
Acidi nucleici
Acidi nucleici
Nel 1868, il giovane svizzero Friedrich Miescher, all'età di 24 anni, entrò a lavorare nel più noto laboratorio biochimico esistente, quello di Ernst Felix Hoppe-Seyler a Tubinga, dove si era recato con il proposito di studiare il protoplasma delle cellule animali e in particolare la chimica del nucleo cellulare. Appena un anno dopo, Miescher fu in grado di comunicare l'isolamento della nucleina. Si trattava, in termini attuali, della scoperta del primo acido nucleico, il desossiribonucleico (DNA), e della descrizione di una delle forme in cui questo esiste nel nucleo cellulare, cioè come nucleoproteina, il desossiribonucleoistone. Miescher, dopo essere tornato a Basilea nel 1869, inviò questo lavoro al suo ex maestro: in esso si descriveva l'estrazione, dal nucleo di cellule di pus, di una sostanza organica che sembrava di nuovo tipo, infatti era molto acida e conteneva fosforo. Hoppe-Seyler, forse un po' incredulo, non pubblicò subito il lavoro, ma decise di ripetere e verificare le osservazioni fatte da Miescher. Due anni dopo, nel 1871, egli pubblicò il lavoro originale di Miescher aggiungendovi la descrizione dell'estrazione di sostanze analoghe dagli eritrociti di uccelli e dal lievito. Questa descrizione era già, di fatto, quella del secondo tipo di acido nucleico oggi noto, cioè l'acido ribonucleico (RNA). Così, in brevissimo tempo, grazie alla collaborazione di due grandi ricercatori, fu creato un campo fondamentale e interamente nuovo della biochimica, una scienza allora assai giovane. È opportuno rammentare che gli acidi nucleici sono componenti ubiquitari della cellula: il DNA si trova prevalentemente nella zona cromatinica ed eterocromatinica del nucleo, essendo uno dei costituenti principali dei cromosomi, ma si trova anche nel citoplasma, per esempio come componente dei mitocondri, dei cloroplasti, ecc. L'RNA è più abbondante nel citoplasma, specialmente come componente dei ribosomi, e nelle regioni non particolate del citoplasma, ma si trova anche nel nucleo, in particolar modo nel nucleolo. DNA e RNA non sono designazioni al singolare, bensì collettive, poiché comprendono un grandissimo numero di specie e varietà diverse. Da questo punto di vista, i due nomi sono paragonabili a quelli di altri importanti costituenti cellulari, come le proteine, i polisaccaridi, i lipidi.
Se Miescher e Hoppe-Seyler avessero avuto a loro disposizione metodi per realizzare l'idrolisi completa dei due tipi di acidi nucleici avrebbero trovato per ognuno 6 componenti essenziali: 4 sostanze contenenti azoto, 1 zucchero e, infine, acido fosforico. Tre dei componenti azotati (l'adenina, la guanina e la citosina) sono derivati della purina e sono identici nei due tipi di acidi nucleinici. Gli altri due sono derivati della pirimidina e sono diversi nei due tipi di acidi, perché l'uracile si trova nell'RNA, mentre il suo 5-metilderivato nel DNA. La principale differenza chimica ‒ che poi è di grande importanza per le loro proprietà chimiche e biologiche ‒ consiste nel diverso componente glicidico: ribosio nell'RNA e desossiribosio nel DNA. Da ciò si comprende che i due acidi nucleici derivano le loro diverse denominazioni dal tipo di zucchero che contengono.
Un'altra differenza notevole tra i due acidi nucleici, cioè il peso molecolare molto maggiore del DNA rispetto a quello dell'RNA, non avrebbe potuto essere prevista dalla loro composizione chimica. Al tempo del loro isolamento e della loro caratterizzazione preliminare, la definizione concettuale degli acidi nucleici non era ancora completa. Ci vollero molti anni per identificare i vari componenti e molti di più perché fossero sintetizzati.
Scoperta e proprietà chimiche degli acidi nucleici
Dei quattro principali costituenti azotati del DNA, la guanina era conosciuta molto prima dell'isolamento degli acidi nucleici, ossia fin dal 1844. L'adenina fu scoperta nel 1885, la timina nel 1893 e la citosina nel 1894: tutte furono riconosciute nel laboratorio di Albrecht Kossel, premio Nobel nel 1910 per la medicina. L'unica pirimidina specifica dell'RNA, l'uracile, fu scoperta invece nel 1900. L'espressione acidi nucleici per il materiale designato come nucleina da Miescher fu introdotta da Richard Altmann nel 1889. Durante questo periodo, nessuna ulteriore aggiunta è stata fatta allo scarno elenco delle basi contenute negli acidi nucleici, ossia due purine e due pirimidine. I pochi altri costituenti azotati di cui si conosce la presenza, per lo più in piccole quantità, in alcune specie di acidi nucleici sono stati scoperti molto più tardi.
Le strutture chimiche del D-ribosio [1] e del 2-desossi-D-ribosio [2] sono presentate in due forme, quella lineare [1A] e [2A] e quella furanosica [1B] e [2B], nella quale saranno rappresentati come componenti dei nucleosidi e dei nucleotidi. La differenza tra il composto [1], che si trova nell'RNA, e quello [2], presente nel DNA, è tutt'altro che banale: l'assenza di un gruppo ossidrile sul carbonio-2 del desossiribosio è di grande importanza per le differenze nel comportamento chimico dei due acidi nucleici.
[1] formula[2]
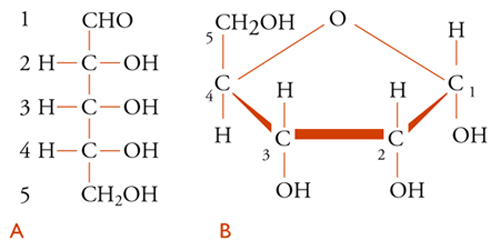
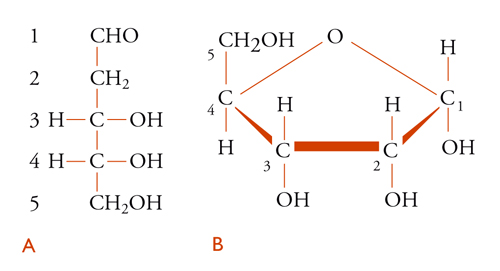
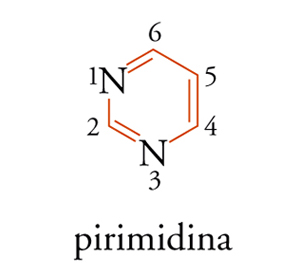
Il sistema di numerazione impiegato per i vari derivati purinici e pirimidinici riscontrabili negli acidi nucleici è illustrato nelle strutture [3] e [4], nelle quali sono omessi gli atomi di carbonio.
[3] formula[4]
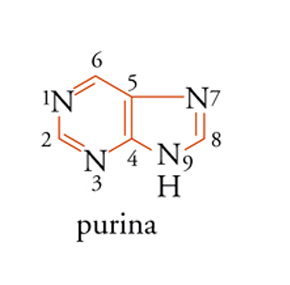
Le due purine che si trovano negli acidi nucleici sono derivati della struttura [3] e cioè l'adenina [5] e la guanina [6].
[5] formula[6]
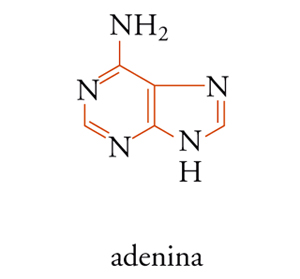
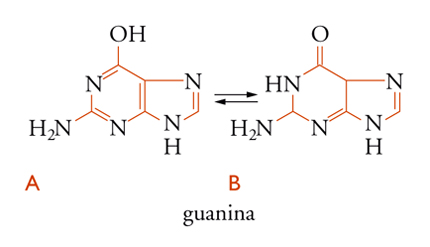
La guanina è rappresentata in due forme tautomeriche, negli acidi nucleici si trova nella forma chetonica [6B]. In pochi casi isolati, derivati metilici di queste purine entrano a far parte degli acidi nucleici come componenti secondari. I due principali derivati pirimidinici del DNA, come già detto, sono la citosina [7A] e la timina [7B], mentre nell'RNA si trovano la citosina e l'uracile [7C].
[7] formula

Queste pirimidine sono riportate ciascuna in una delle due forme tautomeriche, e precisamente quella in cui esse si presentano negli acidi nucleici. Poche altre pirimidine possono trovarsi negli acidi nucleici, talvolta in quantità rilevanti, come la 5-idrossimetilcitosina e il 5-idrossimetiluracile e anche la 5-metilcitosina, presente soprattutto negli acidi nucleici di origine vegetale.
I derivati glicosidici delle purine e delle pirimidine si chiamano nucleosidi. In questi composti lo zucchero, ribosio o desossiribosio, si lega, tramite il suo atomo di carbonio-1, alla posizione 9 delle purine o alla posizione 3 delle pirimidine. Si tratta quindi di cosiddetti N-glicosidi. Sono riportati qui di seguito due esempi di ribonucleosidi, l'adenosina [8A] e la citidina [8B], insieme con due desossiribonucleosidi, e cioè la desossiguanosina [8C] e la timidina [8D].
[8] formula
Il legame glicosidico dei nucleosidi purinici è piuttosto labile; questi composti, per trattamento con acidi, sono rapidamente idrolizzati in purina e zucchero. I nucleosidi pirimidinici sono molto più resistenti, ma possono essere idrolizzati dopo idrogenazione del nucleo pirimidinico. La loro analisi viene fatta in modo simile a quello riportato in precedenza per le purine e le pirimidine e a quello dei nucleotidi che verrà esposto qui di seguito.
Gli esteri dei nucleosidi con l'acido fosforico prendono il nome di nucleotidi. Poiché il radicale ribosidico di un ribonucleoside possiede tre ossidrili esterificabili, in posizione 2, 3 e 5, si può prevedere l'esistenza di tre diversi ribonucleotidi. Analogamente, i desossiribonucleotidi, che hanno un ossidrile in meno (quello in posizione 2), devono esistere in due forme. Tutte queste forme possono essere isolate mediante opportuna degradazione degli acidi nucleici e molte di esse sono state anche sintetizzate in laboratorio.
Dei molti possibili nucleotidi, o nucleosidi monofosfati, ne riportiamo 2, e cioè l'acido 5′-adenilico o adenosin-5′-fosfato [9A] e l'acido timidilico [9B]. Gli atomi che costituiscono l'anello purinico, come si vede, sono numerati da 1 a 9, quelli dell'anello pirimidinico da 1 a 6, mentre gli atomi di carbonio della parte glicidica di un nucleotide o di un nucleoside sono numerati da 1′ a 5′.
[9] formula
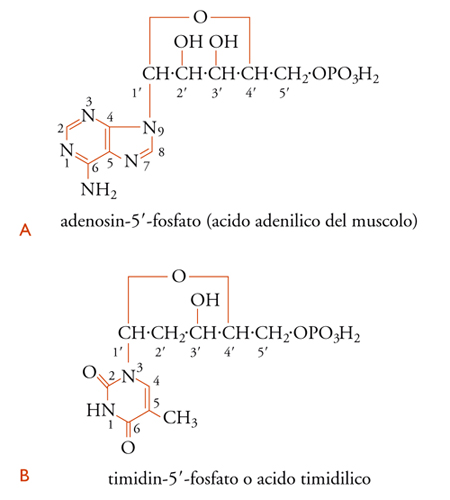
I nomi correnti dei nucleotidi che costituiscono le unità fondamentali dell'RNA e del DNA sono derivati dalla base che essi contengono; quando sono usati senza prefisso, si riferiscono ai ribonucleotidi, mentre per i desossiribonucleotidi, fatta eccezione dell'acido timidilico, si usa il prefisso 'desossi' o 'D'.
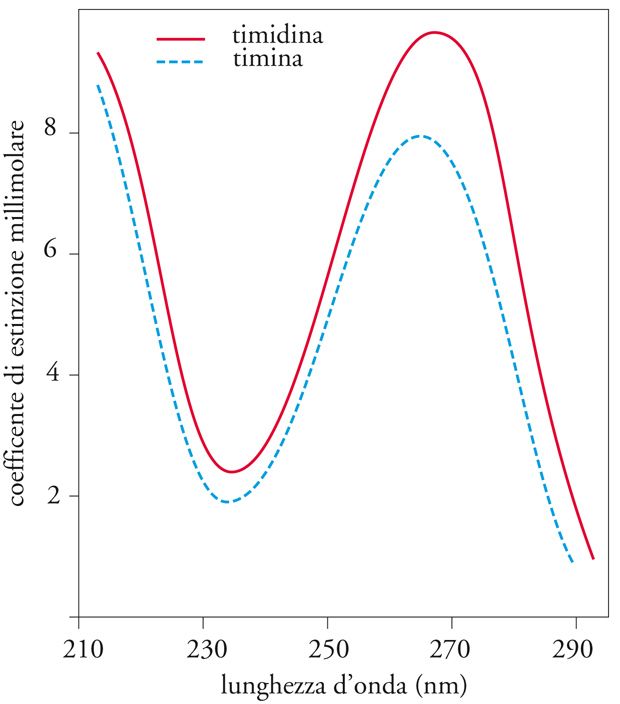
Come si può ricavare dalla loro struttura, i nucleotidi, essendo acidi forti, si trovano all'interno delle cellule e ne vengono isolati, di solito, come sali. Essi possono essere separati mediante cromatografia su carta o su strato sottile o, ancora meglio, mediante adsorbimento ed eluizione da colonne cromatografiche a scambio ionico. La caratteristica fisica più peculiare dei nucleotidi è lo spettro di assorbimento nell'ultravioletto. Durante l'analisi, i caratteristici rapporti dell'assorbimento a due diverse lunghezze d'onda servono molto spesso a identificarli. Nella maggior parte dei casi, gli spettri sono fortemente influenzati dal pH della soluzione e di ciò si deve tener conto per poter ottenere risultati confrontabili, controllando accuratamente la concentrazione idrogenionica. A titolo di esempio, riportiamo nella fig. 2 gli spettri di assorbimento della timina [7B] e del suo desossiribonucleoside timidina [8D], ottenuti a pH 7.
Per lungo tempo, soprattutto a causa della mancanza di metodi discriminanti specifici, si credette che il DNA fosse tipico dei tessuti animali e l'RNA delle cellule vegetali e microbiche. Tuttavia, appena furono disponibili metodi adeguati, tale errore fu corretto, e ora sappiamo che entrambi gli acidi nucleici sono presenti in tutte le cellule viventi, fatta eccezione degli organismi parassiti come i virus e i batteriofagi, che ne contengono solo uno, il DNA oppure l'RNA.
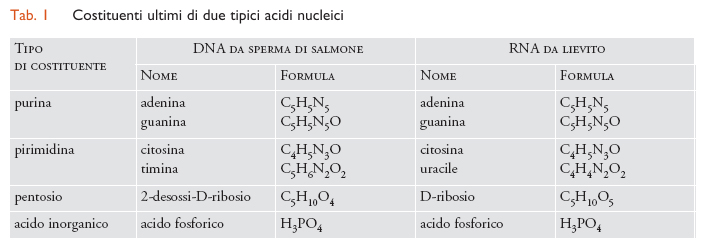
Un'altra eccessiva semplificazione fu, invece, molto più difficile da superare ed ebbe conseguenze dannose per il progresso delle nostre conoscenze. Si tratta della cosiddetta teoria del tetranucleotide. Si sapeva, infatti, che il DNA e l'RNA contenevano ciascuno quattro diverse sostanze azotate (tab. 1) e che tali sostanze, come si dimostrò in seguito, si presentavano negli acidi nucleici sotto forma di nucleotidi. Quindi se ne concluse, senza alcuna reale giustificazione, che le due purine e le due pirimidine esistevano negli acidi nucleici come tetranucleotidi. Se abbreviamo i quattro principali costituenti del DNA con A, G, C e T, la struttura avrebbe potuto essere indicata come (AGCT)n. Si suppose che il termine n fosse molto piccolo, anche se forse non si era molto riflettuto su questo punto.
Come avviene di solito nella scienza, il mutamento fu improvviso, anche se la disponibilità ad accogliere proposte rivoluzionarie fu preceduta da un cambiamento graduale del clima scientifico. Anzitutto, era necessario che i chimici e i biologi fossero pronti ad accettare l'esistenza in natura di molecole gigantesche: ciò fu il risultato del lavoro di molti scienziati, forse soprattutto dei lavori di Theodor Svedberg e di Hermann Staudinger. Ci si rese conto del grandissimo peso molecolare delle proteine e di alcuni polimeri sintetici; si apprese che esistevano molte proteine differenti l'una dall'altra per forma, dimensioni e composizione in amminoacidi. In questo contesto non si può sottovalutare l'importanza dei contributi pionieristici dell'immunologia.
Nel 1944 Oswald Theodore Avery, Colin M. MacLeod e Maclyn McCarty pubblicarono un celebre articolo che si concludeva con la frase: "La prova che abbiamo qui presentato accredita l'ipotesi che un acido nucleico del tipo con desossiribosio sia l'unità fondamentale dell'agente trasformante dello pneumococco tipo III". Benché a quel tempo non fossero in molti a rendersene conto, la scoperta di Avery, MacLeod e McCarty stabiliva la natura chimica dei geni, o almeno di alcuni geni. Si dimostrava che quando una preparazione di DNA di pneumococco veniva assunta da un'altra variante della stessa specie microbica, questa variante si trasformava "in modo ereditariamente trasmissibile", dando origine a una discendenza capace di compiere alcune reazioni di sintesi caratteristiche della variante da cui era stato estratto il DNA trasformante.
Gli esperimenti portati a termine nei primi anni Cinquanta del Novecento mostravano che la vecchia ipotesi del tetranucleotide era sbagliata e che esisteva un grandissimo numero di acidi desossiribonucleici diversi, la cui composizione era costante e caratteristica nell'ambito di una specie e di tutti gli organi di una stessa specie. In altre parole, tali esperimenti mostravano che le differenti varietà di DNA si distinguevano l'una dall'altra, come nel caso delle proteine, per la differente disposizione dei loro costituenti, cioè per le differenti sequenze dei nucleotidi. A rigor di termini, questa fu l'origine del concetto, ora accettato comunemente, di contenuto di informazioni del DNA.
Nello stesso periodo fu osservata un'altra cosa, ancora più sorprendente e del tutto inaspettata, che distingueva gli acidi nucleici dalle proteine, e che consisteva in una specie di equilibrio tra i vari componenti del DNA, mai osservato prima in altri polimeri naturali. Si tratta della complementarità tra adenina e timina da una parte e tra guanina e citosina dall'altra, ora comunemente indicata come appaiamento delle basi.
Queste regolarità, rese note in parecchi articoli pubblicati fra il 1948 e il 1950, erano le seguenti: se si indica la formula generale del DNA come (AmGnCoTp), troviamo che in molte specie di DNA a differente composizione e con differenti valori di m, n, o e p i numeri m e p sono sempre eguali fra loro, così come i numeri n e o. Inoltre, le somme (m + n) e (o + p) sono eguali, così come lo sono (m + o) e (n + p). Quindi troviamo che i costituenti del DNA devono essere appaiati nel modo seguente: l'adenina [5] con la timina [7B]; la guanina [6] con la citosina [7A]; le purine con le pirimidine; i costituenti chimicamente definibili come 6-amminoderivati (adenina e citosina) con i 6-cheto-derivati (guanina e timina).
Sulla base di queste scoperte e delle indagini mediante raggi X sulla struttura del DNA condotte da Maurice Wilkins a Londra, James Watson e Francis Crick formularono nel 1953 l'interessante ipotesi sull'architettura macromolecolare del DNA, cioè la sua struttura secondaria. Questo modello propone una doppia elica formata da due catene di DNA intrecciate, tenute insieme da specifici legami idrogeno, cioè quegli stessi legami previsti dal principio dell'appaiamento delle basi. Il modello a doppia elica del DNA suggerì immediatamente un possibile meccanismo mediante il quale la cellula può effettuare la duplicazione di una molecola di DNA conservandone l'informazione biologica intrinseca, che si basa sulla sua particolare sequenza di nucleotidi.
Mentre procedeva tutto questo lavoro sul DNA, la conoscenza dell'RNA restava relativamente ferma, salvo lo sviluppo dei metodi analitici. Si sapeva, da qualche tempo, che le preparazioni di RNA da animali, da piante o da cellule microbiche, erano molto meno omogenee per composizione e proprietà fisiche rispetto al DNA. Molte importanti ricerche sull'RNA furono compiute nel decennio successivo alla scoperta della struttura a doppia elica del DNA. In primo luogo si stabilì definitivamente, grazie soprattutto ai lavori di Alexander R. Todd e dei suoi collaboratori, che la struttura portante degli acidi nucleici (RNA e DNA) consisteva effettivamente, come già supposto, in una catena di nucleotidi uniti l'uno all'altro da ponti fosforici ripetuti regolarmente tra le posizioni 3′ e 5′ di 2 zuccheri contigui.
I progressi più importanti riguardavano il problema della trasmissione dell'informazione biologica. Infatti, se si accetta il principio che le caratteristiche ereditarie della cellula siano racchiuse in un codice rappresentato da una specifica sequenza di nucleotidi in una catena di DNA, il modello a doppia elica può spiegare come l'informazione genetica possa essere conservata. Ma come viene trasmessa? In che modo le informazioni contenute presumibilmente nella catena di DNA sono ritrasmesse al resto della cellula e dell'organismo? Questa trasmissione fa parte dei compiti assegnati all'RNA.
Il primo indizio in tal senso fu la scoperta di sistemi enzimatici (RNA-polimerasi). Questi enzimi utilizzano il DNA come stampo obbligato, sintetizzando di conseguenza molecole di RNA di composizione e sequenza complementari. In altri termini, il DNA serve come stampo sia per la propria replicazione (mediante le DNA-polimerasi), sia per la propria trascrizione (mediante le RNA-polimerasi). Le molecole di RNA, tutte presumibilmente derivate da tali processi di trascrizione, appartengono a numerose classi differenti. Vi si trovano, tra l'altro, le specie, a peso molecolare relativamente alto, di RNA ribosomiale, le piccole molecole di RNA solubile (o transfer), e infine un grandissimo numero di molecole, l'RNA messaggero, che sono gli agenti diretti della ripetizione delle istruzioni derivanti dal DNA. L'RNA messaggero specifica ai ribosomi, dove avviene la sintesi delle proteine, la struttura degli enzimi e delle altre proteine.
Infine, è stato possibile dimostrare che una molecola di RNA messaggero può essere considerata formata da una serie di ribotrinucleotidi e che ognuna di queste triplette rappresenta la parola in codice per un dato amminoacido.
Chimica generale degli acidi nucleici
Ciò che tutti gli acidi nucleici hanno in comune è l'essere composti ad alto peso molecolare, idrosolubili e ad alta carica negativa. Essi contengono quantità equimolari di basi azotate, di zuccheri e di gruppi fosfato: quindi sono meglio classificabili come polimeri di nucleotidi, cioè polinucleotidi. I nucleotidi, in tutti gli acidi nucleici, sono uniti l'uno all'altro da ponti fosforici tra l'ossidrile-5′ di un nucleoside e l'ossidrile-3′ di quello adiacente, in modo da formare lunghissime catene nucleotidiche.
Mentre i rapporti molari, secondo il principio dell'accoppiamento delle basi, sono sempre prossimi all'unità, il rapporto fra adenina + timina e guanina + citosina, e cioè il cosiddetto rapporto di dissimmetria, varia ampiamente nelle varie specie di DNA. Specialmente i microorganismi mostrano un campo di variabilità molto ampio nella composizione: il rapporto di dissimmetria varia, infatti, fra 3 e 0,5. È possibile, quindi, distinguere molecole di DNA di tipo AT, di tipo GC e di tipi intermedi con distribuzione quasi equimolare dei nucleotidi. Queste grandi differenze nella composizione indicano che ve ne sono anche nella sequenza dei nucleotidi nei diversi acidi nucleici e, potenzialmente, grandi differenze nel loro presumibile contenuto di informazioni. Per le cellule superiori, vegetali e animali, le differenze nella composizione sono meno spiccate, poiché esse hanno tutte acidi nucleici del tipo AT a eccezione dei protozoi.
Nel DNA batterico le basi puriniche e pirimidiniche meno comuni sono scarsamente rappresentate, mentre, specialmente nel DNA delle piante, si trovano notevoli quantità di un quinto componente, la 5-metilcitosina: minori quantità se ne trovano anche nel DNA di alcuni mammiferi, nel quale, ovunque sia possibile fare dei confronti, non si riscontrano differenze nella composizione per le preparazioni estratte da differenti organi della stessa specie. Vi è, invece, una differenza, piccola ma statisticamente significativa, tra specie diverse.
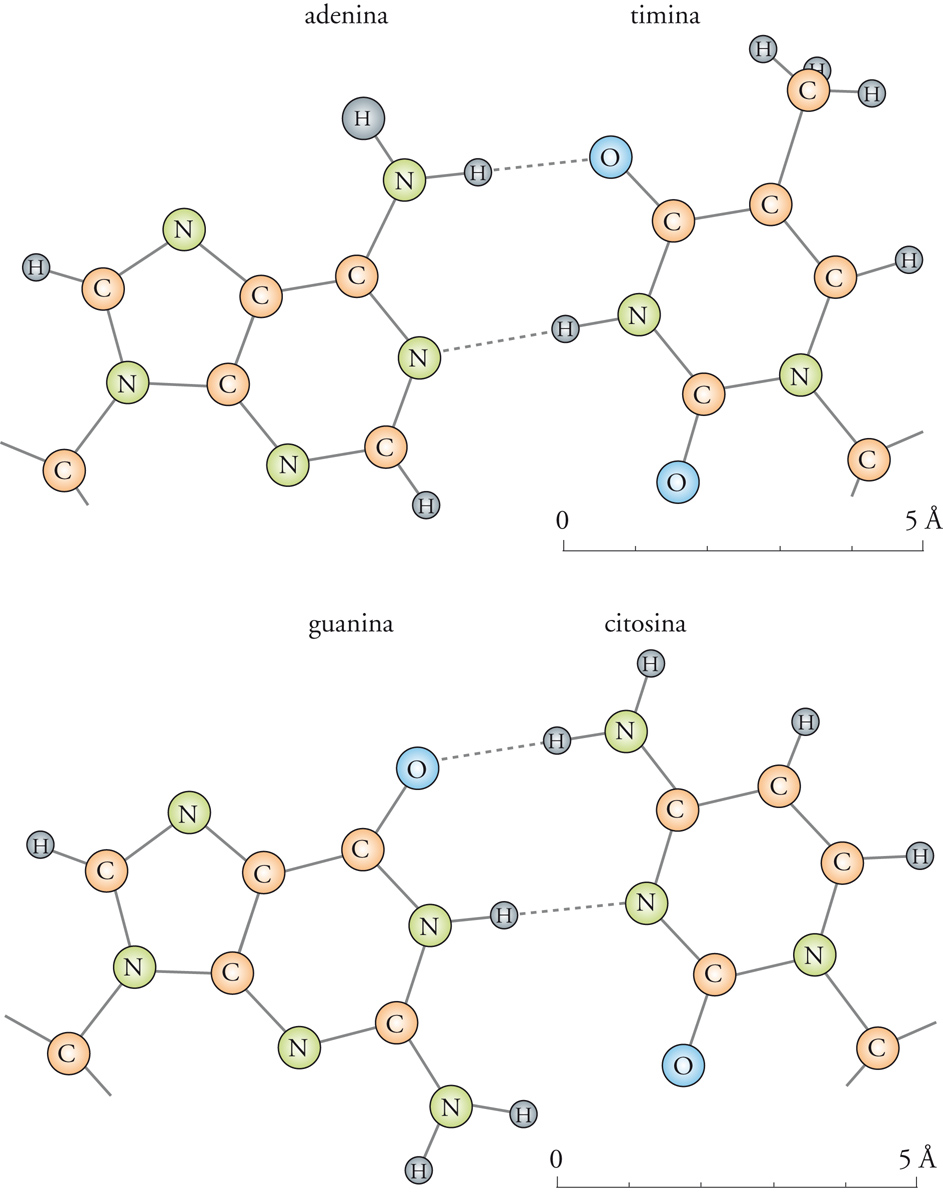
Il modello delle singole coppie di basi adenina-timina e guanina-citosina proposto da Watson e Crick è riportato nella fig. 3. Questo modello ha avuto grande influenza sull'ulteriore sviluppo della biochimica, della biofisica e della genetica.
Il peso molecolare calcolato per differenti campioni intatti di DNA varia da un valore di pochi milioni a valori di centinaia e perfino di migliaia di milioni. Una molecola di DNA di peso molecolare pari a 900 milioni, per esempio, contiene 3 milioni di nucleotidi; ciò significa che ciascuna delle due catene di tale composto presenterebbe addirittura 1,5 milioni di nucleotidi. Si tratterebbe di una lunghissima e sottilissima doppia struttura, la cui integrità, ovviamente, dovrebbe essere molto sensibile alle forze idrodinamiche. Si può effettivamente osservare che le preparazioni di DNA si spezzano facilmente per effetto di forze di stiramento, dando luogo a una varietà di strutture a doppia elica più corte. Ciò rende estremamente difficile l'isolamento di preparazioni di DNA intatto con peso molecolare maggiore di 150 milioni.
Può sembrare strano che lo stiramento idrodinamico possa rompere i legami esterei del fosforo, che sono relativamente forti e che tengono insieme la struttura primaria di un polinucleotide, senza con ciò alterare la struttura secondaria, cioè le coppie di basi unite da legami idrogeno tra le due catene complementari. Questa differenza di comportamento non è assoluta: la separazione delle catene, in effetti, si può verificare in soluzioni prive di elettroliti; ma la doppia elica è mantenuta da un numero elevato di coppie di basi in cooperazione, come nel meccanismo di una chiusura lampo, e questo conserva l'architettura generale.
La maggior parte delle prime ricerche sulla composizione chimica e sulle proprietà dell'RNA deve essere scartata, poiché allora non ci si rendeva conto dell'esistenza nelle cellule di parecchi tipi di RNA che sono differenti sia funzionalmente sia chimicamente e fisicamente. Inoltre, l'RNA si trova in molte zone differenti della cellula: più del 10% di tutta la quantità di questo acido presente nella cellula si trova nel nucleo, più del 50% nei ribosomi, circa il 15% nei mitocondri e il rimanente nella parte non strutturata del citoplasma, ossia nel citosol. È opportuno distinguere tre tipi principali di RNA: il ribosomiale (rRNA); il messaggero (mRNA); il transfer (tRNA).
Si può affermare, in generale, che i ribosomi contengono due classi di RNA ribosomiale: una ha un peso molecolare variabile da 1 a 1,5 milioni, mentre l'altra, più leggera, ha peso molecolare pari a circa la metà di quello della prima classe. Nelle piante e nei microorganismi si rileva che non vi è relazione tra questi tipi di rRNA e il DNA in un medesimo organismo. Non si riscontrano regolarità connesse all'appaiamento delle basi, come nel caso del DNA, neppure nel rapporto fra purine e pirimidine, che risulta quasi sempre molto maggiore dell'unità. Il più importante composto azotato è la guanina, seguito, nella maggior parte dei casi, dalla citosina. Una certa somiglianza può essere riconosciuta, invece, tra le due classi di rRNA all'interno di una stessa specie.
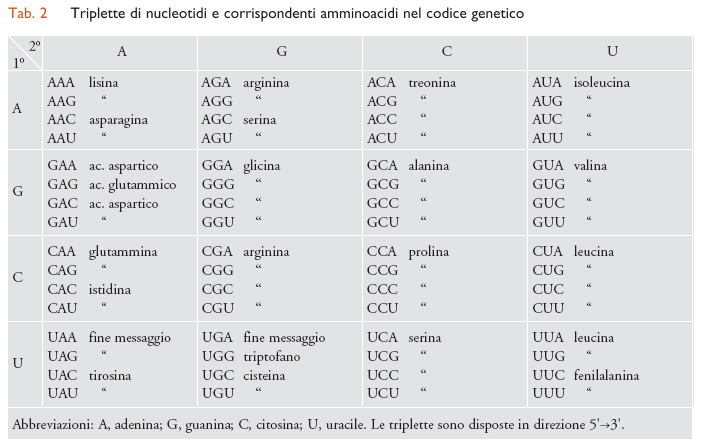
La quantità di RNA messaggero rispetto a tutto l'RNA di una cellula è probabilmente molto piccola: di poche unità per cento; l'mRNA deve però comprendere un grandissimo numero di molecole chimicamente differenti, forse pari o addirittura superiore al numero delle differenti proteine cellulari. Secondo i concetti attuali, i vari geni, o sequenze di geni, sono rappresentati, sulla catena del DNA, da una serie di nucleotidi che sono trascritti in forma di molecole di mRNA per mezzo della RNA-polimerasi. Questi mRNA portano l'informazione biologica ai ribosomi, dove ha luogo il montaggio specifico degli amminoacidi per formare le proteine. Secondo le idee attuali, il contenuto di informazione biologica di una molecola di mRNA è basato sulla sequenza di triplette nucleotidiche, cioè la sequenza di triribonucleotidi, ciascuna delle quali rappresenta il codice di un amminoacido. Si pensa che il codice sia degenerato, e cioè che vi sia più di una sola parola in codice per ciascun amminoacido. Inoltre, il terzo nucleotide della maggior parte delle triplette sembra essere meno importante dei primi due. Delle 64 possibili triplette, 61 corrispondono ad amminoacidi, mentre le altre 3 servono come segnale della fine di un polipeptide. Nella tab. 2 è riportato il codice attualmente noto, basato principalmente su ricerche effettuate con Escherichia coli.
Affinché uno specifico amminoacido sia inserito in una specifica posizione di una catena polipeptidica in accrescimento, sintetizzata dal complesso 'ribosoma-mRNA', esso deve essere riconosciuto, attivato, trasportato e sistemato al suo posto. Oltre a vari enzimi e cofattori, l'agente principale è una molecola di tRNA, di cui devono esistere nella cellula almeno tanti tipi diversi quanti sono i diversi amminoacidi che formano una proteina.
Sono stati isolati moltissimi tipi di tRNA, ciascuno specifico per un singolo amminoacido; qualcuno è stato ottenuto allo stato cristallino e di pochissimi è nota tutta la sequenza di nucleotidi. Essi hanno tutti basso peso molecolare, circa 25.000, e contano circa 80 nucleotidi. Al contrario della maggior parte degli acidi nucleici, il tRNA contiene notevoli quantità di composti azotati atipici: purine e pirimidine modificate o sostituite, come metilderivati, pseudouridina, diidrouracile, ipoxantina, ecc. Tutti i tipi di tRNA hanno molte caratteristiche in comune: il nucleotide terminale della parte dove si trova l'acido fosforico monoesterificato è sempre l'acido guanilico; l'altra estremità termina con l'acido adenilico, al cui ossidrile in posizione 2′ o 3′ si lega, con legame estereo, l'amminoacido attivato. A causa della presenza di molte regioni capaci di formare accoppiamenti di basi, i tRNA mostrano strutture specifiche dette a trifoglio. Una delle anse intercalate tra segmenti a doppia elica porta l'anticodone (o anticodice), e cioè una tripletta complementare a quella che corrisponde a un particolare amminoacido. Per esempio, l'anticodice di uno dei codici per la fenilalanina (UUU, tab. 2) sarebbe AAA. È proprio attraverso tali interazioni tra tRNA e mRNA che si raggiunge il corretto inserimento di ogni amminoacido nella catena polipeptidica in accrescimento. D'altra parte, la mutazione di una sola base nel DNA può provocare la sostituzione di un amminoacido con un altro nella proteina.
Gli immediati precursori dell'RNA e del DNA sono, molto probabilmente, i nucleosidi 5′-trifosfati.
[10] formula
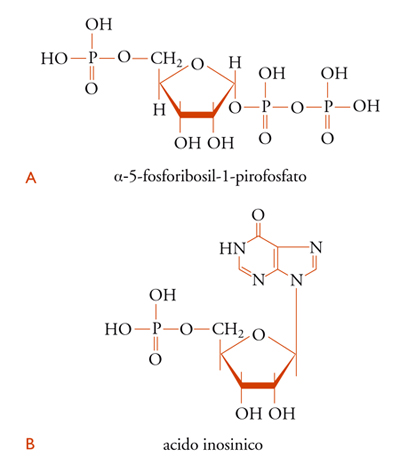
Esperimenti metabolici effettuati mediante precursori marcati con isotopi radioattivi dimostrarono che i vari atomi che formano l'anello purinico traggono origine da precursori diversi: l'azoto-1 deriva dall'acido aspartico: il carbonio-2 e il carbonio-8 derivano dall'acido formico; il carbonio-6 dal CO2; l'azoto-3 e l'azoto-9 dall'azoto ammidico della glutammina; il carbonio-4, il carbonio-5 e l'azoto-7 dalla glicina. Questa sintesi, tuttavia, ha luogo in passaggi successivi, con formazione intermedia di ribonucleotidi a catena aperta. Tra l'α-5-fosforibosil-1-pirofosfato [10A] e l'acido inosinico [10B] vi sono, per esempio, 9 composti intermedi.
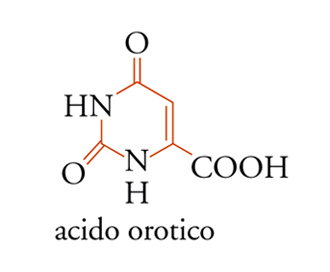
L'acido inosinico viene poi trasformato, via acido adenilosuccinico, in acido adenilico [9A], oppure, via un altro intermediario (per es., acido xantilico), in acido guanilico. La biosintesi dei ribonucleotidi pirimidinici segue un itinerario alquanto più semplice. Dapprima si forma l'acido orotico [11], che viene poi condensato col 5-fosforibosil-1-pirofosfato [10A] per dare, dopo una decarbossilazione, l'acido uridilico. Questo è quindi trasformato in uridin-5′-trifosfato, che viene amminato dall'ammoniaca o dalla glutammina, formando citidin-5′-trifosfato.
[11] formula
Benché in alcune cellule esistano meccanismi con cui i 2-desossiriboderivati si possono formare attraverso composti intermedi analoghi a quelli che si formano nella sintesi dei ribonucleotidi, esistono due vie alternative che sembrano essere ben più importanti. Nella prima serie di reazioni, i precursori sono i ribonucleosidi difosfati ADP, GDP, CDP e UDP; questi sono trasformati nei desossi-analoghi per mezzo di diversi enzimi e con la partecipazione di un donatore di elettroni, che è la forma ridotta di una proteina detta tioredoxina. La seconda via, abbastanza simile alla prima, conduce alla riduzione dei ribonucleosidi trifosfati nei desossiderivati corrispondenti.
Le vie attraverso cui la cellula effettua la sintesi ex novo del suo DNA, cioè la replicazione del DNA, e i meccanismi mediante i quali viene guidata e controllata la trascrizione di determinate porzioni del DNA per ottenere le varie molecole di RNA, non sono perfettamente comprese. Ciò non deve sorprendere, poiché questi eventi, che sono al centro della vita stessa e della stabilità genetica della cellula, devono essere correlati tra loro da controlli molteplici ed equilibri complicati.
Prescindendo da quegli enzimi che saldano fra loro i precursori nucleotidici per formare polimeri in modo casuale o quasi-casuale, e cioè da quegli enzimi che non sono capaci di imporre sequenze specifiche e che si comportano come un nastro adesivo biologico, possiamo dire che tutte le polimerasi, sia dell'RNA sia del DNA, hanno in comune tre caratteristiche: impiegano nucleosidi 5′-trifosfati come diretti precursori; formano un ponte fosforico tra l' α-fosfato dell'ossidrile 5′ e l'ossidrile 3′ del nucleotide da collegare, con l'eliminazione dei fosfati β e γ come pirofosfato; infine, richiedono obbligatoriamente (o quasi) la presenza di un polinucleotide, per lo più DNA e talvolta anche RNA, come stampo. Questi enzimi, designati RNA-polimerasi e DNA-polimerasi, possono essere considerati come nucleotidiltransferasi nelle quali il particolare stampo impiegato forma parte integrante del complesso enzimatico.
La ragione per cui è richiesto uno stampo è facilmente intuibile: è il modo più semplice di riprodurre, come in un negativo, la specifica sequenza di nucleotidi del polimero che funge da stampo. Ciò dimostra la grande efficacia del processo di appaiamento delle basi nel conservare qualsiasi informazione biologica contenuta in una catena polinucleotidica semplice o doppia. Per evitare confusione è opportuno precisare la distinzione tra iniziatore e stampo. Un iniziatore è un polinucleotide o, più frequentemente, un oligonucleotide che facilita o innesca un processo di polimerizzazione fornendo, a un'estremità, un gruppo ossidrilico 3′ libero per l'inizio della catena da sintetizzare; esso è incorporato nel prodotto, la cui composizione non deve necessariamente riflettere quella dell'iniziatore. Uno stampo, invece, è un polinucleotide che determina la composizione e presumibilmente la sequenza nucleotidica del prodotto. Quest'ultimo, nella maggior parte dei casi, non sarà legato covalentemente allo stampo.
Bibliografia
Avery 1944: Avery, Oswald T. - MacLeod, Colin M. - McCarty, Maclyn, Studies on the chemical nature of the substance inducing transformation of pneumococcal types. Induction of transformation by a desoxyribonucleic acid fraction isolated from Pneumococcus type III, "Journal of experimental medicine", 79, 1944, pp. 137-157.
Chargaff 1950: Chargaff, Erwin, Chemical specificity of nucleic acids and mechanism of their enzymatic degradation, "Experientia", 6, 1950, pp. 201-209.
Chargaff 1963: Chargaff, Erwin, Essays on nucleic acids, Amsterdam-London-New York, Elsevier, 1963.
Chargaff, Davidson 1955-1960: The nucleic acids: chemistry and biology, edited by Erwin Chargaff, James N. Davidson, New York, Academic Press, I-II, 1955; New York-London, Academic Press, III, 1960.
Hayes 1964: Hayes, William, The genetics of bacteria and their viruses, Oxford, Blackwell Scientific, 1964.
Levene, Bass 1931: Levene, Phoebus A. - Bass, Lawrence W., Nucleic acids, New York, The Chemical Catalog Company, 1931.
Miescher 1897: Miescher, Friedrich, Die histochemischen und physiologischen Arbeiten, Leipzig, Vogel, 1897, 2 v.
Watson 1970: Watson, James D., Molecular biology of the gene, New York, Benjamin, 1965 (2. ed. 1970) (trad. it.: Biologia molecolare del gene, Bologna, Zanichelli, 1967).
Watson, Crick 1953: Watson, James D. - Crick, Francis H.C., Molecular structure of nucleic acids. A structure for deoxy-ribose nucleic acid, "Nature", 171, 1953, pp. 737-738.
Watson, Crick 1953: Watson, James D. - Crick, Francis H.C., Genetical implications of the structure of deoxy ribonucleic acid, "Nature", 171, 1953, pp. 964-967.