
Banche dati e basi di dati
Banche dati e basi di dati
Introduzione: banche dati e basi di dati
I termini 'banca di dati' e 'base di dati' sono entrati nell'uso corrente per indicare un sistema di dati memorizzati in un elaboratore elettronico e resi disponibili per svariate operazioni, dal semplice reperimento e stampa di tabelle fino ai calcoli più complessi. Una prima domanda che può sorgere è se i due termini indichino sostanzialmente la stessa cosa. Alcuni sostengono che 'base di dati' ha una natura nettamente aziendale (indica, cioè, l'organizzazione dei dati direttamente funzionali alla pratica gestionale propria delle aziende), mentre per 'banche dati' si intendono gli organismi (privati o pubblici) che agiscono come centri di scambio e di distribuzione e operano in modo simile a quello di vere e proprie banche: ossia gli enti gestori si preoccupano di raccogliere i dati presso i produttori e di distribuirli, una volta organizzati ed eventualmente sottoposti a elaborazione, agli utenti. Altri ritengono vi sia totale coincidenza di significato tra le due espressioni, preferendo l'uso della seconda ('base di dati') per indicare che i dati sono, per l'appunto, la 'base' delle elaborazioni effettuabili nell'ambito del particolare sistema informativo che li comprende.
Un ulteriore approccio, infine, considera una banca dati come un servizio comprendente tre distinti elementi: a) la base dei dati vera e propria, costituente il cuore del sistema; b) il software, cioè l'insieme del sistema di gestione della base di dati e dei programmi sviluppati ad hoc per le particolari applicazioni elaborative; c) la rete di comunicazione, l'insieme delle strutture e dei meccanismi che rendono possibile il collegamento e l'uso dei servizi informativi offerti dalla banca dati.'Banca dati' ha quindi un significato generale, e la 'base di dati' ne è un elemento costituente: nel prosieguo ci atterremo a questa impostazione, tratteggiando le tipologie delle banche dati, e daremo brevi cenni sulla loro diffusione in Italia e nel mondo.
Tipologie delle banche dati
Le banche dati sono generalmente classificate, in primo luogo, secondo le caratteristiche dei dati in esse contenuti e le finalità delle applicazioni che su tali dati insistono. Tenendo presente il primo parametro, distinguiamo banche di dati documentali (con dati relativi ad articoli, leggi e sentenze, sommari, ecc.), banche di dati numerici (contenenti informazioni di carattere quantitativo) e banche di dati pittorici (grafici, immagini, carte geografiche). Nel primo caso hanno particolare rilevanza le problematiche legate al reperimento dei dati, spesso risolte con linguaggi di interrogazione ad hoc; nel secondo, oltre alla visualizzazione dei dati così come questi sono memorizzati, è frequente la necessità di procedere a elaborazioni dei dati, per ottenere aggregazioni, trasformazioni numeriche, correlazioni, analisi, proiezioni, ecc.; tali elaborazioni possono essere precodificate e fatte eseguire su richiesta dell'utente, oppure possono essere di tipo estemporaneo, effettuate cioè dall'utente stesso mediante i comandi del linguaggio di interrogazione. Per quanto riguarda infine le banche di dati pittorici, la tecnologia che permette la gestione, l'elaborazione e il reperimento delle immagini è ancora in fase di sviluppo, ma sono stati conseguiti alcuni interessanti risultati.
Se invece consideriamo le finalità rispetto alle quali una banca dati è alimentata e utilizzata, otteniamo la seguente distinzione: a) banche di dati gestionali; b) banche di dati statistici.I dati gestionali sono funzionali alla gestione di un'azienda o di un qualsivoglia organismo amministrativo. Un'impresa, o un ente pubblico dispone, per il raggiungimento dei propri fini istituzionali, di risorse (umane, finanziarie, materiali) e deve provvedere alla loro gestione: a questo fine occorre avere una conoscenza continua e aggiornata dello stato delle risorse, conoscenza che è assicurata dai dati collocati per l'appunto nella banca dati aziendale. In questo caso l'utenza è rigidamente definita e coincide con i responsabili della gestione aziendale ai vari livelli (strategico, di pianificazione e controllo, operativo).
I dati statistici vengono utilizzati per la descrizione e l'analisi statistica dei fenomeni di interesse (economici, demografici, sanitari, ambientali, sociali, ecc.). In una banca di dati statistici una prima distinzione può essere operata tra i dati elementari (quelli, cioè, raccolti alla fonte e memorizzati così come sono stati rilevati, detti anche microdati) e quelli aggregati (chiamati anche macrodati, risultato di qualsivoglia elaborazione che comporti una sintesi dei dati elementari). All'interno del dato aggregato si distingue ulteriormente tra l'informazione quantitativa e l'insieme dei parametri che servono a qualificarla. Ad esempio, nel dato numero di persone in età compresa tra 15 e 45 anni, di sesso maschile l'informazione quantitativa è rappresentata dal numero di persone, mentre le voci successive (età e sesso) sono i parametri qualificatori del dato. Quest'ultimo prende anche il nome di attributo di sommario, mentre i parametri sono anche detti attributi di categoria.
Ulteriori caratteristiche di una banca di dati statistici sono: a) una tipologia di dati più complessa rispetto a quella delle banche di dati gestionali, in quanto sono frequentemente presenti serie storiche di valori e quantità, numeri indici, tassi di variazione, ecc.; b) una dimensione dell'ordine delle centinaia di milioni di records; c) una notevole frequenza di valori nulli o non noti; d) la coesistenza di dati elementari e dati aggregati, dei quali spesso solo gli ultimi vengono offerti in consultazione all'utente finale, mentre i primi vengono utilizzati solo per il calcolo; e) una limitata necessità di aggiornamento dei dati, i quali, una volta inseriti e validati, si mantengono stabili nel tempo; f) una maggiore difficoltà nel predeterminare tutte le elaborazioni/aggregazioni di interesse e la conseguente necessità di disporre, a tal fine, di funzioni di lavoro flessibili.
Le basi di dati: definizione e proprietà
Una base di dati è definibile come un insieme strutturato di dati il cui contenuto risponde alle esigenze informative di molteplici utenti e la cui struttura è disegnata in modo da garantire alcune fondamentali proprietà, tra cui l'integrazione, la non ridondanza, la consistenza, la condivisione dei dati e l'indipendenza di questi dalle applicazioni.
Per integrazione dei dati intendiamo la possibilità di porre in relazione tutti i dati che siano logicamente associabili. La non ridondanza indica l'assenza, o la minimizzazione, delle duplicazioni di dati identici; la consistenza (intesa come assenza di contraddizioni tra i dati) è in gran parte una diretta conseguenza dell'eliminazione delle ridondanze: quando esistono più copie di dati aventi lo stesso significato, facilmente accade che i loro valori siano diversi, perché diversi sono i tempi e le modalità di aggiornamento; in questo caso si dice che tali valori si contraddicono e i dati sono inconsistenti. Per condivisione intendiamo la possibilità, per tutti gli utenti, di accedere agli stessi dati nello stesso momento. Infine, una importante proprietà di una base di dati è che i dati in essa contenuti devono poter essere considerati come indipendenti dalle applicazioni, presenti o future, che ne fanno uso.
Struttura per livelli di una base di dati
I dati in una base dati sono definibili secondo più livelli (almeno tre, secondo gli standard indicati dall'American National Standard Institute, ANSI): 1) livello interno, con le indicazioni relative all'organizzazione fisica dei dati; 2) livello concettuale, con la definizione del modello globale dei dati; 3) livello esterno, mediante il quale i dati sono rappresentati secondo le diverse modalità ('viste': sottoinsiemi del modello globale) con cui vengono percepiti dalle diverse classi di utenti.
Questa struttura per livelli garantisce, in primo luogo, l'indipendenza dei dati, sia tra loro che rispetto alle applicazioni: distinguiamo un'indipendenza fisica (modifiche nell'organizzazione fisica dei dati sul supporto magnetico non influiscono sul livello concettuale) e una logica (modifiche nel livello concettuale dovute all'introduzione di nuove entità e/o nuove associazioni, o alla variazione di quelle esistenti, non determinano necessariamente modifiche delle esistenti viste di utente nel livello esterno). Le applicazioni, che fanno riferimento unicamente al livello esterno, non risentono quindi delle modifiche che avvengono nei livelli più interni, con conseguente alta stabilità del sistema. Inoltre, i dati definiti secondo le esigenze dei vari utenti (mediante le 'viste') lo sono anche secondo una rappresentazione unificata (quella del modello concettuale), il che favorisce l'assenza di ridondanze e l'integrazione dei dati. Infine, la presenza di opportuni meccanismi di controllo, a livello centralizzato, permette la piena condivisibilità dei dati da parte di tutti gli utenti, assicurandone, nel contempo, l'integrità logica e fisica.
Modelli logici di organizzazione dei dati
I dati all'interno di una base di dati sono definiti secondo un preciso modello logico, scelto tra quelli che si sono venuti delineando come i modelli fondamentali: il modello gerarchico, quello reticolare e quello relazionale. Ogni modello presenta vantaggi e svantaggi rispetto ai classici problemi dell'occupazione di memoria, dell'efficienza nelle operazioni di gestione e ricerca dei dati, della semplicità nella definizione degli schemi globali e delle viste di utente. La scelta va quindi compiuta in base alle caratteristiche della base di dati che si intende disegnare e implementare e cioè la mole dei dati, la complessità delle connessioni, la natura delle applicazioni.
Il modello gerarchico. - Il modello gerarchico usa rappresentare i dati istituendo tra di essi relazioni di tipo padre-figlio. Graficamente lo schema dei dati può essere espresso da un albero, i cui nodi rappresentano i dati (o insiemi di dati raggruppati logicamente, i records): ogni nodo è figlio di un altro (tranne il nodo iniziale, detto radice dell'albero) ed è al contempo padre di uno o più altri nodi (tranne i nodi terminali, detti foglie dell'albero).
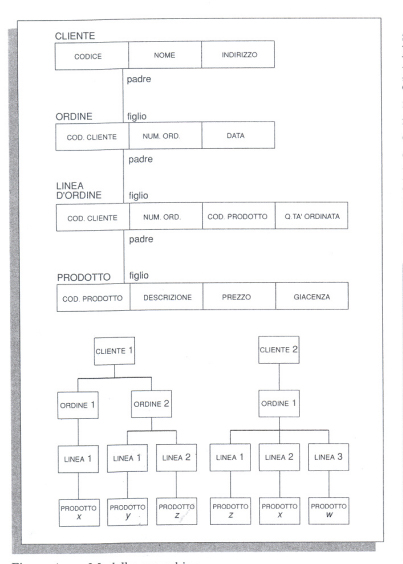
Si consideri l'esempio riportato nella fig. 1: il record ORDINE è figlio di CLIENTE e quest'ultimo è anche la radice dell'albero (non vi sono nodi di ordine superiore). A ogni cliente sono associati più ordini (rapporto uno-a-molti); lo stesso tipo di rapporto esiste tra ORDINE e LINEA D'ORDINE, mentre tra quest'ultimo e PRODOTTO esiste una relazione di tipo uno-a-uno. La scansione dei dati avviene dall'alto in basso lungo l'albero (scendendo quindi di livello) e da sinistra a destra nello stesso livello.
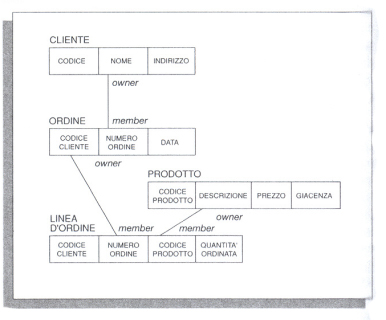
Il principale vantaggio delle strutture gerarchiche risiede nella facilità d'uso del modello in tutte le situazioni caratterizzate dalla presenza di gerarchie. Gli svantaggi risiedono principalmente nella presenza di ridondanze, nella difficoltà di mantenere l'integrità dei dati e nella dipendenza dell'efficienza dalla natura delle applicazioni, caratteristiche implicite nell'organizzazione gerarchica. Con riferimento al precedente esempio, i dati relativi a uno stesso prodotto devono essere ripetuti per tutte le linee d'ordine (che si riferiscono a quel prodotto) di ordini e clienti diversi: ciò si traduce in una notevole ridondanza. Se poi vengono cancellate tutte le linee d'ordine relative a un dato prodotto, vengono anche persi i dati relativi a quel prodotto (codice, nome, dettagli), determinando così una violazione dell'integrità dei dati. Infine, mentre è sicuramente efficiente una ricerca che preveda il reperimento dei dati su tutti i prodotti relativi a tutti gli ordini effettuati da un cliente (poiché, in questo caso, la struttura dell'albero minimizza il percorso e le scansioni necessarie), non lo è assolutamente quella che voglia ottenere i dati relativi a tutti i diversi prodotti esistenti nella base dati, indipendentemente dagli ordini e dai clienti che li richiedono, visto che in questo caso debbono essere percorsi tutti i possibili cammini dell'albero. Il modello reticolare. - Il modello reticolare rappresenta i dati secondo una struttura di tipi-records collegati da associazioni; le associazioni direttamente permesse sono del tipo uno-a-uno e uno-a-molti, ma è anche possibile definire in modo indiretto associazioni molti-a-molti. Particolare importante, un tipo-record 'figlio' (member) può avere un numero qualunque di tipi-records 'padre' (owner), a differenza del modello gerarchico, dove il padre è sempre unico. Riprendendo in esame l'esempio precedente, gli stessi dati sono ora esprimibili mediante lo schema riportato nella fig. 2.
Questa diversa organizzazione permette di superare gli svantaggi visti in precedenza per il modello gerarchico: a) non sussiste ridondanza dei dati, dal momento che l'associazione uno-a-molti tra PRODOTTO e LINEA D'ORDINE permette di introdurre una sola volta i dati relativi a un prodotto comune a tutte le linee d'ordine che vi si riferiscono; b) è possibile evitare alcune forme di violazione dell'integrità, poiché è ammessa l'esistenza di records non collegati ad altri ('sconnessi'): in altre parole, se vengono cancellate tutte le linee d'ordine relative a un prodotto, non per questo vengono persi i dati relativi a quel prodotto; c) il grado di efficienza delle applicazioni è meno variabile rispetto al caso del modello gerarchico, dato che più di un tipo-record può essere scelto come punto d'entrata nella struttura, e possono essere in tal modo evitati percorsi che costringano a visitare grandi quantità di dati.Uno svantaggio risiede nella relativa complessità della progettazione e gestione di basi reticolari di dati: infatti, la numerosità delle associazioni possibili e delle opzioni indicabili comporta un ventaglio di alternative progettuali difficilmente gestibili senza un approfondito grado di conoscenza sia del sistema-utente che del particolare sistema di gestione a disposizione.
Il modello relazionale. - Il modello relazionale si basa sui concetti di relazione, attributo, tupla e dominio.
Una relazione è una tabella a due dimensioni, composta da più colonne (attributi) e più righe (tuple), che deve osservare le seguenti proprietà: 1) ogni riga è unica, è cioè distinta da ogni altra riga per almeno il valore di una colonna (non esistono due tuple uguali); 2) ogni colonna (o attributo della relazione) ha un nome che la distingue dalle altre e l'ordine delle colonne è indifferente; 3) ogni casella (incrocio di riga e colonna) deve contenere un solo valore: in altre parole, non sono ammessi valori multipli in una tupla per un dato attributo.Il dominio è l'insieme di tutti i valori che un attributo può assumere all'interno di una relazione: ad esempio, l'attributo ETÀ nella relazione PERSONE avrà un dominio costituito da tutti i numeri interi compresi tra 0 e 120, mentre l'attributo SESSO avrà due soli valori ('maschio' e 'femmina').
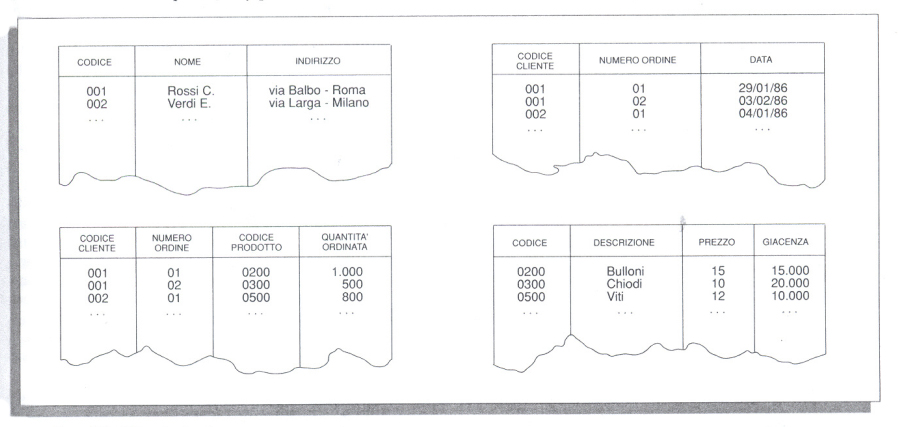
È detto chiave primaria di una relazione (o chiave unica) quell'attributo (o quell'insieme di attributi) tale che a ogni valore da esso assunto corrisponde una e una sola tupla. Per ogni relazione deve essere definita almeno una chiave primaria; se più attributi (o combinazioni) possiedono i requisiti per divenire chiavi, uno di questi è scelto come chiave primaria mentre gli altri sono detti chiavi alternative. L'esempio illustrato in precedenza può essere tradotto introducendo le seguenti relazioni (riferite alle tabelle della fig. 3):
CLIENTE (CODICE-CLIENTE, NOME, INDIRIZZO)ORDINE (CODICE-CLIENTE, NUM. ORDINE, DATA-ORDINE, IMPORTO)LINEA-ORDINE (CODICE-CLIENTE, NUM. ORDINE, CODICE-PRODOTTO, QUANTITÀ)PRODOTTO (CODICE-PRODOTTO, DESCRIZIONE, PREZZO, GIACENZA)
(il nome della relazione è quello esterno alle parentesi; all'interno di queste sono indicati gli attributi, mentre le sottolineature indicano le chiavi primarie).
Per l'interrogazione dei dati è stata introdotta un'algebra relazionale, definita da un insieme di operatori (di selezione, proiezione, unione) che, applicati secondo certe regole a una o due relazioni, ne producono una nuova che è il risultato dell'operazione. L'operatore di selezione (monadico, cioè applicabile a una sola relazione per volta) permette di ottenere tutte le tuple i cui valori soddisfino determinate condizioni (a loro volta connesse dagli operatori logici AND, OR, NOT): in sostanza, applicare questo operatore equivale a definire un sottoinsieme orizzontale della relazione considerata. Ad esempio, la seguente operazione
SELEZIONA CLIENTE CON NOME = 'Rossi' E INDIRIZZO = 'Roma'
produce, a partire dalla relazione CLIENTE, una nuova relazione contenente tutte le colonne di CLIENTE, ma solo le righe (o tuple) relative ai clienti di nome Rossi e abitanti a Roma.Al contrario, la proiezione definisce un sottoinsieme verticale di una relazione, in quanto determina l'estrazione delle colonne indicate dall'operatore (anch'esso monadico). Il seguente esempio di proiezione
PROIETTA PRODOTTO SU CODICE-PRODOTTO, GIACENZA
ha come effetto quello di determinare, a partire dalla relazione PRODOTTO, una nuova relazione contenente tutte le righe di quella d'origine, ma solo le colonne relative ai codici dei prodotti e alle relative giacenze.
L'operatore di join (o di concatenamento) combina i dati di due relazioni mediante i valori di un comune attributo (o una combinazione di attributi comuni): l'applicazione di questo operatore diadico produce una nuova relazione le cui tuple riportano i valori delle colonne sia della prima che della seconda relazione di partenza. Ad esempio, l'unione
UNISCI CLIENTE, PRODOTTO MEDIANTE CODICE-CLIENTE
produce una nuova relazione le cui colonne sono l'insieme unione delle colonne delle due relazioni di partenza; le tuple sono costruite associando a ogni tupla di CLIENTE la tupla di ORDINE che ha lo stesso codice-cliente.
Mediante l'uso congiunto degli operatori descritti, è possibile effettuare ricerche di qualsiasi complessità. Volendo ad esempio ottenere la descrizione dei prodotti richiesti dai clienti di nome Rossi, si selezionano in primo luogo le tuple di CLIENTE che contengono il valore 'Rossi' nella colonna NOME, e di queste vengono 'proiettati' i valori del codice-cliente, che sono utilizzati per selezionare la relazione LINEA-ORDINE. L'unione tra le tuple così selezionate e le corrispondenti tuple della relazione PRODOTTO serve a ottenere le descrizioni dei prodotti richiesti dai clienti di nome Rossi, che vengono infine 'proiettate' per soddisfare l'interrogazione originale.
I vantaggi del modello relazionale sono così riassumibili: a) qualora le relazioni definite nel modello siano state sottoposte a un processo di normalizzazione restano assicurate sia l'eliminazione della ridondanza dei dati che il rispetto dell'integrità dei dati; b) l'introduzione dei linguaggi di manipolazione basati sull'algebra relazionale (o sul calcolo relazionale), e caratterizzati da una notevole compattezza ed eleganza formale, rende molto semplice per l'utente il reperimento e la gestione dei dati; c) la progettazione delle basi di dati relazionali è, nello stesso tempo, rigorosa e relativamente semplice: essa si avvale della teoria della normalizzazione.
L'unico svantaggio del modello relazionale risiede nella finora limitata efficienza dei Sistemi di Gestione di Basi Dati relazionali, nel caso debbano essere trattati notevoli moli di dati. Ciò è spiegabile in quanto tanto più il modello logico è flessibile e aperto alle richieste estemporanee (e il relazionale lo è molto più del gerarchico e del reticolare), tanto meno ottimizzabili sono gli algoritmi di esecuzione delle interrogazioni e delle manipolazioni dei dati.
Il software
Abbiamo definito il software come uno degli elementi fondamentali di una banca dati, e cioè l'insieme dei programmi che permettono la memorizzazione, l'elaborazione e la distribuzione dei dati. Distinguiamo il software di base da quello applicativo. Il primo, coincidente col Sistema Operativo dell'elaboratore e col Sistema di Gestione di Basi di Dati, è predisposto dalle case di software ed è indipendente dal contenuto delle basi di dati e dalle applicazioni. Il secondo è sviluppato dai programmatori applicativi oppure direttamente dagli utenti finali con l'obiettivo di gestire e reperire i dati; a tal fine vengono utilizzati i vari linguaggi di programmazione messi a disposizione dal Sistema di Gestione.
Sistemi di Gestione di Basi di Dati
Ciò che permette la creazione, la gestione e l'utilizzo di basi di dati è un particolare software di base, che prende il nome di Sistema di Gestione di Basi di Dati (SGBD nel seguito).
I Sistemi di Gestione di Basi di Dati vengono raggruppati secondo famiglie che prendono il nome dal tipo di modello logico utilizzato per definire le connessioni tra i dati (v. § 3b): avremo quindi SGBD gerarchici, reticolari o relazionali (o misti, se esiste la possibilità di utilizzare più di un modello). I primi SGBD comparsi nel mercato (al di fuori quindi dell'ambito ristretto dei centri di ricerca) sono stati quelli di tipo gerarchico nella seconda metà degli anni sessanta (ad esempio l'IMS dell'IBM), e di tipo reticolare (le cui caratteristiche sono state determinate dal Data Base Task Group CODASYL nel 1969); da ultimi sono stati introdotti quelli relazionali, dalla metà degli anni settanta in poi.Un SGBD completo deve poter garantire le seguenti funzionalità.I. La gestione dei dati, cioè la possibilità di inserire, aggiornare, cancellare e reperire i dati in modo semplice per il singolo utente ed efficiente per il sistema nel suo complesso. A tale scopo il SGBD mette a disposizione dei programmatori applicativi e degli utenti finali dei comandi semplici e potenti, che costituiscono il linguaggio per la manipolazione dei dati.
II. L'utilizzo di un dizionario dei dati, strumento automatico e integrato per la gestione di tutte le informazioni relative ai dati contenuti nella base di dati: il significato dei dati stessi, le connessioni concettuali, l'organizzazione logica e fisica, l'indicazione delle applicazioni (procedure, programmi) che producono e/o utilizzano i dati. Il dizionario dati può essere visto come una 'base di metadati' (cioè dei dati relativi ai dati).
III. L'integrità delle transazioni: una transazione è formata da una sequenza di passi che costituiscono una data attività (ad esempio la prenotazione di un volo o l'accettazione dell'ordine di un cliente). Nell'elaborare una transazione è desiderabile che le variazioni nella base di dati siano effettivamente memorizzate se e solo se l'intera transazione è elaborata in modo corretto fino alla fine; in caso contrario, non deve essere apportata nessuna variazione, come se la transazione non fosse mai avvenuta. Ad esempio, nel caso di una transazione relativa all'accettazione dell'ordine di un cliente, se questa viene interrotta a metà (per una caduta del sistema o per altri motivi), ci si potrebbe trovare in una situazione che vede le giacenze di magazzino del prodotto ordinato decurtate della relativa quantità, senza che si sia potuto provvedere a rendere l'ordine effettivo registrandolo nell'apposito archivio: esisterebbe, a questo punto, una situazione non in linea con quella reale. Per ovviare a ciò, il SGBD controlla in primo luogo che la transazione sia andata a buon fine, e poi provvede a rendere effettive le corrispondenti variazioni dei dati.
IV. La possibilità di ripristinare la base dei dati nel caso che avvengano incidenti nel sistema di elaborazione: errori nei programmi o da parte degli operatori, rotture di dischi o di nastri, ecc. Tale possibilità viene normalmente garantita dal SGBD che permette di effettuare delle copie della base di dati a intervalli regolari (mensili, settimanali, quotidiani), unitamente al mantenimento di una traccia delle transazioni o degli aggiornamenti avvenuti tra una copia e l'altra. Nel caso di incidenti il ripristino avviene reinserendo nella base di dati la copia più recente disponibile e facendo rieseguire al sistema le transazioni avvenute dalla data della copia in poi.
V. Il controllo della concorrenza nell'accesso ai dati da parte di più utenti contemporaneamente: se due o più utenti cercano di eseguire aggiornamenti sullo stesso dato nello stesso momento, ne possono scaturire situazioni di errore. Il SGBD impedisce che ciò possa accadere mediante il meccanismo del 'blocco' del dato da parte del primo utente che vi accede: finché questi non completa la sua transazione, nessun altro è abilitato ad accedere al dato in questione.
VI. La sicurezza dei dati: il SGBD deve garantire i dati dall'accesso di persone non abilitate, distinguendo tra i diversi livelli di abilitazione, dall'accesso per la sola lettura di dati alla possibilità di effettuare aggiornamenti, inserimenti e cancellazioni di dati.
VII. La comunicazione dei dati: spesso la base dei dati è collocata in una rete di telecomunicazioni e gli utenti vi accedono per mezzo di terminali remoti. Il SGBD dev'essere in grado di gestire il flusso delle transazioni provenienti, anche simultaneamente, da ogni nodo della rete.
VIII. Il controllo dell'integrità dei dati: il SGBD offre dei servizi all'utente per porlo nella condizione di essere sicuro che i suoi dati siano 'integri', e cioè che i valori assunti dal singolo dato non contraddicano la definizione del dato stesso (siano cioè interni al suo dominio) e, nel contempo, non siano incompatibili coi valori assunti da altri dati a esso correlati. Ciò può essere fatto, ad esempio, mediante il dizionario dei dati, dichiarando per ogni dato il relativo dominio di definizione (l'arco dei valori ammissibili) e i vincoli dipendenti dai valori assunti dagli altri dati.
È da notare l'assenza, finora, di SGBD direttamente funzionali alla gestione di basi di dati statistici. A tale mancanza si sopperisce, generalmente, in due modi alternativi: 1) ricorrendo a pacchetti di analisi statistici aventi anche funzioni (meno potenti di quelle di un SGBD) di gestione dei dati; 2) utilizzando SGBD che abbiano anche funzioni di analisi dei dati (meno complete di quelle offerte dai citati pacchetti statistici).
Linguaggi per la gestione e l'interrogazione delle basi di dati
In corrispondenza dei vari livelli di una base dati visti precedentemente (esterno, relativo a come la base dati viene vista dagli utenti finali; concettuale, riportante il modello globale dei dati; interno, relativo all'organizzazione fisica dei dati) sono state definite dall'ANSI tre corrispondenti classi di linguaggi: a) i linguaggi di interrogazione (query languages), adatti all'utente finale che, disponendo di comandi semplici e potenti, può rapidamente reperire e consultare i dati di interesse: si tratta sostanzialmente di linguaggi 'dichiarativi', in quanto permettono, per l'appunto, di dichiarare cosa si vuole, evitando i dettagli relativi al come ottenerlo (sono noti, per questo, come linguaggi di quarta generazione); b) i linguaggi di manipolazione (data manipulation languages) utilizzabili dai programmatori per lo sviluppo delle applicazioni; c) i linguaggi di definizione dell'organizzazione fisica dei dati (device media control languages).
La progettazione delle basi di dati
La progettazione di una base di dati può essere suddivisa in tre momenti fondamentali: a) analisi dei requisiti, fase in cui vengono definiti i requisiti che la base di dati deve rispettare, e cioè viene effettuata una ricognizione delle necessità informative e gestionali dei futuri utenti; b) progettazione concettuale, in cui sulla base dei requisiti identificati si procede a definire i dati, le loro strutture e le loro relazioni, in modo indipendente dalle caratteristiche hardware e software dell'ambiente elaborativo; c) progettazione logicofisica, in cui sulla base della rappresentazione concettuale dei dati ottenuta nella precedente fase, e tenendo conto della tecnologia a disposizione (strutture hardware, software di base, modello logico del SGBD), si procede a definire i livelli esterno, concettuale e interno della base di dati, utilizzando il particolare linguaggio per la definizione dei dati offerto dal Sistema di Gestione.È importante tenere distinta la fase della progettazione logico-fisica da quella concettuale, in quanto la rappresentazione dei dati fornita da quest'ultima è invariante rispetto a modifiche che possono avvenire nell'ambiente elaborativo; inoltre, non essendo legata a specifiche tecniche, permette una maggiore interazione tra il progettista e l'utente.
La rete di comunicazione: basi di dati centralizzate e distribuite
La rete di comunicazione è il terzo elemento fondamentale in una banca dati. I singoli componenti di una rete di comunicazione di una banca dati ad accesso diretto sono i seguenti.Uno o più elaboratori: nel caso di più elaboratori la relazione tra essi intercorrente può essere di tipo gerarchico (un elaboratore centrale - host - ed elaboratori satelliti) o di semplice interconnessione. Nel primo caso l'host presiede al coordinamento generale della rete ed è la sede fisica della base di dati, mentre i satelliti provvedono allo smistamento locale dei dati ai terminali a essi afferenti: avremo, in questo caso, una base di dati di tipo centralizzato. Nel secondo gli elaboratori hanno tutti pari dignità e ognuno può essere sede di sottoinsiemi della base dei dati e dei programmi applicativi, configurando in tal modo una base di dati distribuita.
Il sistema di comunicazione: il sistema di gestione di una rete può essere privato o pubblico. Nella maggior parte dei paesi europei lo Stato è il gestore unico dei mezzi di comunicazione. In Italia tale compito è svolto sia da enti pubblici (Ministero PP.TT.) che privati a partecipazione statale (Sip, Italcable, Telespazio, ecc.). Oltre alle normali linee telefoniche è possibile affittare linee specializzate per la trasmissione dei dati (Rete Fonia Dati e ITAPAC).
I terminali: la tendenza attuale vede il passaggio da semplici unità di immissione/emissione dati a unità intelligenti, come i personal computers dotati di schede di comunicazione, che permettono di effettuare elaborazioni aggiuntive sui dati selezionati.
Si è accennato alle basi di dati distribuite, che si hanno quando esistono, presso più elaboratori collegati, archivi di dati che fanno logicamente parte di un'unica base di dati. Tale soluzione può essere preferita a quella di una base di dati centralizzata (dati presso un unico elaboratore), quando si verificano una o più delle seguenti condizioni: le elaborazioni possono essere effettuate in modo decentrato presso i singoli nodi; i costi di comunicazione sono relativamente alti rispetto a quelli che comporterebbe l'acquisto di elaboratori aggiuntivi; i tempi di risposta sono alti soprattutto a causa del traffico nella rete; si ha interesse alla maggiore affidabilità presentata da una soluzione distribuita, nella quale il blocco di un elaboratore non comporta il blocco dell'intero sistema, ma solo del nodo in cui l'elaboratore è situato.
La scelta di immettere più nodi elaborativi nella rete, anziché limitarsi a uno, ha come effetto quello di diminuire il traffico complessivo dei dati, riducendo così i costi di comunicazione e migliorando i tempi di risposta.
Una base dati distribuita comporta un aumento di complessità dei problemi relativi alla progettazione: citiamo a titolo d'esempio quelli relativi all'allocazione ottimale dei dati e dei programmi presso i vari nodi. A livello di gestione, infine, ricordiamo il problema rappresentato dall'aggiornamento in tempo reale di dati memorizzati in nodi elaborativi diversi.
Diffusione delle banche dati
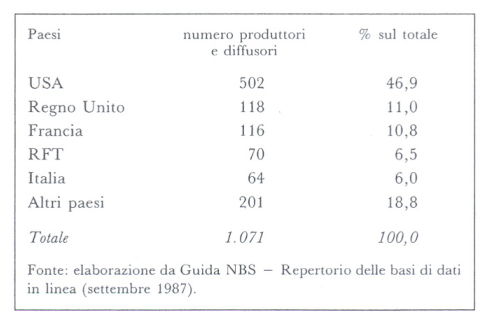
Una misura della tendenza alla crescita dell'offerta di informazioni attraverso le banche dati è data dal notevole aumento del numero di produttori e diffusori nel mondo: da circa 200 nel 1983 si è giunti a superare il migliaio nel 1987. In particolare, la distribuzione per paese è data dalla seguente tabella. Come si vede, una posizione predominante è occupata dagli Stati Uniti (quasi la metà dei produttori e diffusori è situata in quel paese) seguiti dai principali paesi europei. Tra gli 'altri paesi' un ruolo di rilievo è svolto da Canada, Australia e Paesi Scandinavi. In Italia 138 banche dati sono offerte in consultazione da 64 enti: tra i più importanti citiamo ANSA, Assolombarda, Camera dei Deputati, Cerved, Cilea, Cineca, Confindustria, Corte di Cassazione, ISTAT, Istituto per il Commercio con l'Estero, Nielsen Italia, Pitagora, Sarin.
Per quanto riguarda il contenuto informativo delle banche dati attualmente in distribuzione, è possibile distinguere nel modo seguente gli argomenti trattati. Scientifici e tecnologici: aeronautica, alimentazione, astronautica, biologia, biomedicina, biometria, biotecnologia, chimica pura e applicata, economia, elettronica, farmacologia, fisica pura e applicata, informatica, ingegneria, intelligenza artificiale, linguistica, matematica, meccanica quantistica, medicina, pedagogia, psicologia e psichiatria, robotica, scienze nucleari, tossicologia, urbanistica, veterinaria, zoologia.
Aziendali, industriali, settoriali: industria agricola, dell'automobile, dell'aviazione, aerospaziale, brevetti, commercio interno e internazionale, contabilità, edilizia, energia, fiere ed esposizioni, investimenti finanziari, istituti finanziari, bancari e di credito, marchi di fabbrica, marketing, materie plastiche, metalli e metallurgia, miniere, navigazione marittima, organizzazione aziendale, petrolio, prodotti industriali, pubblicità, tassazione, tessili e industria dell'abbigliamento, trasporti.
Ambientali, demografici, politici e sociali: ambiente, demografia e popolazione, ecologia, etnologia, formazione professionale, infanzia, lavoro e salari, paesi in via di sviluppo, politica e scienze politiche, sanità, servizi sociali, sicurezza sul lavoro, società, sociologia, tempo libero.
Bibliografici: almanacchi, bibliografie nazionali, enciclopedie, guide e annuari.
Vari: cinema, difesa, filosofia, fotografia, letteratura, meteorologia, moda, spettacolo, storia, studi sulla donna, televisione, turismo.
Come si vede, ben pochi sono gli argomenti non trattati dalle banche dati, verso le quali si indirizzano differenti tipologie di utenti, dalle istituzioni governative alle aziende, dalle università ai ricercatori, ai singoli cittadini, nell'ottica di pianificare, gestire, indagare o semplicemente conoscere.
Le applicazioni nella pubblica amministrazione
L'uso delle basi di dati è ormai largamente diffuso all'interno della pubblica amministrazione, sia centrale che periferica. A livello di enti locali, i comuni gestiscono le anagrafi utilizzando sempre più tale tecnologia: questo è vero soprattutto per i grandi centri, che gestiscono in linea milioni di informazioni riguardanti i cittadini residenti, ma anche nei comuni di limitata ampiezza demografica si giudica conveniente automatizzare le procedure anagrafiche ricorrendo alle basi di dati.
Nell'amministrazione centrale esistono, o sono in via di realizzazione, sistemi informativi imperniati su basi di dati in settori di fondamentale importanza, come quelli riguardanti la gestione delle imposte, del catasto, delle posizioni assistenziali e previdenziali, ecc.
L'istituzione dell'anagrafe tributaria, decisa nel 1976, prevederà, a regime, l'automazione di tutte le procedure relative a: imposte dirette, IVA e registro; conservatorie; catasto terreni, catasto fabbricati e catasto geometrico; contenzioso; dogane; demanio.Per quanto riguarda la gestione delle imposte dirette, che costituiscono il 'cuore' del sistema, sono state implementate basi di dati riportanti informazioni sulle persone fisiche e giuridiche soggetto d'imposta: codice fiscale, dati anagrafici e residenza, redditi dichiarati, volume d'affari, versamenti di autoliquidazione (IRPEF, ILOR, IVA), rimborsi IRPEF e IVA, verifiche della Guardia di Finanza, accertamenti, sanzioni per infrazioni IVA, compensi a professionisti dichiarati da società ed enti, dividendi e utili di società ed enti, compravendita di immobili, successioni, mutui, appalti, leasing, ecc.Alle basi di dati in questione sono collegati oltre mille uffici finanziari dislocati in tutta Italia, che effettuano oltre 400.000 operazioni interattive al giorno. Secondo il Ministero delle Finanze, il flusso informativo dei documenti acquisiti annualmente riguarda: 25 milioni di dichiarazioni dei redditi; 5 milioni di dichiarazioni IVA; 3 milioni di atti di registro; 2 milioni di ritenute d'acconto sui dividendi; 40 milioni di versamenti di autotassazione IRPEF, ILOR e IVA; 4 milioni di rimborsi IRPEF; 5 milioni di variazioni anagrafiche; 5 milioni di documenti di cassa IVA e registro; 2 milioni di comunicazioni da comuni, camere di commercio e albi professionali; 17 milioni di concessioni governative e affitti; 2 milioni di compravendite di auto e moto.In tal modo il sistema assicura il controllo automatico delle dichiarazioni annuali dei redditi e dell'IVA (con segnalazione delle anomalie agli uffici) e dei versamenti per autotassazione, e l'emissione dei rimborsi d'imposta. Negli ultimi anni gran parte delle manovre di politica fiscale (revisione della curva delle aliquote IRPEF, accorpamento delle aliquote IVA) si è basata sull'analisi delle informazioni contenute nel sistema. Per quanto riguarda la lotta all'evasione, l'anagrafe tributaria produce analisi statistiche che permettono di individuare i settori verso i quali indirizzare le indagini; in particolare, vengono prodotte liste di segnalazioni di nominativi (sulla base di criteri definiti di selezione) che vengono inviate agli uffici della Guardia di Finanza per l'effettuazione di circa il 30% degli accertamenti. Per il restante 70% si fa comunque uso delle informazioni contenute nelle basi di dati (oltre 5.000 interrogazioni giornaliere).Un altro settore di importanza fondamentale nella vita sociale del paese è quello della gestione delle posizioni previdenziali e assistenziali. L'INPS, l'ente di maggior rilievo in questo campo, raccoglie i dati relativi a milioni di pensionati, lavoratori (dipendenti e non) e aziende, e li organizza in archivi tradizionali o in basi di dati di tipo gerarchico o relazionale. Ad esempio, una base di dati centralizzata a livello nazionale riporta le notizie relative a 15.900.000 pensioni erogate dall'INPS, unitamente a 5.100.000 posizioni per prestazioni erogate da altri enti e a 6 milioni di posizioni non attive, per un totale quindi di 27 milioni di unità di informazioni relative alla natura e alla decorrenza delle singole pensioni, all'importo dei pagamenti, agli uffici pagatori, ecc.
Altre basi di dati gestite dall'INPS riguardano: le aziende che occupano lavoratori dipendenti non agricoli (circa 1,2 milioni di registrazioni); i lavoratori dipendenti non agricoli (12 milioni di records); gli artigiani e i coadiuvanti familiari (3,1 milioni di records); i commercianti e i coadiuvanti familiari (2,6 milioni di posizioni); i lavoratori agricoli dipendenti (4,1 milioni di posizioni di cui 1,2 attive); i coltivatori diretti, i mezzadri e i coloni (5,4 milioni di posizioni, di cui 1,2 attive); i liberi professionisti (1,3 milioni di records); i lavoratori domestici e i relativi datori di lavoro (rispettivamente 1,4 e 1,8 milioni di records).
Tra le applicazioni amministrative pubbliche, un ruolo di rilievo spetta alla cosiddetta 'banca dati di polizia', per la delicatezza delle informazioni in essa contenute e per la particolare tutela che la legge ha imposto al reperimento, al trattamento e all'uso dei dati in essa contenuti. La legge n. 121 del 1981 ha infatti stabilito che i dati e le informazioni sul conto di persone possano essere raccolti esclusivamente per fini di tutela dell'ordine pubblico e per la prevenzione e la repressione della criminalità, escludendo quindi ogni altra finalità. Tali informazioni sono accessibili, oltre che alle forze di polizia, ai servizi di informazione e sicurezza dello Stato e, entro certi limiti, all'autorità giudiziaria, e non possono essere comunicate ad altri organismi o persone (neanche se facenti parte della pubblica amministrazione) pena severe sanzioni penali. Questa materia chiama direttamente in causa il problema della riservatezza dei dati, trattato nel capitolo seguente.
La riservatezza dei dati
La notevole diffusione delle banche dati ha oggettivamente aumentato la possibilità di violazione del diritto dei cittadini alla privacy. Infatti, grazie alla relativa facilità di collegamento dei dati contenuti in ambienti diversi, e raccolti con fini diversi, è più agevole venire in possesso di informazioni anche riservate, relative a singoli individui o a unità produttive. Ad esempio, i dati anagrafici di una persona possono essere posti a confronto con quelli fiscali, sanitari, previdenziali o altro, ottenendo un'informazione complessiva di cui la persona in questione può non desiderare la divulgazione.
La violazione della riservatezza dei dati può essere diretta o indiretta.È diretta quando è immediatamente possibile identificare l'entità cui i dati sono riferiti, e ciò può avvenire sia per i dati individuali che per quelli aggregati. Nel caso di dati individuali la violazione è possibile quando tali dati sono corredati di chiavi identificative (codici, nomi, indirizzi, ecc.), oppure deviano in modo tale dalla norma che sono immediatamente riferibili all'entità da cui derivano; nel caso di dati aggregati (ad esempio tavole riportanti distribuzioni di frequenze) alcune particolari caratteristiche delle distribuzioni (come la scarsa numerosità delle frequenze rientranti in alcune caselle) possono consentire l'identificazione degli individui cui queste sono riferite.
La violazione è invece indiretta quando, pur non sussistendo le condizioni già elencate, attraverso una sequenza di operazioni di selezione e confronto dei dati è possibile comunque giungere a identificare le singole entità cui tali dati sono riferiti.
È possibile premunirsi contro il primo tipo di violazione della riservatezza: per i dati individuali, mediante l''oscuramento' dei valori delle chiavi identificative (resi inaccessibili all'utente esterno della banca dati) e il divieto di accesso a dati che, essendo riferiti a unità al di fuori della norma, ne permetterebbero l'identificazione; per i dati aggregati, mediante l'impossibilità di accedere a distribuzioni di frequenza in cui compaiono valori molto bassi (in genere sotto le 4 o 5 unità), oppure mediante il loro mascheramento con una trasformazione casuale di tali frequenze (operata mediante tecniche di randomizzazione), condotta rispettando il vincolo della rispondenza effettiva dei dati a livello dei totali sia parziali che complessivi.Molto più complesso è il problema della protezione dal secondo tipo di violazione. In questo campo la ricerca è ancora aperta e viene condotta soprattutto nei paesi anglosassoni (in particolare Regno Unito e Canada). (Nella stesura dell'articolo l'autore si è avvalso della collaborazione del dott. Giulio Barcaroli, dell'ISTAT). (V. anche Informatica).
Bibliografia
Albano, A., Orsini, R., Basi di dati, Torino 1985.
Atzeni, P., Batini, C., De Antonellis, V., La teoria relazionale dei dati, Torino 1986.
Batini, C., De Petra, G., Lenzerini, M., Santucci, G., La progettazione concettuale dei dati, Milano 1986.
Bracchi, G., Martella, G., Pelagatti, G., Sistemi per la gestione di basi di dati, Milano 1979.
Chen, P., The entity-relationship model. Towards an unified view of data, in "ACM transactions on database systems", 1976, I, 1, pp. 9-36.
Codd, E. F., A relational model for large shared data bases, in "Communication", 1970, XIII, 6, pp. 377-387.
Date, C., An introduction to database systems, Reading, Mass., 1986⁴.
Mc Fadden, F. R., Hoffer, J. A., Data base management, Menlo Park, Cal., 1985.
Martin, J., Principles of data base management, Englewood Cliffs, N. J., 1975.
Teorey, T. J., Fry, J. P., Design of database structures, Englewood Cliffs, N. J., 1982.