
algoritmo di ricerca
algoritmo di ricerca
algoritmo di ricerca algoritmo il cui obiettivo è la ricerca di un elemento specifico in una lista composta da numerosi elementi. Esempi elementari di ricerche possono essere la ricerca di una penna su una scrivania, la ricerca di un numero telefonico di un abbonato inserito nell’apposito elenco, la ricerca di un oggetto nella tasca in un particolare capo d’abbigliamento di cui si sappia la collocazione. I tre casi elencati differiscono per il fatto che l’insieme sul quale opera la ricerca può essere ordinato o meno. Nel primo caso, l’insieme è chiaramente non ordinato e la strategia di ricerca si avvale di tentativi mirati, ciascuno ridefinito sulla base del precedente (per esempio ricercare la penna nella zona più vicina a quella coperta dal movimento delle mani e, in caso di insuccesso, allargare sempre di più l’area di azione; oppure si può suddividere la scrivania in settori e iniziare la ricerca in ognuno di essi). Nel secondo caso, è disponibile un insieme ordinato, secondo uno o più criteri (lessicografico: prima per cognome, poi per nome in caso di cognomi uguali ecc.); la conoscenza del criterio di ordinamento permette di giungere rapidamente al risultato. Nel terzo caso, le informazioni possedute guidano al progressivo restringimento dell’ambito della ricerca per giungere al risultato. L’organizzazione degli oggetti all’interno dell’insieme su cui si effettua la ricerca condiziona fortemente l’algoritmo che si adotta. Un algoritmo di ricerca si basa, quindi, sulla conoscenza della struttura dei dati su cui esso opera.
Il più semplice algoritmo di ricerca consiste nell’operare una ricerca sequenziale, cioè nel ricercare l’elemento desiderato tra n elementi, scorrendoli tutti, dal primo all’ultimo, all’interno della lista dell’array secondo cui sono organizzati. È un criterio semplice nel caso in cui i dati siano pochi, ma è poco conveniente dal punto di vista del tempo computazionale, cioè del numero di passi di calcolo da eseguire, poiché può essere necessario leggere tutti gli n dati. Il costo del calcolo (numero dei passi necessari da effettuare per eseguirlo) è dell’ordine di grandezza di n. Per esempio, se si deve trovare una penna tra 100 altri oggetti diversi sparsi sulla scrivania, l’algoritmo di ricerca può essere realizzato assegnando i nomi degli oggetti agli elementi di un array e utilizzando una variabile booleana, detta flag che, a seconda del valore logico vero o falso, ne specifica l’esito. Per esempio:

Se, per qualche motivo, è noto che l’elemento si trovi verso la fine della lista, l’algoritmo può procedere in senso inverso, dall’ultimo elemento sino al primo.
Un criterio più utile per la ricerca all’interno di un insieme ordinato è la → ricerca dicotomica (o binaria) che consiste nel suddividere ogni volta la lista degli elementi in due sottoinsiemi di ugual numero e controllare se l’oggetto si trovi nell’uno o nell’altro gruppo. Esistono tuttavia strutture di dati che rispondono a più complessi criteri di ordinamento. Per esempio, gli utenti dell’elenco telefonico possono essere organizzati in una
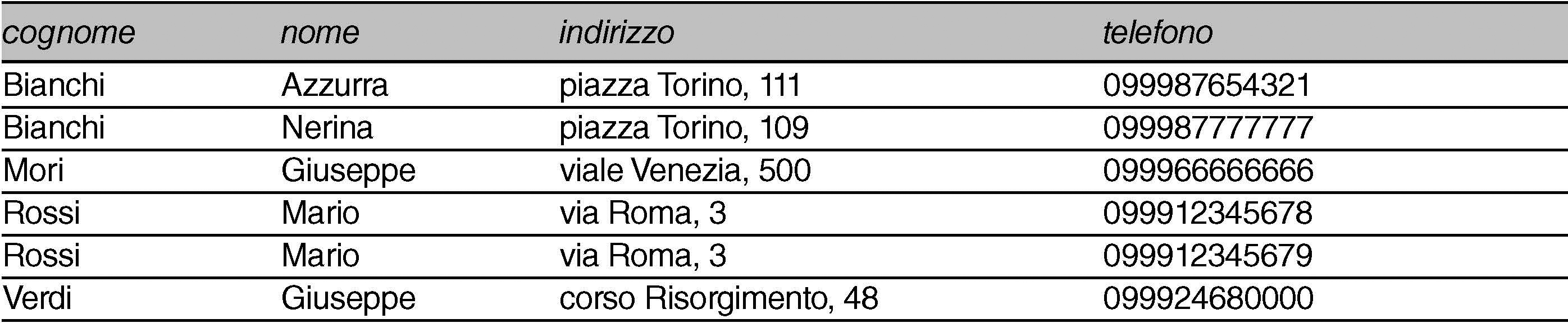
, ma appaiono con un ordine definito da priorità diverse: prima il cognome, poi il nome, quindi l’indirizzo, infine il numero di telefono; la struttura dei dati così definita può essere organizzata in un database, formato da record, ognuno con propri campi in cui sono custodite informazioni. L’algoritmo di ricerca in un database consiste nel ricavare le informazioni contenute in uno o più campi attraverso una query, che definisce con precisione la proprietà dei dati desiderati. Qui un esempio di dati archiviati in modo tabellare: ciascuna riga dell’elenco è un record del database, i cui campi sono rappresentati da ‘cognome’, ‘nome’, ‘indirizzo’, ‘telefono’.
Se si desidera conoscere il numero telefonico del signor Mori, il risultato della ricerca sarà un unico record contenente l'informazione desiderata. Supponendo, invece, di voler conoscere il telefono del signor Bianchi, il risultato della ricerca fornirà due record differenti (due diversi utenti): quando la ricerca del valore di un campo dà come risultato un insieme di record, l’algoritmo di ricerca dovrà utilizzare le operazioni booleane (→ Boole, algebra di) per perfezionare la ricerca, operando i confronti opportuni. Per esempio, la query al programma di ricerca per ottenere l’indirizzo di Bianchi Nerina è: «quali sono i valori del campo ‘indirizzo’ relativo ai record in cui è vero che (‘cognome’ = Bianchi and ‘nome’ = Nerina)?». L’algoritmo di ricerca fornirà come risposta: ‘indirizzo’ = piazza Torino, 109. La query per ottenere i numeri di telefono di tutti gli abbonati fino al cognome Rossi (escluso) sarà invece la seguente: «quali sono i valori del campo ‘telefono’ relativo ai record in cui è vero che (‘cognome’ < ‘Rossi’)?». L’algoritmo di ricerca fornirà come output la lista ordinata dei numeri telefonici dei primi tre abbonati.
Il campo sul quale agiscono le operazioni booleane prende il nome di campo chiave di ricerca. È possibile anche creare una chiave di ricerca composta operando simultaneamente su due o più campi. A seconda delle priorità attribuite, le chiavi di ricerca si suddividono in chiavi primarie e chiavi secondarie, sulla base del livello del loro utilizzo nella ricerca. Una chiave primaria composta dell’esempio precedente può essere quella definita dalla coppia (‘cognome’, ‘nome’); tuttavia è a volte necessario utilizzare una chiave secondaria per effettuare una ricerca più precisa all’interno del sottoinsieme dei record che assumono gli stessi valori della chiave primaria. Per aumentare l’efficienza della ricerca alla chiave primaria viene solitamente attribuito un codice univoco che identifica ciascun record del database.
Nelle applicazioni più complesse della gestione dei dati, si organizzano le informazioni in un database dotato di struttura ad → albero. Si adotta in tal caso un
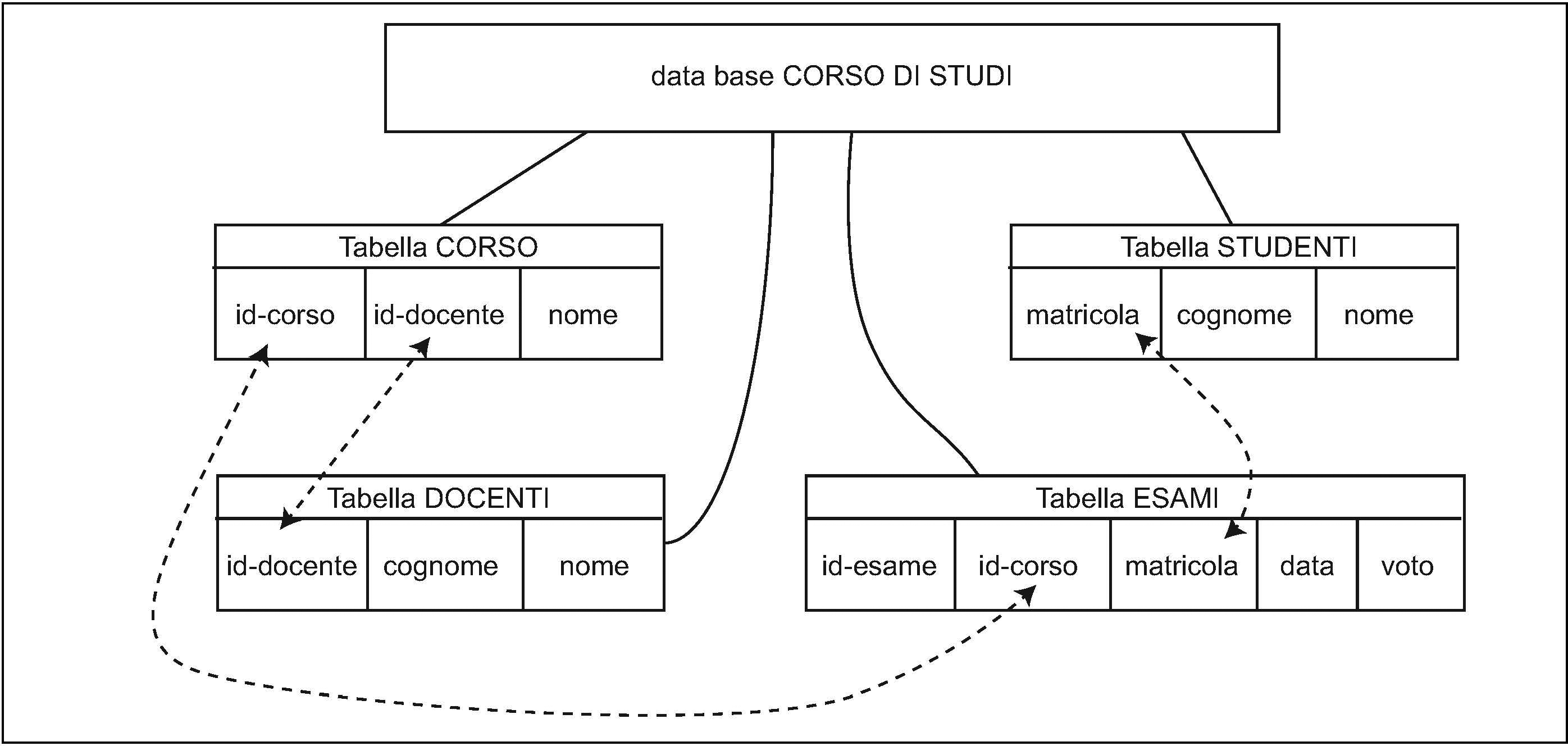
che agisce con la modalità di ricerca ad albero. Essa determina, dal valore del particolare nodo, in quale ramo dell’albero è contenuta l’informazione desiderata e quali rami debbano essere invece esclusi dalla ricerca. Il database così organizzato adotta un procedimento di indicizzazione, attraverso il quale si assegna a ogni campo chiave un codice di identificazione, appunto il suo indice. Si creano così complesse relazioni tra i vari campi del database e si ottiene alla fine un nuovo database che è possibile visualizzare sotto forma di tabelle, in cui alcuni campi di una tabella sono in relazione con quelli di altre tabelle. Il database che contiene le informazioni relative a un corso di studi può essere rappresentato in uno schema in cui le tabelle relative ai singoli corsi, ai docenti, agli studenti e agli esiti degli esami sono collegate da relazioni tra alcuni campi dei record.