali dell'RNA e del DNA sono derivati dalla base che essi contengono; quando sono usati senza prefisso, si riferiscono ai ribonucleotidi, mentre per i desossiribonucleotidi, ad eccezione dell'acido timidilico, si usa il prefisso ‛desossi' o ‛d'.
Altri ribonucleotidi di grande importanza biologica, e che risultano correlati a quelli ottenibili dall'RNA, sono l'adenosintrifosfato (ATP), in cui un residuo trifosforico è legato in posizione 5′ al posto del residuo monofosforico del composto (15), e l'AMP ciclico, in cui l'acido fosforico in posizione 5′ del composto (15) forma un secondo legame estereo con l'idrossile 3′ dello stesso zucchero.
Per mezzo di opportuni enzimi è possibile liberare i singoli nucleotidi costituenti il DNA. Inoltre l'RNA può essere sottoposto a idrolisi alcalina, che libera una miscela di nucleosidi 2′- e 3′-fosfati.
Come si può ricavare dalla loro struttura, i nucleotidi, essendo acidi forti, si trovano all'interno delle cellule e ne vengono isolati, di solito, come sali. Essi possono essere separati mediante cromatografia su carta o su strato sottile o, ancora meglio, mediante adsorbimento ed eluzione da colonne cromatografiche a scambio ionico. La caratteristica fisica più peculiare dei nucleotidi è lo spettro di assorbimento nell'ultravioletto. Durante l'analisi, i caratteristici rapporti dell'assorbimento a due diverse lunghezze d'onda servono molto spesso ad identificarli. Nella maggior parte dei casi gli spettri sono fortemente influenzati dal pH della soluzione e di ciò si deve tener conto, per poter ottenere risultati confrontabili, controllando accuratamente la concentrazione idrogenionica. A titolo di esempio, riportiamo nella fig. 1 gli spettri di assorbimento della timina (8) e del suo desossiribonucleoside timidina (13), ottenuti a pH 7.
6. La linea di sviluppo fino ai nostri attuali concetti
Mentre veniva effettuata una vasta mole di ottimo lavoro sulla chimica dei costituenti degli acidi nucleici e mentre venivano elaborati metodi per la loro sintesi, ad esempio ad opera di Emil Fischer, di Traube, di Wheeler, di Johnson, ecc., si andava contemporaneamente oscurando la visione di insieme di ciò che gli acidi nucleici realmente fossero. È chiaro che lo stesso Miescher considerava gli acidi nucleici come sostanze molto complesse; ma questo punto di vista mutò ben presto. Le tendenze teoriche e sperimentali alle quali va di solito attribuito sia lo sviluppo sia l'accoglimento di un dato concetto scientifico sono governate da forze complesse, che possono a buon diritto essere definite ‛mode' scientifiche. Talvolta è possibile individuare chi o che cosa abbia determinato una certa moda, mentre più di frequente ciò è impossibile. Una nuova tecnica, una volta introdotta, può essere adottata e applicata in modo più o meno appropriato; un nuovo strumento può permettere di realizzare esperimenti che prima non potevano nemmeno esser presi in considerazione. Nel caso degli acidi nucleici, non vi è dubbio che il rapido ampliamento delle nostre conoscenze sia dovuto essenzialmente alla costruzione di spettrofotometri per l'ultravioletto e alla scoperta della cromatografia su carta e di altri sistemi di cromatografia di ripartizione.
Può accadere, di tanto in tanto, che sia un isolato genio scientifico a dare l'impulso; più spesso si tratta invece di ‛impresari scientifici' che fanno chiasso per scopi di lucro: è difficile dire se siano costoro a creare le mode o se essi seguano semplicemente le correnti originatesi in qualche zona sconosciuta della mentalità scientifica collettiva. Nello sviluppo delle scienze in un determinato periodo storico vi è pur sempre uno stile, e cioè un modo caratteristico di fare e di considerare le cose: non vi è alcun dubbio che subito dopo la morte di Miescher vi fu un mutamento di stile. Credo che l'attenta lettura di alcune pubblicazioni e delle lettere di Miescher potrà mostrare come egli fosse tutt'altro che inconsapevole dell'importanza della propria scoperta, benché non potesse certo prevedere la posizione dominante che essa avrebbe avuto in futuro. Però, subito dopo, fu proprio quel mutamento di stile che ho prima citato a rendere quasi inaccettabile agli scienziati l'esistenza di molecole giganti. Infatti, il concetto di macromolecola poté essere preso seriamente in considerazione soltanto cinquant'anni dopo. Questa paralisi può ben essere stata causata proprio dai successi clamorosi conseguiti dalla chimica organica nel determinare la struttura e nell'effettuare la sintesi di molecole relativamente piccole.
L'insistenza ad applicare la mentalità stechiometrica, acquisita manipolando composti relativamente semplici, anche alle forme molto più complesse che si ritrovano nella cellula, caratterizza tutti i successivi tentativi di determinare la struttura degli acidi nucleici. Per lungo tempo, soprattutto a causa della mancanza di metodi discriminanti specifici, si credette che il DNA fosse tipico dei tessuti animali e l'RNA delle cellule vegetali e microbiche. Tuttavia, appena furono disponibili metodi adeguati, tale errore fu corretto, ed ora sappiamo che entrambi gli acidi nucleici sono presenti in tutte le cellule viventi, ad eccezione di organismi parassiti come i virus ed i batteriofagi, che ne contengono solo uno, il DNA oppure l'RNA.
Un'altra eccessiva semplificazione fu, invece, molto più difficile da superare ed ebbe conseguenze dannose per il progresso delle nostre conoscenze. Si tratta della cosiddetta ‛teoria del tetranucleotide'. L'argomentazione che condusse alla formulazione ditale teoria era pressappoco la seguente: quando si ha a che fare con una sostanza organica semplice, come ad esempio il disaccaride saccarosio, della quale siano noti la formula (C12H22O11) ed il peso molecolare (342), possiamo concludere che tale sostanza, idrolizzata, darà luogo a due esosi. Infatti, nell'esempio citato, possiamo identificare i due esosi come glucosio e fruttosio. Senza tener conto della rispettiva resa di questi due zuccheri nel nostro esperimento, possiamo ragionevolmente supporre che essi siano presenti in eguali proporzioni nel disaccaride. Analogamente, si sapeva che il DNA e l'RNA contenevano ciascuno quattro diverse sostanze azotate (v. tab. I) e che tali sostanze, come si dimostrò in seguito, si presentavano negli acidi nucleici sotto forma di nucleotidi (v. sopra, cap. 5). Quindi se ne concluse, senza alcuna reale giustificazione, che le due purine e le due pirimidine esistevano negli acidi nucleici come ‛tetranucleotidi'. Se abbreviamo i quattro principali costituenti del DNA con A, G, C e T, la struttura avrebbe potuto essere indicata come (AGCT)n. Si suppose che il termine n fosse molto piccolo, anche se forse non si era molto riflettuto su questo punto. Inoltre, poiché nessuno poteva neanche lontanamente sospettare che l'acido nucleico potesse essere l'agente di una forma di comunicazione non verbale, cioè di ‛informazione biologica', non fu affatto presa in considerazione la possibilità che esistesse una specificità sequenziale perfino in un ‛tetranucleotide statistico', per quanto relativamente piccolo. Altrimenti, si sarebbe potuto osservare che anche una struttura piccola come un octanucleotide (AGCT)2 può esistere, per permutazione, in ben 2.520 sequenze diverse. Comunque, ciò che ho prima definito lo ‛stile' di quel periodo non consentiva questo genere di speculazioni: i tempi non erano ancora maturi.
Come avviene di solito nella scienza, il mutamento fu improvviso. Tuttavia la disponibilità ad accogliere proposte rivoluzionarie fu preceduta da un cambiamento graduale del clima scientifico; ma anche questo è un processo comune nella storia delle scienze. Anzitutto, era necessario che chimici e biologi fossero pronti ad accettare l'esistenza in natura di molecole gigantesche: ciò fu il risultato del lavoro di molti scienziati, forse soprattutto dei lavori di Svedberg e di Staudinger. Ci si rese conto del grandissimo peso molecolare delle proteine e di alcuni polimeri sintetici; si apprese che esistevano molte proteine differenti l'una dall'altra per forma, dimensioni e composizione in amminoacidi. In questo contesto non si può sottovalutare l'importanza dei contributi pionieristici dell'immunologia.
Finalmente, nel febbraio del 1944, apparve sul ‟Journal of experimental medicine" un articolo di O. T. Avery, C. M. MacLeod e M. McCarty intitolato Studies on the chemical nature of the substance inducing transformation of pneumococcal types. Induction of transformation by a desoxyribonucleic acid fraction isolated from Pneumococcus type III. L'articolo termina con una conclusione di una sola frase: ‟La prova che abbiamo qui presentato accredita l'ipotesi che un acido nucleico del tipo con desossiribosio sia l'unità fondamentale dell'agente trasformante dello pneumococco tipo III".
Sarebbe stato veramente difficile poter dire di più in così poche parole: benché a quel tempo non fossero in molti a rendersene conto, la scoperta di Avery stabiliva la natura chimica dei geni, o almeno di alcuni geni. Si dimostrava che quando una preparazione di DNA di pneumococco veniva assunta da un'altra variante della stessa specie microbica, detta variante si trasformava ‛in modo ereditariamente trasmissibile', dando origine a una discendenza capace di compiere alcune reazioni di sintesi caratteristiche della variante da cui era stato estratto il DNA trasformante.
Chi scrive fu tra i pochi che compresero l'importanza della precedente osservazione; si potrebbe dire che noi stessi fummo trasformati dall'identificazione del principio trasformante.
La storia non spiega mai come siano andate veramente le cose, ma come a noi sembra che siano andate. La falsificazione di quel particolare capitolo della storia delle scienze che riguarda la scoperta di Avery ebbe inizio subito dopo questa, quando un gruppo di ‛impresari scientifici' cominciò a sfruttare ciò che prima aveva ignorato o criticato. Vi sono pochi casi in cui l'impudenza della nostra attuale élite scientifica risulti così evidente come nella storia di questa scoperta. A tal proposito bisogna ricordare che Oswald Avery condivide con David Keilin e pochi altri grandi scienziati del passato l'onore di non aver ricevuto il premio Nobel.
In ogni caso, quella classica pubblicazione mi convinse che vi dovevano essere differenze chimiche tra preparazioni di DNA di differente origine cellulare. Così, ci dedicammo a mettere a punto metodi per l'analisi chimica e la caratterizzazione degli acidi nucleici; tale compito non sarebbe mai stato portato a termine senza la spettrofotometria nell'ultravioletto e la cromatografia su carta. Preparammo campioni di DNA e di RNA estratti da un gran numero di tipi diversi di cellule, mentre andavamo elaborando metodi idonei a idrolizzare gli acidi nucleici ed a separare e dosare i loro costituenti essenziali, le purine e le pirimidine, anche in quantità piccolissime. Questo lavoro fu svolto in collaborazione con molti eminenti colleghi, tra i quali in primo luogo Ernst Vischer, che proveniva anche lui da Basilea, la città natale di Miescher. Nel 1949 concludemmo questa fase del nostro lavoro e le conclusioni furono tratte in una rassegna che pubblicai nel 1950 sulla rivista svizzera ‟Experientia". Si dimostrava che la vecchia formulazione degli acidi nucleici come tetranucleotidi statistici, che aveva imperato per 40 anni, era completamente infondata. Riportiamo qui qualche brano di quell'articolo, che ne chiarisce lo scopo e le conclusioni.
‟Iniziammo il nostro lavoro a partire dall'ipotesi che gli acidi nucleici fossero grandi polimeri complicati e intricati, paragonabili in ciò alle proteine, e che la determinazione della loro struttura e delle eventuali varietà strutturali avrebbe richiesto lo sviluppo di metodi idonei per l'analisi accurata di tutti i costituenti degli acidi nucleici preparati da un grande numero di tipi differenti di cellule.
Gli acidi desossipentosonucleici isolati da cellule animali e microbiche presentano proporzioni variabili degli stessi quattro costituenti azotati, cioè adenina, guanina, citosina e timina. La loro composizione è caratteristica della specie da cui derivano, ma non del tessuto. Se ne può dedurre quindi che vi è un numero enorme di acidi nucleici strutturalmente diversi, numero certamente maggiore di quello che gli attuali metodi analitici consentano di rilevare. [...] Gli acidi desossipentosonucleici provenienti da specie diverse differiscono in composizione chimica, come ho prima dimostrato, e ritengo che non vi siano valide obiezioni all'affermazione secondo cui, a quanto ci è possibile giudicare dalla struttura chimica, tali acidi possano ben essere uno degli agenti, se non addirittura l'agente responsabile della trasmissione dei caratteri ereditari. Sarebbe una bella cosa se si potesse dire - ma per ora si tratta solo di un'ipotesi senza fondamento sperimentale - che, così come gli acidi dessossipentosonucleici del nucleo sono specie-specifici e sono implicati nel mantenimento della specie, allo stesso modo gli acidi pentosonucleici del citoplasma sono organo-specifici e responsabili dell'importante compito della differenziazione" (v. Chargaff, 1950).
I nostri esperimenti, quindi, mostravano che la vecchia ipotesi del tetranucleotide era sbagliata e che esisteva un grandissimo numero di acidi desossiribonucleici diversi, la cui composizione era costante e caratteristica nell'ambito di una specie e di tutti gli organi di una stessa specie. In altre parole, tali esperimenti mostravano che le differenti varietà di DNA si distinguevano l'una dall'altra, come nel caso delle proteine, per la differente disposizione dei loro costituenti, cioè per le differenti sequenze dei nucleotidi. A rigor di termini, questa fu l'origine del concetto, ora accettato comunemente, di ‛contenuto di informazioni' del DNA.
La molecola di DNA non poteva più essere schematizzata, mantenendo le abbreviazioni precedenti, come (AGCT)n, bensì come (AmGnCoTp) e si doveva ammettere che gli indici m, n, o, p rappresentassero numeri non solo molto grandi bensì caratteristicamente diversi in preparazioni di DNA ottenute da specie diverse. Questo fatto pose per la prima volta gli acidi nucleici sullo stesso piano delle proteine.
Nello stesso periodo fu osservata un'altra cosa, ancor più sorprendente, perché del tutto inaspettata, che distingueva gli acidi nucleici dalle proteine, e che consisteva in una specie di equilibrio tra i vari componenti del DNA, mai prima osservato in altri polimeri naturali. Si tratta della complementarità tra adenina e timina da una parte e tra guanina e citosina dall'altra, ora comunemente indicata come ‛appaiamento delle basi'.
Queste regolarità, che resi note in parecchi articoli pubblicati fra il 1948 e il 1950, erano le seguenti: se si indica la formula generale del DNA come scritto sopra, e cioè (AmGnCoTp), troviamo che in molte specie di DNA a differente composizione e con differenti valori di m, n, o e p i numeri m e p sono sempre eguali fra loro, così come i numeri n ed o. Inoltre, le somme (m + n) e (o + p) sono eguali, così come lo sono (m + o) ed (n + p). Esprimendo ciò in parole, troviamo che i costituenti del DNA devono essere appaiati nel modo seguente: a) l'adenina (5) con la timina (8); b) la guanina (6b) con la citosina (7); c) le purine con le pirimidine; d) i costituenti chimicamente definibili come 6-amminoderivati (adenina e citosina) con i 6-cheto-derivati (guanina e timina).
Sulla base di queste scoperte fatte nel mio laboratorio e delle indagini mediante raggi X sulla struttura del DNA condotte da Wilkins a Londra, Watson e Crick formularono nel 1953 l'interessante ipotesi sull'architettura macromolecolare del DNA, cioè la sua struttura secondaria. Questo modello propone una doppia elica formata da due catene di DNA intrecciate, tenute insieme da specifici legami a idrogeno, cioè quegli stessi legami previsti dal principio dell'appaiamento delle basi citato prima. Il modello a doppia elica del DNA suggerì immediatamente un possibile meccanismo mediante il quale la cellula può effettuare la duplicazione di una molecola di DNA conservandone l'informazione biologica intrinseca, che è fondata sulla sua particolare sequenza di nucleotidi. La primitiva catena A forma la nuova catena B e la primitiva catena B forma la nuova catena A; il positivo forma il negativo, il negativo forma il positivo e così via, usque ad resurrectionem carnis. La grande ingegnosità del modello sembra aver paralizzato tutte le menti su questo problema ed ogni ulteriore sviluppo è stato epigonico, mentre il centro di interesse si è spostato su altri aspetti della genetica biochimica.
Il lettore sarà forse sorpreso dalla semplicità di questo schema per conservare la stabilità biologica del mondo vivente. In verità, se il mondo fosse stato creato da Rousseau, il Doganiere, non avrebbe potutò essere più primitivo; ma è questo il mondo? Potrebbe darsi che l'appaiamento delle basi, pur essendo di fatto uno degli elementi fondamentali dei processi vitali, non sia probabilmente nulla più che una semplice copula nell'imperscrutabile libro della vita. Non si dovrebbe mai perdere di vista il fatto che un singolo componente - come può essere un ingranaggio o un transistore - di un meccanismo molto complesso (ammesso che ‛meccanismo' sia la parola giusta) non può riflettere la complessità dell'insieme. Tutto ciò sarà risolto in avvenire; ma nel frattempo il monotono ripetersi dello stesso ritornello sul cilindro dell'organino della biologia molecolare ha avuto un effetto ipnotico su tutta la biologia.
Mentre procedeva tutto questo lavoro sul DNA, la conoscenza dell'RNA restava relativamente ferma, salvo lo sviluppo dei metodi analitici. Si sapeva da qualche tempo che le preparazioni di RNA da animali, piante o cellule microbiche erano molto meno omogenee per composizione e proprietà fisiche rispetto al DNA. Bisogna tuttavia ricordare che fin dal 1936 Bawden e Pirie avevano scoperto che il virus del mosaico del tabacco era una nucleoproteina, la cui parte prostetica si dimostrò in seguito essere una specie di RNA dotata di attività biologica.
Molte importanti ricerche sull'RNA furono compiute nel decennio successivo alla scoperta della struttura del DNA. In primo luogo si stabilì definitivamente, grazie soprattutto ai lavori di A. R. Todd e dei suoi collaboratori, che la struttura portante degli acidi nucleici (RNA e DNA) consisteva effettivamente, come già supposto, in una catena di nucleotidi uniti l'uno all'altro da ponti fosforici ripetuti regolarmente tra le posizioni 3′ e 5′ di due zuccheri contigui. Torneremo in seguito a considerare questo fatto.
Tuttavia, i progressi più importanti riguardavano il problema della trasmissione dell'informazione biologica. Se vogliamo accettare il principio che le caratteristiche ereditane della cellula siano racchiuse in un ‛codice' rappresentato da una specifica sequenza di nucleotidi in una catena di DNA, il modello a doppia elica del DNA può spiegare come l'informazione genetica sia conservata. Ma come viene trasmessa? In che modo le informazioni contenute presumibilmente nella catena di DNA - e cioè ‟Fa questo... non fare quello...", ecc. - sono ritrasmesse al resto della cellula e dell'organismo? Questa trasmissione, a quanto pare, fa parte dei compiti assegnati oggi all'RNA.
Il primo anello di una catena di prove fu la scoperta di sistemi enzimatici (RNA-polimerasi), di cui si dirà in seguito, che, utilizzando il DNA come stampo obbligato, sintetizzano molecole di RNA di composizione e sequenza complementari. In altri termini, il DNA serve come stampo sia per la propria ‛replicazione' (mediante le DNA-polimerasi), sia per la propria ‛trascrizione' (mediante le RNA-polimerasi). Le molecole di RNA, tutte presumibilmente derivate da tali processi di trascrizione, appartengono a parecchie classi differenti. Vi si trovano, tra l'altro, le specie, a peso molecolare relativamente alto, di RNA ribosomiale, le piccole molecole di RNA solubile (o transfer) presenti in almeno un tipo diverso per ogni amminoacido costituente le proteine, ed infine un grandissimo numero di mal definite ed evanescenti molecole dette ‛RNA messaggero', che si crede siano gli agenti diretti della ripetizione delle istruzioni derivanti dal DNA. L'RNA messaggero specifica ai ribosomi, dove avviene la sintesi delle proteine, la struttura di enzimi e di altre proteine. Si pensa che ciascuno di questi messaggeri porti l'indicazione di almeno una proteina, letta su di una sezione di DNA del genoma. L'acido ribonucleico dei virus delle piante e di certi batteriofagi contiene presumibilmente messaggi riguardanti parecchie proteine, la cui sintesi è indotta dall'infezione.
Infine, è stato possibile dimostrare, con grado di certezza variabile, che una molecola di RNA messaggero può essere considerata come formata da una serie di ribotrinucleotidi e che ognuna di queste ‛triplette' rappresenta la parola in codice per un dato amminoacido.
Questa breve rassegna ci ha condotto, più o meno, allo stato attuale delle conoscenze in tale campo. Il resto dell'articolo sarà rivolto ad illustrare la chimica degli acidi nucleici ed i modi in cui essi sono sintetizzati e demoliti all'interno della cellula.
7. Nucleoproteine e chimica generale degli acidi nucleici
a) Nucleoproteine
Dal momento che gli acidi nucleici sono poliesteri dell'acido fosforico, essi sono acidi forti e dovrebbero trovarsi nelle cellule in combinazione con opportuni cationi, come sali di metalli o di altri composti basici. La maggior parte delle molecole di acidi nucleici, però, si trova nelle cellule, ed anche nei virus, in combinazione con proteine, sotto forma di nucleoproteine. In qualche caso queste nucleoproteine si possono considerare unite insieme, almeno in parte, con legami elettrostatici; possono essere cioè considerate come sali dell'acido nucleico con proteine cariche positivamente; in molti casi sono probabilmente tenute insieme da forze di valenza secondarie, come legami a idrogeno o idrofobici; nella maggioranza dei casi sono presenti, forse, entrambi i tipi di legame.
Il DNA si trova spesso associato a proteine basiche: ad esempio nello sperma di pesce con le protammine, nel timo e in molte altre cellule mature con gli istoni, di cui esistono diverse specie in uno stesso nucleo cellulare. Si è spesso pensato che queste proteine possano esercitare uno specifico effetto regolatore sui limiti della trascrizione del DNA. Ciò è possibile ma non è stato definitivamente provato, poiché gli esperimenti che lo proverebbero, effettuati in vitro, sono molto lontani dalla reale situazione della cellula vivente. Inoltre, molte desossiribonucleoproteine devono essere considerate nucleoproteine coniugate di ordine superiore, in quanto formate da proteine molto più complesse delle protammine e degli istoni, e non è possibile ancora stabilire quali tipi di legame uniscano la parte proteica all'acido nucleico. In questo caso deve essere importante la struttura terziaria di entrambi i componenti e deve esistere un numero grandissimo di forme diverse. È molto probabile che i vari virus e batteriofagi contenenti DNA appartengano a quest'ultimo tipo.
Nel gruppo delle ribonucleoproteine, rappresentato, ad esempio, dai ribosomi, da porzioni del nucleolo e da molti virus animali, delle piante e batterici, l'associazione con proteine basiche sembra avere un ruolo molto meno importante.
La separazione del DNA da una nucleoprotammina o da un nucleoistone può avvenire per dissociazione della proteina coniugata ad alta concentrazione salina, seguita dalla precipitazione del DNA; di più generale utilità è l'impiego di un agente capace di denaturare la parte proteica, come il detergente dodecilsolfato di sodio o il fenolo. Il secondo metodo si usa anche per separare l'acido ribonucleico.
b) Chimica generale
Ciò che tutti gli acidi nucleici hanno in comune è l'essere composti ad alto peso molecolare, idrosolubili e ad alta carica negativa. Essi contengono quantità equimolari di basi azotate, zuccheri e fosfato: sono quindi meglio classificabili come polimeri di nucleotidi, cioè polinucleotidi.
Secondo la formulazione attuale, fondata su prove convincenti, si ritiene che in tutti gli acidi nucleici i nucleotidi siano uniti l'un l'altro da ponti fosforici tra l'idrossile 5′ di un nucleoside e l'idrossile 3′ di quello adiacente, in modo da formare lunghissime catene nucleotidiche.
In teoria tali catene potrebbero terminare con un radicale fosforico primario in posizione 5′ o 3′, oppure, unendosi le due estremità 5′ e 3′ con un ponte fosforico, esse potrebbero formare dei cerchi. Ciò accade effettivamente in alcuni DNA di piccole specie, per esempio in diversi piccoli fagi di Escherichia coli, ma anche in alcuni DNA presenti nel citoplasma di cellule animali, come il DNA mitocondriale.
Gli acidi nucleici e le proteine, quindi, si somigliano per il fatto di essere alti polimeri, di nucleotidi in un caso e di amminoacidi nell'altro. Vi è però un'importante differenza: le proteine sono formate da una sola specie di molecole, e cioè gli amminoacidi, mentre gli acidi nucleici ne comprendono tre e cioè purine o pirimidine, zuccheri e acido fosforico. Se indichiamo con a gli amminoacidi costituenti una proteina ed i costituenti degli acidi nucleici con b (base azotata), z (zucchero) ed f (acido fosforico), possiamo schematizzare una proteina come
− a1 − a2 − a3 − a4 −
e un acido nucleico come

Ne risulta chiaramente che un acido nucleico è formato da un filamento sempre eguale di zucchero e acido fosforico alternati, cui è sovrimposta una sequenza variabile di purine e pirimidine che potrebbe essere modificata, almeno teoricamente, senza distruggere il filamento, il che è inconcepibile nel caso delle proteine.
8. Acidi desossiribonucleici
a) Composizione del DNA e illustrazione del principio di appaiamento delle basi
Nelle tabb. II e III riportiamo una scelta di valori riguardanti la composizione in purine e pirimidine di campioni di DNA estratti, rispettivamente, da un'ampia varietà di microrganismi e di piante e animali. Molti esempi derivano da miei esperimenti e servono a precisare parecchi punti.
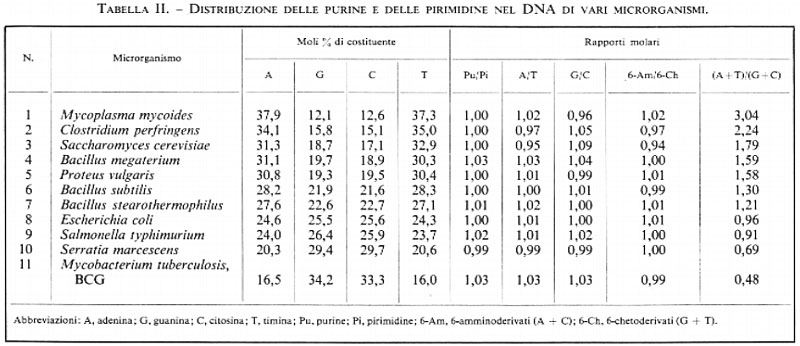
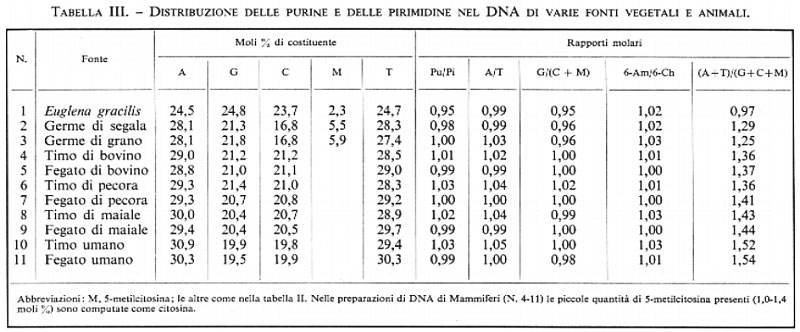
1. Le sopra menzionate regole di appaiamento delle basi ne vengono fuori chiaramente: l'adenina è pari alla timina; la guanina è pari alla citosina; le purine sono pari alle pirimidine; il numero dei 6-amminoderivati (adenina+citosina) è pari a quello dei 6-chetoderivati (guanina+timina).
2. Mentre i rapporti molari secondo il principio dell'accoppiamento delle basi sono sempre prossimi all'unità, il rapporto fra adenina+timina e guanina+citosina, e cioè il cosiddetto rapporto di dissimmetria, varia ampiamente nelle varie specie di DNA. Specialmente i microrganismi mostrano un campo di variabilità molto ampio nella composizione: il rapporto di dissimmetria varia, infatti, fra 3 e 0,5. È possibile, quindi, distinguere molecole di DNA di tipo AT (numeri 1-7 nella tab. II), di tipo GC (numeri 10 e 11) e di tipi intermedi con distribuzione quasi equimolare dei nucleotidi (numeri 8 e 9). Queste grandi differenze nella composizione indicano che vi sono grandi differenze nella sequenza dei nucleotidi nei diversi acidi nucleici e, potenzialmente, grandi differenze nel loro presumibile contenuto di informazioni.
3. Per le cellule superiori, vegetali e animali, le differenze nella composizione sono meno spiccate, poiché esse hanno tutte acidi nucleici del tipo AT (numeri 2-11 nella tab. III) ad eccezione dei Protozoi (numero 1 nella tab. III).
4. Nel DNA batterico le basi puriniche e pirimidiniche meno comuni sono scarsamente rappresentate, mentre, specialmente nel DNA delle piante, si trovano notevoli quantità di un quinto componente, la 5-metilcitosina (numeri 2 e 3 nella tab. III): minori quantità se ne trovano anche nel DNA di Mammiferi.
5. Nel DNA di Mammiferi, ovunque sia possibile fare dei confronti, non si riscontrano differenze nella composizione per le preparazioni estratte da differenti organi della stessa specie (numeri 4 e 5 nella tab. III). Vi è invece una differenza, piccola ma statisticamente significativa, tra specie diverse (confrontare, nella tab. III, i numeri 4 e 5 con i numeri 10 e 11).
6. Le coppie di basi si costituiscono tra una 6-amminopurina (adenina) e una 6-chetopirimidina (timina) e tra una 6-chetopurina (guanina) e una 6-amminopirimidina (citosina). Per tale ragione, nel DNA delle piante, in cui come componente importante vi è una seconda 6-amminopirimidina (la 5-metilcitosina), bisogna considerare la somma citosina + 5-metilcitosina per ristabilire le regole dell'accoppiamento delle basi.
Solo gli acidi desossiribonucleici di parecchi batteriofagi mostrano anomalie. Nel DNA dei fagi T2, T4 e T6 dell'Escherichia coli non si trova la citosina, che è rimpiazzata completamente dalla 5-idrossimetilcitosina; in altri fagi si trova l'idrossimetiluracile. Tutti questi DNA seguono, tuttavia, le regole dell'accoppiamento delle basi, mentre ciò non avviene nel DNA di molti piccoli fagi di Escherichia coli come i ΦX-174, fl, fd, eccetera, nei quali le regolarità sopra menzionate sono assenti. È stato riconosciuto che questi tipi di DNA, in effetti, si presentano sempre come catene circolari a filamento unico.
b) Struttura e proprietà fisiche
Nel precedente cap. 6 abbiamo già menzionato la struttura proposta da Watson e Crick, secondo la quale il DNA è formato da due catene polinucleotidiche intrecciate e tenute insieme dalle coppie di basi in modo tale da formare una doppia elica. Il diagramma originale di questo modello è riportato nella fig. 2. Il modello delle singole coppie di basi adenina-timina e guanina-citosina è riportato nella fig. 3. Questo modello ha avuto grande influenza sull'ulteriore sviluppo della biochimica, della biofisica e della genetica. Tali scienze, unitamente alla microbiologia e alla virologia, sono oggi comprese nella nuova denominazione collettiva di biologia molecolare (v. biologia molecolare).
Il peso molecolare calcolato per differenti campioni intatti di DNA varia da un valore di pochi milioni a valori di centinaia e perfino di migliaia di milioni. Una molecola di DNA di peso molecolare pari a 900 milioni, ad esempio, contiene 3 • 106 nucleotidi; ciò significa che ciascuna delle due catene di tale composto presenterebbe addirittura 1,5 milioni di nucleotidi. Si tratterebbe di una lunghissima e sottilissima doppia struttura, la cui integrità dovrebbe, 0vviamente, essere molto sensibile alle forze idrodinamiche. Si può effettivamente osservare che le preparazioni di DNA si spezzano facilmente per effetto di forze di stiramento, dando luogo ad una varietà di strutture a doppia elica più corte. Ciò rende estremamente difficile l'isolamento di preparazioni di DNA intatto con peso molecolare maggiore di 150 • 106.
Può sembrare strano che lo stiramento idrodinamico possa rompere i legami esterei del fosforo, che sono relativamente forti e che tengono insieme la struttura primaria di un polinucleotide, senza con ciò alterare la struttura secondaria, cioè le coppie di basi unite da legami a idrogeno tra le due catene complementari. Questa differenza di comportamento non è assoluta: la separazione delle catene si può in effetti verificare in soluzioni prive di elettroliti; ma non bisogna dimenticare che la doppia elica è mantenuta da un numero enorme di coppie di basi in cooperazione, come nel meccanismo di una chiusura lampo. È il grande numero di forze deboli, ma cooperative, che mantiene l'architettura generale.
Tuttavia, esistono diversi modi di effettuare la denaturazione di una molecola di DNA, fenomeno che consiste nella separazione parziale o completa delle due catene. Gli agenti che vengono impiegati a tale scopo sono il calore o un pH alcalino. La possibilità di denaturare il DNA fu, in realtà, scoperta prima della formulazione del modello strutturale, con l'osservazione dell'effetto ipercromico, cioè un aumento di circa il 40% dell'assorbimento nell'ultravioletto, che si accompagna alla separazione delle catene. Questi metodi spettroscopici sono stati molto utili nello studio degli acidi nucleici, come anche utili sono state le tecniche di centrifugazione comportanti la sedimentazione, ad alta velocità, in mezzi ad elevata densità (soluzioni di cloruro di cesio o gradienti di densità ottenuti con saccarosio). Queste ed altre procedure sono state impiegate anche per studiare l'effetto opposto, cioè la rinaturazione, che consiste nella riassociazione di due singole catene di DNA che abbiano sequenze complementari.
c) Prodotti di degradazione parziale e studio della sequenza dei nucleotidi
Anche una molecola di DNA relativamente piccola, ad esempio di peso molecolare 24 • 106, contiene in ciascuna catena 40.000 nucleotidi. I metodi usuali di analisi sequenziale, come quelli impiegati per le proteine o per piccole molecole di RNA, non possono essere ancora applicati a tali catene ciclopiche. Ci si deve accontentare di considerazioni statistiche e di studiare la tendenza di certi nucleotidi a disporsi l'uno adiacente all'altro. In studi di questo tipo è stato di grande aiuto il poter disporre di prodotti di degradazione parziale del DNA. Poiché il legame glicosidico tra zucchero e purina è molto più debole di quello tra zucchero e pirimidina, è stato relativamente facile rimuovere le purine da una catena di DNA in ambiente acido e preparare l'acido apurinico, che è un prodotto di degradazione di un DNA in cui i nucleotidi pirimidinici occupano ancora le loro posizioni originali, mentre residui di zuccheri fosfati contrassegnano le posizioni dalle quali sono state allontanate le purine. Un prodotto analogo è l'acido apirimidinico, che ha le purine ma che è stato privato delle pirimidine per azione dell'idrazina. La fig. 4 mostra questi schemi di degradazione parziale. È quindi possibile studiare in tal modo una preparazione di DNA e raccogliere da una parte tutti i raggruppamenti pirimidinici o isostichi pirimidinici e dall'altra parte tutti gli isostichi purinici. La discussione dettagliata di questi studi ci condurrebbe però troppo lontano.
9. Acidi ribonucleici
a) I vari tipi di RNA nelle cellule
La maggior parte delle prime ricerche sulla composizione chimica e sulle proprietà dell'RNA deve essere scartata, poiché allora non ci si rendeva conto dell'esistenza nelle cellule di parecchi tipi di RNA che sono differenti sia funzionalmente sia chimicamente e fisicamente. Inoltre, l'acido ribonucleico si trova in molte zone differenti della cellula: più del 10% di tutta la quantità di RNA presente nella cellula si trova nel nucleo, più del 50% nei ribosomi, circa il 15% nei mitocondri ed il rimanente nella parte non strutturata del citoplasma, nel ‛citosol'. È opportuno distinguere tre tipi principali di RNA: a) il ribosomiale (rRNA); b) il messaggero (mRNA); c) il transfer (o di trasferimento, tRNA).
Da tempo si sospettava, ed in seguito fu provato, che l'acido ribonucleico si forma nella cellula mediante trascrizione enzimatica del DNA che funge da stampo. In considerazione del fatto che il DNA di specie differenti varia grandemente in composizione, si cercò ovviamente di trovare correlazioni tra RNA e DNA di una data specie. Questo tentativo non fu particolarmente fruttuoso, e ciò non sorprende in quanto molecole funzionalmente differenti di RNA leggono settori differenti del genoma a velocità differenti e, per di più, sopravvivono nella cellula per differenti periodi. Inoltre, esistono adesso convincenti indizi che solo una delle due catene del DNA viene trascritta, benché non obbligatoriamente sempre la stessa. Bisogna anche ricordare che l'acido ribonucleico ribosomiale rappresenta oltre metà di tutto l'acido ribonucleico nella cellula; cionostante, a giudicare dal numero di nucleotidi che contiene, non può rappresentare che un'esigua frazione della sequenza di nucleotidi del DNA nel genoma.
b) RNA ribosomiale
Si può affermare, in generale, che i ribosomi contengono due classi di RNA ribosomiale (rRNA): una classe ha un peso molecolare variabile da 1 ad 1,5 milioni, mentre l'altra, più leggera, ha peso molecolare pari a circa la metà di quello della prima classe.
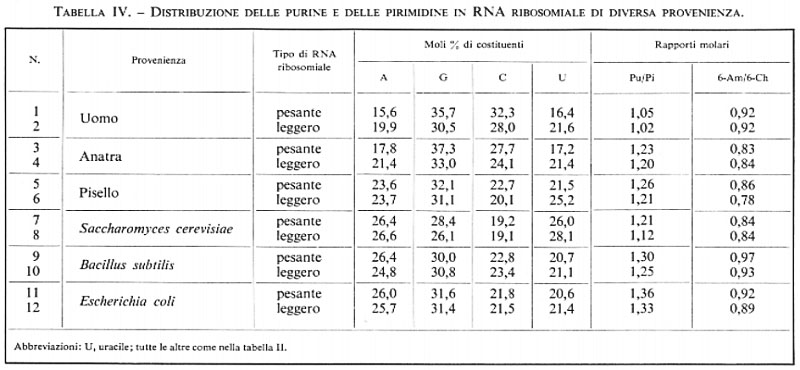
La tab. IV presenta una significativa scelta di dati sulla composizione di ciascuna delle due classi suddette negli animali, nelle piante e nei microrganismi; si può constatare che non vi è relazione tra questi tipi di rRNA e il DNA in un medesimo organismo. Non si riscontrano regolarità connesse all'appaiamento delle basi, come nel caso del DNA, neppure nel rapporto fra purine e pirimidine, che risulta quasi sempre molto maggiore dell'unità. Il più importante composto azotato è la guanina, seguito, nella maggior parte dei casi, dalla citosina. Una certa rassomiglianza può essere riconosciuta, invece, tra le due classi di rRNA all'interno di una stessa specie.
c) RNA messaggero
Di questo gruppo si può dire ben poco di preciso oltre al fatto che l'attuale teoria del meccanismo di biosintesi delle proteine richiede la sua esistenza. Sembra che molti tipi di mRNA abbiano in vivo una vita brevissima, mentre altri durerebbero più a lungo. Il loro compito, che è quello di indicare ai ribosomi gli opportuni amminoacidi da scegliere per la sintesi di una data proteina, può essere simulato in vitro da alcuni polinucleotidi sintetici, come l'acido poliuridilico.
La quantità di RNA messaggero rispetto a tutto l'RNA di una cellula è probabilmente molto piccola: di poche unità per cento; l'mRNA deve però comprendere un grandissimo numero di molecole chimicamente differenti, forse pari o addirittura superiore al numero delle differenti proteine cellulari. È quindi un compito quasi impossibile quello di isolare una singola specie da una popolazione così vasta, per quanto si sia già tentato di realizzarlo mediante l'impiego di colture batteriche in crescita sincrona. Gli esperimenti più promettenti sono stati compiuti con cellule specializzate che sintetizzano quasi esclusivamente una sola proteina: in tal modo si è purificato parzialmente l'acido ribonucleico messaggero dell'emoglobina e quello della fibroina della seta.
d) Il codice genetico
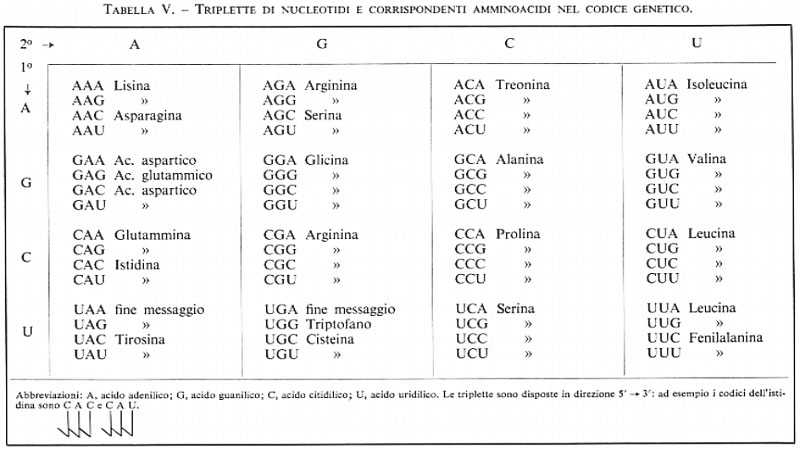
Tralasciamo in questa sede i meccanismi di sintesi delle proteine (v. biologia), ma, dal momento che gli acidi nucleici sono connessi così strettamente con questo processo, non possiamo ignorarlo completamente. Secondo i concetti attuali i vari geni, o sequenze di geni, sono rappresentati, sulla catena del DNA, da una serie di nucleotidi che sono trascritti in forma di molecole di RNA messaggero per mezzo della RNA-polimerasi. Questi RNA messaggeri portano l'informazione biologica ai ribosomi, dove ha luogo il montaggio specifico degli amminoacidi per formare le proteine. Il ruolo svolto dall'RNA ribosomiale in questo processo è ancora in gran parte sconosciuto. Ma la scoperta di come l'RNA-messaggero, nel quale sono state trascritte le istruzioni contenute nel DNA, possa tradurre queste nella specifica sequenza di amminoacidi di una proteina, è certamente una delle più sorprendenti di questi ultimi anni; le ricerche basilari furono condotte da M. W. Nirenberg. Secondo le vedute attuali, il contenuto di informazione biologica di una molecola di mRNA è basato sulla sequenza di triplette nucleotidiche, cioè la sequenza di triribonucleotidi, ciascuna delle quali rappresenta il codice di un amminoacido. Si pensa che il codice sia ‛degenerato', e cioè che vi sia più di una sola parola in codice per ciascun amminoacido. Inoltre, il terzo nucleotide della maggior parte delle triplette sembra essere meno importante dei primi due. Delle 64 possibili triplette, 61 corrispondono ad amminoacidi, mentre le altre tre servono come segnale della fine di un polipeptide. Nella tab. V è riportato il codice attualmente noto, basato principalmente su ricerche effettuate con Escherichia coli.
e) RNA transfer
Affinché uno specifico amminoacido sia inserito in una specifica posizione di una catena polipeptidica in accrescimento, che viene sintetizzata dal complesso ‛ribosoma-mRNA', esso deve essere riconosciuto, attivato, trasportato e sistemato al suo posto. Oltre a vari enzimi e cofattori, l'agente principale è una molecola di RNA transfer, di cui devono esistere nella cellula almeno tanti tipi diversi quanti sono i diversi amminoacidi che formano una proteina.
Nel recente passato sono stati isolati moltissimi tipi di tRNA, ciascuno specifico per un singolo amminoacido; qualcuno è stato ottenuto allo stato cristallino e di pochissimi è nota tutta la sequenza di nucleotidi. Essi hanno tutti basso peso molecolare, circa 25.000, e contano circa 80 nucleotidi. Al contrario della maggior parte degli acidi nucleici, il tRNA contiene notevoli quantità di composti azotati atipici: purine e pirimidine modificate o sostituite, come metilderivati, pseudouridina, diidrouracile, ipoxantina, ecc. Tutti i tipi di tRNA hanno molte caratteristiche in comune: il nucleotide terminale della parte dove si trova l'acido fosforico monoesterificato è sempre l'acido guanilico; l'altra estremità termina con l'acido adenilico, al cui idrossile in posizione 2′ o 3′ si lega, con legame estereo, l'amminoacido attivato. A causa della presenza di molte regioni capaci di formare accoppiamenti di basi, i tRNA mostrano strutture specifiche dette ‛a trifoglio'. Una delle anse intercalate tra segmenti a doppia elica porta l'‛anticodon' (o anticodice), e cioè una tripletta complementare a quella che corrisponde ad un particolare amminoacido. Ad esempio l'anticodice di uno dei codici per la fenilalanina (UUU, v. tab. V), sarebbe AAA. È proprio attraverso tali interazioni tra tRNA ed mRNA che si raggiunge il corretto inserimento di ogni amminoacido nella catena polipeptidica in accrescimento. D'altra parte, la mutazione di una sola base nel DNA può provocare la sostituzione di un amminoacido con un altro nella proteina.
10. Enzimi che intervengono nella biosintesi degli acidi nucleici
a) Biosintesi dei ribonucleotidi
Gli immediati precursori dell'RNA e del DNA sono, molto probabilmente, i nucleosidi 5′-trifosfati. Furono necessari molta ingegnosità e un tenace lavoro per arrivare a chiarire i meccanismi con cui la cellula li sintetizza.
Esperimenti metabolici effettuati mediante precursori marcati con isotopi radioattivi dimostrarono che i vari atomi che formano l'anello purinico (v. formula 3 nel precedente cap. 5, È b) traggono origine da precursori diversi: l'azoto-i deriva dall'acido aspartico: il carbonio-2 ed il carbonio-8 derivano dall'acido formico; il carbonio-6 dal CO2; l'azoto-3 e l'azoto-9 dall'azoto ammidico della glutammina; il carbonio-4, il carbonio-5 e l'azoto-7 dalla glicina. Questa sintesi, tuttavia, ha luogo in passaggi successivi, con formazione intermedia di ribonucleotidi a catena aperta. Tra l'α-5-fosforibosil-l-pirofosfato (17) e l'acido inosinico (18) vi sono, per esempio, nove composti intermedi.
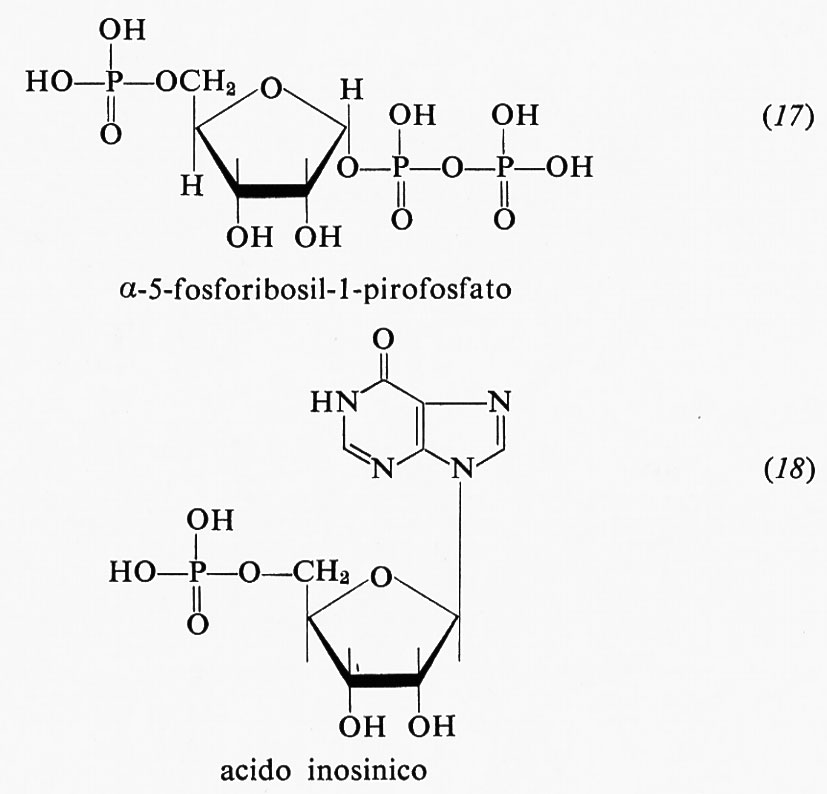
L'acido inosinico è poi trasformato, via acido adenilosuccinico, in acido adenilico (15), oppure, via un altro intermediario (per es., acido xantilico), in acido guanilico.

La biosintesi dei ribonucleotidi pirimidinici segue un itinerario alquanto più semplice. Dapprima si forma l'acido orotico (19), che viene poi condensato col 5-fosforibosil-1-pirofosfato (17) per dare, dopo una decarbossilazione, l'acido uridilico. Questo è quindi trasformato in uridin-5′-trifosfato, che viene amminato dall'ammoniaca o dalla glutammina, formando citidin-5′-trifosfato. La pirofosforilazione di un nucleotide con formazione di un nucleoside trifosfato, che è l'effettivo precursore dell'acido ribonucleico, viene qui esemplificata nei seguenti due casi concreti: a) formazione dell'uridintrifosfato (UTP) dall'acido uridilico (UMP); b) interconversione dell'adenosindifosfato (ADP), dell'acido adenilico (AMP) e dell'adenosintrifosfato (ATP). Queste reazioni sono catalizzate da un gruppo di enzimi noti come chinasi.
UMP + ATP ⇄ UDP + ADP a)
UDP + ATP ⇄ UTP + ADP
2ADP ⇄ AMP + ATP b)
b) Biosintesi dei desossiribonucleotidi
Benché in alcune cellule esistano meccanismi con cui i 2-desossiriboderivati si possono formare attraverso composti intermedi analoghi a quelli che si formano nella sintesi dei ribonucleotidi, esistono due vie alternative che sembrano essere ben più importanti. Esse fanno entrare in gioco la riduzione diretta dei ribonucleotidi, trasformando il gruppo
in posizione 2′ dello zucchero in un gruppo
Nella prima serie di reazioni, i precursori sono i ribonucleosidi difosfati ADP, GDP, CDP e UDP; questi sono trasformati nei desossi-analoghi per mezzo di diversi enzimi e con la partecipazione di un donatore di elettroni, che è la forma ridotta di una proteina detta tioredoxina. La seconda via, abbastanza simile alla prima, conduce alla riduzione dei ribonucleosidi trifosfati nei desossiderivati corrispondenti. Sono anche interessati altri due sistemi enzimatici: a) per metilare l'acido desossiuridilico ad acido timidilico; b) per trasformare i nucleosidi mono- e difosfati in trifosfati tramite diverse chinasi.
c) Meccanismi di recupero e altre ‛scorciatoie'
Benché il bilancio finale sia fornito dalla termodinamica, la nostra effettiva comprensione dell'economia della cellula vivente è ancora molto scarsa. Dovunque guardiamo, possiamo constatare che i sistemi di sintesi e quelli di degradazione coesistono; le funzioni che attribuiamo a tali sistemi non sono certo suffragate dal consenso della cellula stessa, essendo piuttosto il frutto dell'opinione della maggioranza degli scienziati che operano in un determinato periodo. È abbastanza insensato considerare la cellula vivente dal punto di vista di un contabile. Infatti, si corre sempre il rischio di concludere che, se solo fossimo stati consultati all'atto della creazione, avremmo fatto tutto in modo diverso.
Indubbiamente, la cellula non sempre ‛comincia dal principio'. In verità, essa possiede diversi meccanismi che consentono di riutilizzare svariati prodotti di degradazione parziale. Mentre i mononucleotidi prodotti dalla degradazione enzimatica del DNA e dell'RNA sono talvolta ulteriormente metabolizzati - come le purine, ad esempio, che vengono escrete sotto forma di acido urico o allantoina, oppure le pirimidine, escrete come urea e ammoniaca - esistono anche enzimi che possono riformare nucleotidi dalle purine (per condensazione con il composto 17), ed altri enzimi che le possono condensare con l'l-fosforibosio per formare nucleosidi. Questi ultimi possono esser convertiti, a loro volta, in nucleotidi, per azione di un gruppo di transferasi dette nucleosidefosfotransferasi. Si tratta qui di una reazione a bassa energia; esistono però anche altri sistemi enzimatici, piuttosto dispendiosi dal punto di vista di un contabile, che compiono lo stesso passaggio mediante l'uso di composti ad alta energia, come l'ATP.
Inoltre, esistono numerosi meccanismi di regolazione, per quanto essi non siano ancora sufficientemente chiariti, mediante i quali la cellula controlla sia la dimensione e la composizione dell'insieme dei vari precursori, sia le quantità delle sue macromolecole. Con il procedere delle ricerche si potranno avere ulteriori informazioni su questo punto.
d) Enzimi della sintesi dei polinucleotidi
Le vie attraverso cui la cellula effettua la sintesi ex novo del suo DNA, cioè la replicazione del DNA, ed i meccanismi mediante i quali viene guidata e controllata la trascrizione di determinate porzioni del DNA per ottenere le varie molecole di RNA sono lungi dall'essere perfettamente comprese. Ciò non deve sorprendere, poiché questi eventi, che sono al centro della vita stessa e della stabilità genetica della cellula, devono essere correlati tra di loro da molteplici controlli e complicati equilibri. Se si considera che la biosintesi delle proteine si è dimostrata, e si sta dimostrando, ben più complessa di quanto non si pensasse all'inizio, ci si troverà ben disposti ad ammettere che i processi responsabili della sintesi del DNA e dell'RNA in vivo debbano presentare almeno lo stesso grado di complessità.
Tuttavia, la nostra conoscenza è molto più progredita per quanto riguarda la sintesi enzimatica in vitro delle catene polinucleotidiche. Prescindendo da quegli enzimi che saldano fra loro i precursori nucleotidici per formare polimeri in modo casuale o quasi-casuale, e cioè da quegli enzimi che non sono capaci di imporre sequenze specifiche e che si comportano come un ‛nastro adesivo biologico', possiamo dire che tutte le polimerasi, sia dell'RNA sia del DNA, hanno in comune tre caratteristiche: esse impiegano nucleosidi 5′-trifosfati come diretti precursori; formano un ponte fosforico tra l'α-fosfato dell'idrossile 5′ e l'idrossile 3′ del nucleotide da collegare, con l'eliminazione dei fosfati β e γ come pirofosfato; infine, esse richiedono obbligatoriamente o quasi la presenza di un polinucleotide, per lo più DNA e talvolta anche RNA, come stampo. Questi enzimi, designati RNA-polimerasi e DNA-polimerasi, possono essere considerati come nucleotidiltransferasi nelle quali il particolare stampo impiegato forma parte integrante del complesso enzimatico. I meccanismi che permettono all'enzima di riconoscere la particolare sequenza dello stampo con cui iniziare la replicazione o la trascrizione, come anche il modo in cui l'enzima si distacca dal complesso stampo-prodotto ed il prodotto si stacca dallo stampo sono ancora per lo più allo stato di ipotesi.
La ragione per cui è richiesto uno stampo è facilmente intuibile: è il modo più semplice di riprodurre, come in una negativa, la specifica sequenza di nucleotidi del polimero che funge da stampo. Ciò dimostra la grande efficacia del processo di appaiamento delle basi nel conservare qualsiasi informazione biologica contenuta in una catena polinucleotidica semplice o doppia.
Sono state isolate molte RNA-polimerasi: si tratta di proteine molto complesse, ad alto peso molecolare, formate da parecchie subunità con funzioni particolari. La loro azione è schematizzata nel diagramma A della fig. 5. Esse si servono di DNA a singola o doppia elica come stampo per sintetizzare poliribonucleotidi e non richiedono oligonucleotidi come iniziatori.
Per evitare confusione ci sembra qui opportuno precisare la distinzione tra iniziatore e stampo. Un iniziatore è un polinucleotide o, più frequentemente, un oligonucleotide che facilita o dà il via ad un processo di polimerizzazione fornendo ad un'estremità un gruppo idrossilico 3′ libero per l'inizio della catena da sintetizzare; esso è incorporato nel prodotto, la cui composizione non deve necessariamente riflettere quella dell'iniziatore. Uno stampo, invece, è un polinucleotide che determina la composizione e presumibilmente la sequenza nucleotidica del prodotto. Quest'ultimo, nella maggior parte dei casi, non sarà legato covalentemente allo stampo.
La distinzione fatta sopra può facilitare la comprensione delle DNA-polimerasi, che in generale sembrerebbero enzimi che richiedono un iniziatore. Anche in cellule primitive, come l'Escherichia coli, si sono trovate diverse DNA-polimerasi, ed è molto probabile che anche gli organismi superiori contengano molte varietà di enzimi capaci di sintetizzare in vitro catene polidesossiribonucleotidiche. In che modo tutti questi enzimi siano integrati nella cellula vivente è ancora del tutto ignoto. Infatti, non è impossibile che l'estrazione da un omogenato cellulare scompagini un complesso multienzimatico in cui le varie funzioni - come, ad esempio, l'apertura dello stampo a doppia elica, la sua trascrizione e replicazione, od anche la recisione di un segmento danneggiato nonché la sua riparazione ed il suo reinnesto - siano regolate e collegate con la crescita e la divisione cellulare.
I diagrammi B, C e D della fig. 5 servono ad esemplificare i vari modi di azione delle DNA-polimerasi. Nel diagramma B il DNA stampo (a), nucleotidi da i a 10, lega per appaiamento di basi un iniziatore desossiribonucleotidico (c), nucleotidi 8′-10′, su cui viene costituito il nuovo DNA (b), nucleotidi 1′-7′. Un'altra possibilità che può realizzarsi nel DNA stampo a singola elica circolare è che un ribooligonucleotide (nucleotidi 8′-10′) agisca da iniziatore per la catena di DNA neoformata (1′-7′), come viene mostrato nel diagramma C. È possibile che questo sia il modo in cui il DNA integro si replica in vivo: la formazione di un iniziatore tipo RNA da parte della RNA-polimerasi precede l'aggiunta ad esso della catena di DNA in formazione. Si avrebbe poi la recisione del segmento di RNA da parte di uno specifico enzima e la riparazione del DNA mediante l'inserzione enzimatica degli appropriati desossiribonucleotidi.
Un terzo modo di azione enzimatica, presentato da DNA-polimerasi trovate in molti virus oncogeni ed anche in tessuti embrionali, è illustrato nel diagramma D: in questo caso è un ribopolinucleotide ad agire da stampo (a); esso lega un iniziatore desossiribonucleotidico (c) per dar luogo ad un nuovo filamento di DNA (b). Non si sa se possa essere utilizzato anche un iniziatore ribonucleotidico. Quando in vitro si usa DNA a doppia elica come stampo per la DNA-polimerasi, sembra sia necessaria la presenza di un'endonucleasi che produca interruzioni in una delle due eliche dello stampo. In questo caso l'azione della polimerasi è formalmente simile a quella illustrata nella fig. 5 B.
A questo punto vorrei fare un'osservazione. Qualche anno fa venne avanzata, sotto il nome di ‛dogma centrale', un'ipotesi puerile che incontrò molto favore. In effetti, molti scienziati hanno una certa nostalgia per i dogmi: finalmente qualcosa di solido su cui basarsi, finalmente una certezza garantita nel mondo della scienza sperimentale che, quasi per definizione, non arriva mai a un approdo e a una conclusione definitivi.
Questo dogma svelava, prediceva, richiedeva che il flusso di informazioni biologiche fosse unidirezionale, come indicato dalle frecce nei seguenti passaggi: DNA → RNA → Proteine. Io fui, per quanto mi risulta, l'unico ad opporsi, per iscritto, a questo tentativo neoscolastico di cercare di insegnare agli angeli come ballare sulla capocchia di uno spillo; un'istruzione che non sembra essi abbiano seguito. In ogni caso, in base a prove recenti i sistemi viventi paiono meno monolitici di quanto sarebbe piaciuto al dott. Pangloss, e si pensa che tanto il DNA quanto l'RNA, alla stessa stregua in cui possono essere costruiti su stampi DNA, possono anche essere costruiti su ibridi di DNA-RNA. È infatti probabile che la replicazione del DNA cellulare integro per mezzo della DNA-polimerasi richieda l'intervento della RNA-polimerasi, benché non sia ancora chiaro in che modo questi eventi siano regolati nella cellula.
Ho menzionato precedentemente l'esistenza di enzimi capaci di produrre polinucleotidi con sequenze quasi casuali; il rappresentante più noto è la polinucleotidefosforilasi, che può sintetizzare poliribonucleotidi a partire da nucleosidi 5′-difosfati. L'equazione è:
n XDP ⇄ [XMP]n + n Pinorg.
In presenza di fosfato inorganico l'equilibrio favorisce effettivamente la fosforolisi ed è dubbio che, nella cellula, questo enzima abbia una funzione di sintesi; potrebbe rappresentare uno dei meccanismi di recupero cellulari per utilizzare RNA non necessario, convertendolo in utili nucleosidi difosfati.
Ancor meno sappiamo degli enzimi in grado di modificare catene polinucleotidiche preesistenti, ad esempio le metilasi, capaci di introdurre gruppi metilici in posizioni precise delle purine e pirimidine o nella posizione 2′ del ribosio. I meccanismi di riconoscimento che guidano questi enzimi particolarmente importanti per la produzione di tRNA con una specifica funzione costituiscono ancora un mistero.
11. Enzimi che intervengono nel catabolismo degli acidi nucleici
La degradazione è, per la cellula, un processo altrettanto vitale quanto la sintesi; ciononostante, soprattutto per motivi psicologici, essa suscita un minor interesse tra i ricercatori. Nella cellula esistono diverse nucleasi, e cioè enzimi che attaccano catene polinucleotidiche ad alto peso molecolare. Esse si possono suddividere in ribonucleasi e desossiribonucleasi, oppure, in base al loro punto di attacco, in endonucleasi ed esonucleasi.
I rappresentanti più noti di questa classe sono gli enzimi cristallizzati dal pancreas bovino. La ribonucleasi è un'endonucleasi, cioè non agisce all'estremità della catena, bensì in qualsiasi punto all'interno di essa, a patto che siano rispettate alcune condizioni: essa attacca i ponti fosforici che uniscono la posizione 5′ di qualsiasi nucleotide, all'interno di una catena di RNA, con la posizione 3′ di un nucleotide pirimidinico, con formazione di gruppi terminali 3′-fosforici. Prendendo come esempio la raffigurazione schematica di un segmento di RNA (a) in fig. 5 D, l'azione della ribonucleasi produrrebbe un frammento trinucleotidico senza fosfato terminale formato dai residui 1-3, di due molecole di uridin-3′-fosfato (residui 4 e 6), di una molecola di citidin-3′-fosfato (residuo 5) e di un tetranucleotide fosforilato ad entrambe le estremità (residui 7-10).
La ribonucleasi dunque produce 3′-nucleotidi pirimidinici e oligonucleotidi tutti formati da purine, terminanti con un 3′-nucleotide pirimidinico.
Sono state scoperte ribonucleasi di molti altri tipi: una è specifica per l'idrolisi della catena di RNA in posizioni occupate dall'acido guanilico; un'altra attacca parti di RNA legate al DNA, sotto forma di ibridi.
Il meccanismo di azione delle varie endo-desossiribonucleasi non è ancora completamente chiarito. Inoltre vi sono diverse esonucleasi che richiedono un gruppo idrossilico 3′ o 5′ libero come punto di partenza, liberando gradualmente un nucleotide dopo l'altro. Vi sono nucleasi che attaccano solo DNA a singola catena o porzioni separate di doppia elica; altre sono capaci di recidere i segmenti danneggiati, come quelli che contengono residui di timina dimerizzati; altre nucleasi sembra riconoscano molecole di DNA ‛estraneo'. A quanto pare, esiste un'enorme rete di protezione e regolazione, della quale non siamo ancora in grado di precisare l'ampiezza e gli scopi.
Altri enzimi continuano l'opera di degradazione o di recupero, una volta che gli acidi nucleici siano stati idrolizzati dalle nucleasi. Le fosfodiesterasi rompono un legame fosfodiestereo fra un nucleotide e l'altro, con produzione di nucleosidi 5′- o 3′-fosfati. Le nucleotidasi sono fosfatasi specifiche che convertono i nucleotidi in nucleosidi; le nucleosidasi rompono il legame nucleosidico, liberando purine e pirimidine. La deaminasi, alcune molto specifiche, deaminano nucleotidi o nucleosidi dell'adenina e della citosina o delle stesse basi libere. Questo elenco potrebbe essere molto ampliato.
12. Conclusioni
‟Il Maestro disse: il Cielo non parla" (Confucio). E questa è sempre stata la difficoltà della scienza, almeno da Keplero in poi. I cieli sono rimasti silenziosi, mantenendo segreta la dimostrazione ultima della verità, mentre noi intanto abbiamo espresso con voce sempre più forte la nostra opinione sui modi di operare della natura, cianciando sul caso e sulla necessità. Ma viene sempre il momento nel quale l'induzione si scontra con problemi che trascendono la nostra conoscenza.
Più proprietà scopriamo, più distinzioni facciamo, più funzioni assegniamo, più grande è il pericolo di andare completamente fuori strada. Nelle nostre scienze accade molto spesso che sia Sisifo, non già Ercole, a dover pulire le scuderie di Augia. I risultati non possono essere mai definitivi.
Nelle pagine precedenti ho preferito, di proposito, raccontare in tono pacato e distaccato una delle storie più entusiasmanti della biologia e della biochimica moderne. È ben vero che spesso alcune scoperte, e non sempre le più importanti, sono state pubblicizzate col fervore normalmente riservato al rialzo delle azioni di società minerarie inesistenti. Ma la scoperta più grande, quella di Avery, è venuta al mondo senza far chiasso. Se dovessi guardare indietro al disegno che man mano si è sviluppato, direi che furono due le osservazioni più fruttuose: la prima fu il chiarimento della trasformazione batterica, che ci ha fatto comprendere molto sulla natura chimica del meccanismo dell'ereditarietà o almeno di parte di esso; la seconda fu la scoperta dell'appaiamento delle basi, come uno dei principi fondamentali nella formazione e nell'organizzazione delle macromolecole biologiche.
Ciò che i grandi mutamenti nella nostra visione della natura hanno insegnato, almeno ad alcuni di coloro che hanno vissuto quelle vicende, è forse la consapevolezza del fatto che la scienza è, e deve rimanere, un'impresa aperta: ciò che non è successo oggi può sempre accadere domani. Se il mondo in cui viviamo non fosse divenuto un immane carnaio, se i laser fossero stati usati per guidare i ciechi anziché le bombe, se il napalm fosse stato usato per livellare il deserto anziché per creare nuovi deserti disumani, allora potremmo essere ben contenti delle meraviglie che la mente indagatrice dell'uomo, percepibile nell'opera di generazioni di scienziati, ha portato alla luce. Dobbiamo conservare sempre questa sensazione di apertura, di libertà, questo sentirsi sempre al principio. Anche per lo scienziato, infatti, è valido ciò che C. Pavese scrisse nel suo diario, Il mestiere di vivere: Perché una cosa (tra le molte) mi pare insopportabile all'artista: non sentirsi più all'inizio".
bibliografia
Avery, O. T., MacLeod, C. M., McCarty, M., Studies on the chemical nature of the substance inducing transformation of pneumococcal types, in ‟Journal of experimental medicine", 1944, LXXIX, pp. 137-157.
Brown, D. M., Ulbricht, T. L. V., Chemistry of the nucleic acids, in Comprehensive biochemistry (a cura di M. Florkin e E. H. Stotz), vol. VIII, Amsterdam 1963, pp. 155-269.
Chargaff, E., Chemical specificity of nucleic acids and mechanism of their enzymatic degradation, in ‟Experientia", 1950, VI, pp. 201-209.
Chargaff, E., Essays on nucleic acids, Amsterdam-London-New York 1963.
Chargaff, E., Davidson, J. N. (a cura di), The nucleic acids: chemistry and biology, voll. I e II, New York 1955; vol. III, New York-London 1960.
Davidson, J. N., The biochemistry of the nucleic acids, London 19727.
Davidson, J. N., Cohn, W. E. (a cura di), Progress in nucleic acid research, 12 voll., New York-London 1963-1972.
Hayes, W., The genetics of bacteria and their viruses, New York 19682.
Levene, P. A., Bass, L. W., Nucleic acids, New York 1931.
Miescher, F., Die histochemischen und physiologischen Arbeiten, 2 voll., Leipzig 1897.
Watson, J. D., Molecular biology of the gene, New York 19702 (tr. it.: Biologia molecolare del gene, Bologna 19722).
Watson, J. D., Crick, F. H. C., Molecular structure of nucleic acids, in ‟Nature", 1953, CLXXI, pp. 737-738.
Watson, J. D., Crick, F. H. C., Genetical implications of the structure of deoxy ribonucleic acid, in ‟Nature", 1953, CLXXI, pp. 964-967.