
Biologia molecolare
Biologia molecolare
sommario: 1. Introduzione. 2. Struttura degli acidi nucleici e delle proteine: a) struttura primaria degli acidi nucleici; b) struttura secondaria degli acidi nucleici; c) struttura terziaria degli acidi nucleici; d) struttura delle proteine. 3. Struttura dei complessi sopramolecolari: a) i cromosomi; b) i ribosomi; c) le membrane. 4. La replicazione del DNA. 5. Espressione dei geni: a) trascrizione; b) maturazione dei prodotti di trascrizione; c) splicing; d) maturazione alle estremità; e) modificazioni di basi. 6. Codice genetico e sintesi proteica. 7. Regolazione genica, differenziamento e sviluppo. 8. Elementi genetici mobili e riarrangiamenti nei geni degli anticorpi.9. Segnalazioni fra ed entro le cellule. 10. Oncogeni. 11. Ingegneria genetica: a) sintesi di geni; b) endonucleasi di restrizione; c) vettori e sistemi di trapianto genico. 12. Conclusioni. □ Bibliografia.
1. Introduzione
La biologia molecolare è una disciplina diretta alla comprensione del fenomeno ‛vita' attraverso lo studio delle macromolecole biologiche (soprattutto degli acidi nucleici e delle proteine), dei meccanismi che ne regolano il funzionamento e ne causano le disfunzioni, e delle interazioni che avvengono entro e tra le cellule che le contengono.
Rispetto all'approccio descrittivo e tassonomico, proprio della biologia sino alla prima metà del secolo, la biologia molecolare si caratterizza per un'impostazione prevalentemente chimico-fisica e matematico-quantitativa. Questa è stata resa possibile da una serie di innovazioni e scoperte di cui alcune hanno avuto luogo nel secolo scorso, ma hanno esercitato un impatto significativo sulla ricerca solo in questo secolo. In realtà è a partire dagli anni quaranta che ha incominciato a svilupparsi una biologia contraddistinta da elevate potenzialità di generalizzazione, di predizione e di intervento qual è l'attuale biologia molecolare.
Le scoperte che hanno permesso questa rivoluzione sono di natura sia concettuale sia metodologica: fra quelle concettualmente più importanti, di particolare rilevanza è stata la scoperta del ruolo del gene come elemento centrale della cellula e come substrato fondamentale della trasmissione dei caratteri ereditari e dell'evoluzione naturale, e successivamente la sua localizzazione nella doppia elica del DNA; quindi la chiarificazione della sua struttura, del meccanismo della sua replicazione e della sua decodificazione in RNA e proteine.
Dal punto di vista metodologico uno dei contributi più significativi è stato l'adozione di criteri quantitativi nella trattazione dei problemi biologici in generale e genetici in particolare. A sua volta questa è stata favorita soprattutto dall'interesse di numerosi fisici che, a partire dagli anni quaranta, anche in risposta alla domanda contenuta nel titolo del libro di E. Schrödinger Che cosa è la vita?, si sono rivolti allo studio di sistemi biologici.
Pure fondamentali sono stati i contributi di biochimici e cristallografi che, isolando e caratterizzando i principali componenti cellulari, ne hanno permesso uno studio strutturale che si è rivelato essenziale per la comprensione delle loro funzioni e relazioni. Una svolta di enorme importanza si è avuta di recente con la messa a punto delle procedure per la donazione molecolare dei geni, che hanno permesso un'esauriente descrizione non solo delle cellule microbiche ma anche di quelle superiori e dei principali processi che ne regolano le funzioni. Sono diventate così disponibili elevate quantità di geni e di prodotti genici altrimenti insufficienti per le esigenze di studi sistematici e integrati, il cui avvio è di questi ultimi anni, ma che già hanno portato a risultati entusiasmanti, di alcuni dei quali diamo una descrizione schematica in queste pagine.
2. Struttura degli acidi nucleici e delle proteine
Gli acidi nucleici e le proteine sono le macromolecole più importanti della cellula vivente (v. tab. I): forse un po' semplicisticamente si può dire che i primi sono i responsabili delle sue proprietà genetiche, le seconde di quelle biochimiche. Particolarmente rilevanti sono le funzioni di uno dei due acidi nucleici, detto DNA, o acido desossiribonucleico: nei sistemi superiori o eucariotici esso è contenuto nel nucleo (nei Mammiferi assomma a qualche picogrammo o milionesimo di milionesimo di grammo per nucleo) ed è separato dal citoplasma per mezzo di una doppia membrana porosa, detta ‛nucleare'; è presente anche negli organelli cellulari (mitocondri e cloroplasti) e talvolta anche nel citoplasma, sotto forma di elementi genetici autonomi e accessori, detti ‛plasmidi'. Nei sistemi procariotici il DNA è distinto ma fisicamente non separato dal citoplasma e dà origine a una struttura detta ‛nucleoide': nel citoplasma sono piuttosto frequenti i plasmidi. Nei virus, che possono presentare come materiale genetico DNA o RNA (acido ribonucleico), gli acidi nucleici sono contenuti all'interno del capside, o involucro, della particella virale, detta anche ‛virione'.
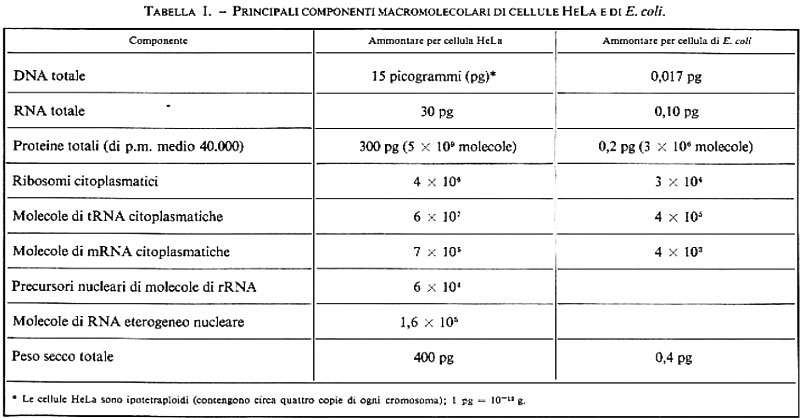
Tanto gli acidi nucleici quanto le proteine sono macromolecole lineari, risultanti dalla condensazione testa-coda di precursori attivati: i nucleotidi trifosfati, nel caso degli acidi nucleici, e gli amminoacil-tRNA, nel caso delle proteine. Esiste una correlazione diretta tra la successione dei nucleotidi e quella degli amminoacidi: questa relazione è imposta dal meccanismo di sintesi proteica ed è governata dal codice genetico (v. cap. 6).
Perché queste macromolecole svolgano le loro funzioni le strutture lineari devono essere organizzate in una serie di sovrastrutture, la cui comparsa richiede talvolta l'interazione, mediata da legami deboli, di più molecole o dello stesso tipo o di tipo diverso. Si possono individuare diversi livelli organizzativi: si hanno così strutture primarie, secondarie, terziarie. Nel caso delle proteine si è individuata anche una struttura quaternaria.
a) Struttura primaria degli acidi nucleici
Gli acidi nucleici sono costituiti dalla successione dei nucleotidi uniti fra loro con legame fosfodiesterico: procedendo lungo la doppia elica del DNA in uno dei due sensi, un filamento presenta polarità 5′ → 3′ nel legame fosfodiesterico, mentre l'altro filamento presenta la polarità opposta (3′ → 5′). Nella doppia elica le sequenze nucleotidiche delle due catene sono complementari: la sequenza di una catena determina la sequenza dell'altra secondo le regole di Chargaff, per cui A (adenina) si appaia con T (timina) e G (guanina) con C (citosina). Le sequenze nucleotidiche non sono né ripetitive né casuali: esse seguono un ordine imposto dalla necessità di soddisfare le richieste strutturali e funzionali del DNA e dalla sua composizione nucleotidica totale. Mentre nei procarioti questa varia moltissimo, andando da un 30% di G + C, in Clostridium perfringens a un 67% di G + C, in Mycobacterium tuberculosis, negli organismi eucariotici le oscillazioni sono più ridotte (45 ÷ 55% di G + C).
In numerosi genomi eucariotici esistono tratti a sequenza nucleotidica molto semplice: in certe specie di crostacei se ne trovano alcuni lunghi migliaia di coppie di basi costituiti per oltre il 97% dalla successione del dinucleotide A-T. Le sequenze ripetitive possono rappresentare frazioni molto cospicue del DNA totale di un eucariote, arrivando sino al 60%; ciò nonostante, la loro funzione è ancora largamente ignota. Possono essere divise in altamente (fino a decine di milioni di volte) e mediamente (fino a centinaia di migliaia di volte) ripetitive; in mezzo a esse sono disperse le sequenze dette uniche e le scarsamente ripetitive (queste ultime sono spesso raggruppate in ‛famiglie di geni'), che corrispondono ai geni che codificano per proteine.
Sempre negli eucarioti sono stati individuati tratti di DNA composti da diverse decine di A: essi seguono in generale sequenze geniche, che non vengono però trascritte in RNA messaggeri. Si tratta dei cosiddetti ‛pseudogeni' e ‛geni processati' che derivano dalla retrotrascrizione di RNA messaggeri, giunti a diverso grado di maturazione, in filamenti di DNA che vengono poi convertiti in doppie eliche e quindi integrati in vari punti del genoma. Non si sa se gli pseudogeni e in generale queste sequenze retrotrascritte rappresentino materiale genico in via di eliminazione, oppure sequenze di riserva, destinate a evolversi in strutture funzionali. È probabile che siano vere entrambe le ipotesi.
Oggi conosciamo la struttura primaria di diverse migliaia di geni e di numerosi genomi virali: il genoma più lungo sequenziato per intero è forse quello del cloroplasto di tabacco, composto da 155.844 basi (v. Shinozaki e altri, 1986). Queste sequenze derivano sia da eucarioti che da procarioti e complessivamente ammontano a oltre 16 milioni di basi. La velocità con cui vengono acquisite aumenta di anno in anno, grazie al concorso di diversi fattori favorevoli.
La diffusione e la maggiore efficienza sia delle tecniche di sequenziamento del DNA, sia delle procedure di donazione genica (v. sotto) essenziali per ottenere frammenti di DNA puri e in quantità elevate, sia del software per l'immagazzinamento e la rielaborazione dei dati al calcolatore, hanno raggiunto un livello tale per cui è possibile oggi considerare con un certo realismo un'impresa inconcepibile sino a solo pochi anni fa: ottenere la sequenza completa di un genoma umano lungo oltre tre miliardi di coppie di basi nell'assetto aploide (v. Van Dilla e altri, 1986).
Per anni risolvere la struttura primaria di un tratto di DNA è stata un'impresa tra le più difficili in biologia molecolare: si poteva cercare di risolvere la sequenza in amminoacidi della proteina corrispondente, ma anche questo richiedeva una metodologia abbastanza sofisticata. L'altra via per derivare indirettamente sequenze di DNA passava attraverso la risoluzione dei loro prodotti di trascrizione, cioè gli RNA. Negli anni sessanta lo studio della sequenza degli RNA ha goduto di particolare favore, soprattutto per quel che riguarda gli RNA cosiddetti abbondanti e stabili (cioè i ribosomici, o rRNA, e, in particolare, i più corti transfer RNA o tRNA, purificabili con rese molto più alte rispetto agli RNA messaggeri o mRNA). Da quasi dieci anni a questa parte è invece di gran lunga preferibile sequenziare direttamente il gene e attraverso il codice genetico ottenere poi la sequenza dell'eventuale prodotto proteico. Due sono le procedure messe a punto per risolvere la struttura primaria del DNA: una si basa su reazioni chimiche specifiche per la rottura del legame fosfodiesterico a monte (5′) di ciascuno dei 4 nucleotidi, l'altra utilizza reazioni enzimatiche che portano all'interruzione della reazione di copiatura delle sequenze ignote, in seguito all'incorporazione di analoghi dei precursori (detti didesossiribonucleotidi) che, in quanto sprovvisti del gruppo ossidrile (OH) in 3′, fungono da terminatori della reazione di copiatura.
Il principio fondamentale di entrambe le procedure è quello di controllare le reazioni di degradazione o di copiatura in modo tale da ottenere una rappresentazione di tutti i frammenti del tratto di DNA la cui sequenza si vuole risolvere: da quello lungo un solo nucleotide a quello lungo quanto tutto il segmento originale. Questa miscela di frammenti, di lunghezze che differiscono quindi per un solo nucleotide, può venire separata per elettroforesi ad alto voltaggio su gel di poliacrilammide, che permette di ordinarli secondo la loro lunghezza. Siccome si conoscono i tipi di reazioni usate per produrre i frammenti, e questi sono marcati a una delle estremità per mezzo di radioisotopi oppure con coloranti (che possono anche essere quattro, diversi fra loro), l'ispezione visiva o, più recentemente, l'analisi automatizzata del profilo elettroforetico danno direttamente la struttura primaria del segmento in esame. Dall'individuazione dei segmenti adiacenti e parzialmente sovrapposti si ottiene la struttura di tratti sempre più lunghi di DNA.
Queste tecniche sono state elaborate nella seconda metà degli anni settanta: nel laboratorio di W. Gilbert a Cambridge, Mass., è stato messo a punto il metodo chimico, nel laboratorio di F. Sanger a Cambridge, Inghilterra, è stato sviluppato il metodo enzimatico. A entrambi i ricercatori è stato conferito nel 1982 il premio Nobel per la chimica, dopo che Sanger l'aveva già vinto nel 1953 per la risoluzione della struttura primaria di una proteina, l'insulina.
Dall'analisi di migliaia di geni diversi è stato possibile derivare utili correlazioni tra sequenze e funzioni: per esempio è possibile identificare immediatamente le sequenze codificatrici dei geni strutturali (dette anche ‛fasi di lettura aperte'), le sequenze che fungono da segnali di inizio, di terminazione e di potenziamento della trascrizione, e le sequenze che interrompono la continuità dei geni strutturali degli eucarioti, dette ‛introni', rispetto alle sequenze, dette ‛esoni' (v. cap. 5, § c), che concorrono a formare gli RNA messaggeri maturi e che poi vengono tradotte in proteine. Progressi cospicui si stanno anche facendo per quel che riguarda l'analisi delle sequenze che regolano l'inizio e la terminazione della replicazione dei cromosomi (v. cap. 4). Le sequenze dei geni risolte in numerosissimi laboratori sparsi per il mondo sono immagazzinate in svariate banche-dati, tra cui le più fornite e aggiornate sono quella del Laboratorio Europeo di Biologia Molecolare (EMBL) di Heidelberg e l'americana GenBank. La conoscenza della struttura primaria del DNA è alla base della comprensione delle funzioni dei geni e della loro organizzazione nei cromosomi: è infatti molto probabile che, in modo diretto o indiretto e attraverso meccanismi d'azione prossimali o distali, la struttura primaria del DNA determini tutte le reazioni di riconoscimento da parte delle macromolecole e dei metaboliti cellulari, oltre che delle molecole extracellulari, che interagiscono con esso e ne regolano le complesse funzioni.
b) Struttura secondaria degli acidi nucleici
La struttura secondaria degli acidi nucleici è stata determinata agli inizi degli anni sessanta da Watson e Crick, che hanno saputo combinare misure di diffrazione di raggi X, eseguite da Wilkins (i tre vinsero insieme il premio Nobel nel 1962) e Franklin, dati di composizione nucleotidica di numerosi DNA, ottenuti da Chargaff, e modelli proposti da Pauling e altri per le proteine. Essa è costituita da due catene di DNA antiparallele, avvolte una attorno all'altra ('plectonemiche') e separate l'una dall'altra da solchi alternativamente grandi e piccoli. Ne risulta un cilindro con asse prevalentemente diritto, la cui superficie è formata dai gruppi fosforici. L'interno è pieno e costituito dalle basi dei nucleotidi che compongono i due filamenti, appaiate mediante legami a idrogeno e impilate le une sulle altre grazie a legami idrofobici. Esistono diverse forme di strutture secondarie, in cui variano il passo dell'elica, l'angolo delle basi e altri parametri (v. tab. II). Tra queste di particolare interesse è la forma detta Z, che differisce da tutte le altre per l'andamento sinistrorso (angolo di rotazione negativo) anziché destrorso; è anche l'unica normalmente immunogenica, e può quindi essere riconosciuta in vivo, mediante anticorpi specifici. Si ritiene rappresenti un segnale per la trascrizione di geni adiacenti o distanziati; è indotta da alta concentrazione di sali ed è facilitata, ma non determinata, da sequenze alternate purine/pirimidine. Uno dei problemi che interessano di più gli strutturisti del DNA è la chiarificazione della struttura del tratto che separa segmenti a forma B e Z: si ritiene, infatti, che origini una struttura ‛paranemica', a catene non intrecciate ma accostate (v. Kang e Wells, 1985).

Le informazioni che si possono ricavare dagli studi delle strutture secondarie del DNA e della transizione da singola a doppia elica riguardano, per esempio, la composizione in basi o l'organizzazione generale delle sequenze. A parità di condizioni, la stabilità termica è funzione lineare e positiva del contenuto in G + C. Molto utili sono i dati relativi alla velocità con cui si riforma la doppia elica (rinaturazione) a partire dai due filamenti dissociati: sono stati infatti studi di cinetica di rinaturazione a rivelare la presenza di sequenze ripetitive nel DNA degli eucarioti.
c) Struttura terziaria degli acidi nucleici
La natura dei legami chimici che costituiscono i singoli filamenti di DNA e ne determinano l'appaiamento nelle strutture secondarie a doppia elica è tale per cui la struttura energeticamente più favorita è quella che porta un filamento ad avvolgersi attorno all'altro nelle modalità della doppia elica destrorsa di forma B, con le caratteristiche di regolarità descritte nel paragrafo precedente e nella tab. II. In teoria le molecole di DNA possono però presentare un numero di avvolgimenti maggiore o minore rispetto a quello previsto, che è pari a un avvolgimento ogni 10,5 coppie di basi: si dice allora che il DNA è dotato di una struttura terziaria superelicoidale. In natura essa è dovuta a una carenza di avvolgimenti, generalmente calcolata nella misura di uno ogni 20; il superavvolgimento che ne deriva si manifesta in modi diversi: nelle molecole circolari (per es. nei plasmidi) la struttura è più compatta e viene visualizzata facilmente al microscopio elettronico.
Il superavvolgimento può essere misurato mediante tecniche diverse, quali l'elettroforesi e la velocità di sedimentazione. Nelle cellule sia eucariotiche sia procariotiche esistono enzimi in grado di introdurre e di eliminare superavvolgimenti di DNA: questi enzimi sono chiamati ‛topoisomerasi', in quanto capaci di variare il numero dei superavvolgimenti in molecole altrimenti identiche (topoisomeri).
Per quel che riguarda il significato biologico della struttura superelicoidale, pare che la sua presenza sia essenziale per l'impaccamento del DNA nelle cellule e anche perché avvengano certe reazioni sul DNA che richiedono una parziale esposizione delle singole eliche (per es. l'integrazione lisogenica del DNA del fago lambda nel cromosoma del batterio ospite, E. coli), o per il funzionamento ottimale di certe sequenze attive nel processo di trascrizione, anche in molecole lineari, quale per es. il DNA del fago T7 di E. coli.
Altri tipi di struttura terziaria riscontrati negli acidi nucleici sono le cosiddette ‛forcine' e le strutture ‛a croce'. Esse sono dovute alla presenza di sequenze nucleotidiche invertite e permettono a un singolo filamento di assumere una struttura a doppia elica formata dai due tratti a sequenze complementari, mentre il tratto di sequenza da essi delimitato forma la capocchia della forcina. Assetti conformazionali del tipo a forcina sono spesso presenti in molecole di transfer RNA e in generale di RNA.
Strutture del tipo a croce si riscontrano facilmente, almeno in teoria, in corrispondenza delle zone di DNA dove avviene l'inizio della replicazione, per esempio nei DNA dei virus batterici G4 e lambda e nel DNA di E. coli (v. cap. 4).
Un'interessante struttura terziaria che potrebbe caratterizzare le origini della replicazione del DNA sia nei procarioti che negli eucarioti è stata riscontrata in brevi regioni contenenti tratti a sequenza C(A)3-5T, separati da circa 10 basi: in corrispondenza di queste sequenze, ripetute diverse volte, e quindi battezzate ‛iteroni', la doppia elica presenterebbe una piegatura statica che negli eucarioti è priva di nucleosomi ed è forse attaccata alla matrice nucleare, e che, in generale, potrebbe essere riconosciuta da proteine specifiche per l'impaccamento, per la replicazione e/o la trascrizione (v. Snyder e altri, 1986).
d) Struttura delle proteine
Le proteine e i polipeptidi sono costituiti da una successione di amminoacidi: in natura questi sono di norma 20 e polimerizzano in un processo di condensazione, chiamato ‛sintesi proteica', descritto più avanti (v. cap. 6). Anche nel caso delle proteine è la sequenza degli amminoacidi lungo la catena polipeptidica che determina la struttura finale del prodotto: si parla quindi di una struttura primaria, risultante dall'ordine con cui sono allineati i vari amminoacidi; di una struttura secondaria, data dalla presenza di organizzazioni elicoidali (eliche alfa oppure tipo collagene) o laminari (fogli beta); di una struttura terziaria, causata dalla successione di tratti elicoidali, laminari e disordinati; di una struttura quaternaria, quando più catene polipeptidiche, uguali o diverse, concorrono a formare un'unità funzionale, come nel caso dell'emoglobina e della RNA-polimerasi.
Le proteine esplicano attività catalitica, e sono allora dette enzimi, oppure svolgono una funzione strutturale, come gli istoni; talvolta possiedono tutte e due le proprietà (come nel caso di proteine del fago T4). Esse vengono studiate nei loro vari livelli organizzativi con diverse tecniche: la struttura primaria può essere analizzata in modo automatico attraverso un procedimento di degradazione proteolitica detto ‛di Edman' (v. Stryer, 19812), mentre per le strutture superiori i metodi più efficaci si basano sugli spettri di diffrazione di raggi X su cristalli e sull'analisi al microscopio elettronico. Un'utile caratterizzazione della struttura di una proteina è l'individuazione dei ‛domini', zone globulari e compatte unite fra loro da regioni più flessibili. Spesso i domini sono codificati da ‛esoni' (v. cap. 5, § c).
3. Struttura dei complessi sopramolecolari
Le macromolecole che abbiamo descritto (acidi nucleici e proteine), e altre ancora di natura glicidica o lipidica o mista, sono per lo più organizzate in complessi sopramolecolari, dei quali i più importanti sono i cromosomi, i ribosomi, i replisomi e le membrane.
a) I cromosomi
I cromosomi sono complessi nucleoproteici presenti nei nuclei delle cellule eucariotiche, costituiti da DNA associato a una serie di proteine che ne permettono l'impaccamento, la duplicazione, l'espressione selettiva e la segregazione nelle cellule figlie. I cromosomi eucariotici sono composti da DNA e da proteine in rapporto ponderale all'incirca di 1 a 2. Le proteine dei cromosomi possono essere di tipo istonico e non istonico: tra le prime vanno ricordati i quattro tipi di istoni - 2A, 2B, 3 e 4 - che formano un agglomerato ottamerico, attorno al quale la doppia elica di DNA si avvolge con andamento sinistrorso per circa due volte originando così i nucleosomi. Dalla loro successione risulta un'organizzazione detta ‛a filo di perle', che viene poi condensata per l'aggiunta di una molecola del quinto tipo di istone, 1: si forma così una fibra più compatta rispetto alla doppia elica di DNA (che ha un diametro di 2 nm), detta ‛fibra a 10 nanometri'. Questa si avvolge poi su se stessa, forse a solenoide, originando la fibra a 30 nanometri. Lunghezze variabili della fibra a 30 nanometri vengono poi pinzate (grazie a sequenze ‛piegate' staticamente?) su un'impalcatura di proteine non istoniche: le anse che ne risultano sono molto probabilmente regioni o domini funzionali corrispondenti a geni o a famiglie di geni. Si ritiene che contengano dalle 50 alle 300 migliaia di coppie di basi. Ulteriori condensazioni portano alla comparsa di strutture via via più compatte, sino ad arrivare all'intricata e largamente sconosciuta organizzazione dei cromosomi in metafase, quando questi assumono la struttura che permetterà poi la segregazione dei singoli cromatidi nelle cellule figlie. In questa fase i cromosomi presentano la massima condensazione e il rapporto tra lunghezza totale del DNA e lunghezza totale della struttura cromosomica che lo contiene è di circa 10.000. Come è facilmente intuibile, a questo stato di compattezza, che lascia tra segmenti adiacenti di DNA una distanza di circa due volte il diametro della doppia elica (2 nm), corrisponde un minimo di attività replicativa e trascrizionale, che richiede invece una decondensazione della cromatina. Poco si sa circa la corrispondenza fra sequenze di DNA e organizzazione cromosomica; gli scarsi dati disponibili si riferiscono soprattutto al lievito, di cui, per esempio, sono state caratterizzate le sequenze poste ai terminali dei cromosomi, o telomeri, e sono state isolate diverse sequenze capaci di replicazione autonoma (v. cap. 4). Di particolare interesse strutturale sono le sequenze di DNA trovate nei centromeri, regioni cromosomiche ove si attaccano le strutture proteiche (microtubuli del cinetocoro) che permettono l'avvio della segregazione dei cromosomi nelle cellule figlie. Sui cromosomi numero 3 e 11 del lievito sono state individuate brevi sequenze (dette CEN) caratterizzate da 3 diverse regioni, indicate come I, II, III: le I e le III, lunghe rispettivamente 14 e 11 basi, sono identiche nei due cromosomi, mentre le II, lunghe poco meno di 90 basi, sono ricchissime di A-T (oltre il 93%) e presentano una minore analogia.
b) I ribosomi
Una struttura ribonucleoproteica di rilevante importanza biosintetica nella cellula è il ribosoma (v. cap. 6). All'interno di una cellula batterica in crescita esistono circa 30.000 ribosomi; costituiti da proteine e RNA in rapporto 1:2, i ribosomi sono il sito di assemblaggio delle proteine. Essi sono stati studiati soprattutto con la microscopia elettronica e con la tecnica della dissociazione e della riassociazione in vitro dei singoli componenti, oltre che con procedure enzimatiche e chimiche che forniscono indicazioni sull'esposizione di particolari subunità proteiche e di specifici tratti di RNA. I ribosomi del batterio E. coli sono i più conosciuti: caratterizzati da una velocità di sedimentazione di 70S, risultano dall'interazione di due particelle chiamate 30S e 50S. La particella 30S è composta da una molecola di RNA lunga 1.542 basi (RNA 16S) e da 21 molecole di proteme; la 50S da una molecola di RNA lunga 2.904 basi (RNA 23S), da una molecola di RNA lunga 120 basi (RNA 5S) e da 35 molecole di proteine. L'interazione fra RNA 16S e mRNA è essenziale per un efficiente riconoscimento tra ribosoma ed mRNA e per la successiva traduzione di questo in proteine. Le cellule eucariotiche contengono ribosomi di dimensioni un po' più grosse di quelli batterici, ma con caratteristiche sostanzialmente simili.
Dei replisomi e dei primosomi, strutture sopramolecolari coinvolte nella replicazione, si parlerà più avanti (v. cap. 4).
c) Le membrane
Le strutture macromolecolari più grandi presenti nelle cellule sono forse quelle che ne costituiscono l'involucro. In alcune cellule procariotiche (dette gram-negative) l'involucro è formato da tre strati: la membrana esterna, costituita da lipopolisaccaridi e lipidi; la parete intermedia, che delimita verso l'esterno il cosiddetto spazio periplasmico, formata da peptidoglicani; la membrana interna, composta da fosfolipidi. Solo queste due sono presenti nei batteri detti grampositivi. Circa un quinto delle proteine cellulari sono contenute nell'involucro. Tutti questi strati contengono polimeri strettamente interconnessi fra loro da legami crociati di natura varia e possono quindi legittimamente essere considerati strutture macromolecolari ad altissimo peso molecolare.
Anche le cellule eucariotiche sono racchiuse da un involucro, detto ‛membrana plasmatica', essenzialmente costituito da due strati lipidici ricoperti dalla cosiddetta ‛matrice cellulare'. In questo involucro sono immerse numerose proteine e strutture complesse responsabili delle interazioni della cellula con le altre cellule e con l'ambiente: pompe, canali, vescicole, sistemi di trasduzione molecolare ed energetica fanno dell'involucro cellulare uno strumento di attivo scambio con l'esterno più che una barriera tra il mezzo e la cellula. Nei vegetali le cellule sono circondate da una rigida parete composta da fibre di cellulosa immerse in una matrice di zuccheri.
4. La replicazione del DNA
La struttura del DNA suggerisce immediatamente il probabile meccanismo attraverso cui questa molecola esplica la sua proprietà fondamentale, quella di trasmettere verticalmente in modo fedele l'informazione genetica alle cellule figlie. Tale meccanismo è stato infatti proposto da Watson e Crick stessi, nell'articolo originale del 1953 in cui descrissero la struttura del DNA, composta da due filamenti avvolti in una doppia elica: man mano che si rompono i legami deboli che li tengono insieme, i precursori del DNA (i nucleotidi attivati sotto forma di trifosfati) si appaiano con le basi così rese accessibili nei due filamenti parentali; seguendo le regole di appaiamento di Chargaff, man mano che i precursori si appaiano con i nucleotidi complementari sull'elica che funge da stampo, un sistema polimerizzante che li lega alle catene figlie nascenti può ricostituire due doppie eliche identiche a quella di partenza.
Nelle sue linee fondamentali questo modello è stato confermato da tutta la ricerca successiva; i dettagli molecolari si sono rivelati assai complessi e, limitatamente a certi aspetti del processo, sono stati descritti in modo soddisfacente solo nei microrganismi procariotici. In questo capitolo descriveremo soprattutto le linee fondamentali della replicazione del DNA nei procarioti, e particolarmente in Escherichia coli, sottolineando gli aspetti ancora oscuri del processo sia nel caso dei procarioti sia in quello degli eucarioti.
In linea generale si possono distinguere due aspetti fondamentali della replicazione di un cromosoma: l'inizio della replicazione stessa e l'avanzamento della forca replicativa. Lo schema fondamentale della replicazione è lo stesso nei procarioti e negli eucarioti: nei Batteri, per esempio, esiste una sequenza di DNA specifica per l'inizio del processo di sintesi; da questa specifica sequenza di origine, che è pure la sede della regolazione del processo nel suo insieme, partono, dopo apposito segnale, la cui natura molecolare è ancora ignota, due forche replicative in direzioni opposte. L'avanzamento delle due forche assicura che il processo di sintesi avvenga secondo un modello detto ‛semiconservativo' in quanto in ciascuna delle doppie eliche figlie è conservata una delle due singole eliche parentali. Nel caso dei microrganismi procariotici, come Escherichia coli, si ha una sola sequenza di origine nel cromosoma a struttura circolare; quindi, una volta che le due forche replicative si siano organizzate a partire dall'origine, esse continuano il percorso ciascuna in direzione opposta rispetto all'altra, fino a incontrarsi in una posizione del cromosoma grosso modo diametralmente opposta a quella dell'origine. A questo punto le due forche si fondono e le due nuove molecole si separano nelle cellule figlie. Il cromosoma circolare del batterio, con la sua origine unica e specifica, è definito ‛replicone', termine introdotto da F. Jacob per indicare una molecola di DNA capace di replicazione autonoma in seguito ad attivazione della sua origine.
Nel caso degli organismi eucariotici, che posseggono più di un cromosoma, la situazione presenta molte somiglianze e qualche differenza. Vi sono numerose unità replicative (anch'esse definite, seppure con minor rigore, repliconi) disposte a tandem (cioè in successione testa-coda) all'interno dello stesso cromosoma; ogni replicone è identificato da un'origine, da cui, in modo probabilmente analogo a quello dei Batteri, partono due forche replicative opposte, che si andranno a fondere con le analoghe forche replicative partite dai repliconi adiacenti. I tempi di attivazione delle origini dei vari repliconi sono diversi nell'ambito del periodo in cui avviene la sintesi del DNA, e sono probabilmente programmati geneticamente. Nel caso dei cromosomi eucariotici, che anziché circolari sono lineari, resta poi il problema (v. sotto) della sintesi totale delle loro estremità o telomeri.
Dei due aspetti generali del processo di replicazione, l'attivazione dell'origine e l'avanzamento della forca replicativa, descriveremo prima il secondo, che è quello compreso con maggior dettaglio soprattutto nei procarioti, e accenneremo poi al primo, precisando quanto già si sa e quanto ancora si ignora al riguardo.
Il meccanismo di avanzamento della forca replicativa in Escherichia coli è stato descritto, al termine di oltre due decenni di lavoro, dal gruppo diretto da A. Kornberg -che venne insignito del Nobel nel 1959-, dell'Università di Stanford in California. Dalla combinazione di dati biochimici e genetici si deduce che tale processo avviene grazie all'interazione di una ventina di proteine col DNA. Il processo di avanzamento della forca può essere a sua volta distinto in due aspetti fondamentali: l'apertura della doppia elica vecchia e la sintesi delle eliche nuove. In realtà questi due aspetti, scindibili a scopo descrittivo, sono strettamente correlati dal punto di vista funzionale e tutte le proteine che servono all'avanzamento della forca replicativa possono essere considerate elementi di una superstruttura proteica, definita da Kornberg ‛replisoma'; anche se questa struttura non ha una individualità precisa come il ribosoma, in quanto, probabilmente, le interazioni fra le proteine della replicazione sono più deboli di quelle che tengono insieme le molecole che costituiscono i ribosomi, tuttavia le interazioni fra tali proteine sono così specifiche da giustificare il concetto di replisoma, inteso come entità funzionale sopramolecolare.
Nel caso di Escherichia coli la funzione principale di svolgimento dell'elica è espletata soprattutto da una proteina detta ‛elicasi', prodotta dal gene 'dnaB'. Questa proteina scorre su uno dei filamenti in direzione 5′ → 3′ e quindi svolge il filamento complementare in direzione 3′ → 5′.
L'attività di polimerizzazione avviene essenzialmente per opera di enzimi chiamati DNA-polimerasi, i primi enzimi coinvolti nella sintesi del DNA che sono stati descritti. Esistono diversi tipi di DNA-polimerasi in ogni organismo (3 in Escherichia coli); la DNA-polimerasi principalmente coinvolta nella sintesi replicativa del DNA di Escherichia coli è la DNA-polimerasi III. Come tutte le DNA-polimerasi conosciute, essa polimerizza il DNA usando come precursori i desossiribonucleotidi 5′-trifosfati e sintetizzando la catena unicamente nella direzione 5′ → 3′. Per questa ragione, affinché la sintesi avvenga contemporaneamente, almeno in prima approssimazione, sulle due eliche nella stessa direzione in cui avanza la forca replicativa, l'attività della DNA-polimerasi si svolge in maniera diversa sui due filamenti parentali. Sul filamento chiamato ‛progressivo' (leading strand) la DNA-polimerasi agisce in modo continuo sintetizzando appunto la catena complementare secondo le regole di Chargaff in direzione 5' 3'. Sul filamento opposto, che viene chiamato ‛regressivo' (lagging strand), la sintesi avviene pure in direzione 5' 3' (per le limitazioni intrinseche delle DNA-polimerasi) e quindi deve procedere per brevi tratti successivi in direzione opposta rispetto all'avanzamento della forca. Ora, le DNA-polimerasi di qualunque organismo non sono in grado di iniziare catene di DNA ex novo: esse hanno bisogno sempre di un innesco (o primer) cui attaccare il primo desossiribonucleotide, oltre che di un filamento stampo che determini l'ordine in cui vengono incorporati i vari nucleotidi. La sintesi degli inneschi, catalizzata da enzimi specifici (le ‛primasi'), avviene anch'essa in direzione 5′ → 3′ e a partire dagli stessi tipi di precursori su cui agiscono le DNA-polimerasi; senonché le primasi non distinguono tra desossiribonucleotidi trifosfati e i corrispondenti ribonucleotidi trifosfati; per tale ragione, data la molto maggiore concentrazione intracellulare dei trifosfati della serie ‛ribo' rispetto ai ‛desossiribo', tali inneschi sono formati regolarmente da un breve tratto di RNA.
La DNA-primasi di Escherichia coli, prodotta dal gene dnaG, sintetizza a intervalli regolari sul filamento regressivo, dove la sintesi di DNA avviene in modo discontinuo, brevi inneschi di circa 10 ÷ 12 nucleotidi in direzione 5′ → 3′. A ciascuno di questi inneschi si può attaccare la DNA-polimerasi III, che sintetizza un frammento di DNA (detto di Okazaki dal nome del suo scopritore) della lunghezza di circa 1.000 nucleotidi. La sintesi di DNA da parte della DNA-polimerasi III si arresta all'altezza del primo nucleotide dell'innesco sintetizzato precedentemente. A questo punto è necessario eliminare l'innesco di RNA. Ciò avviene per azione di un'altra DNA-polimerasi, distinta dalla polimerasi III e chiamata DNA-polimerasi I (in quanto è stata la prima descritta). Tale enzima esplica, oltre all'attività polimerizzante, un'attività esonucleolitica che può degradare l'RNA appaiato al DNA. Grazie all'associazione dell'attività esonucleolitica e dell'attività polimerizzante, la DNA-polimerasi I può contemporaneamente degradare l'innesco di RNA e sintetizzare il DNA corrispondente. La DNA-polimerasi I si arresta in corrispondenza del desossiribonucleotide attaccato dalla DNA-polimerasi III all'estremità distale dell'innesco. A questo punto interviene un altro enzima, la DNA-ligasi, che realizza il legame fosfodiesterico tra il 3′-OH dell'ultimo nucleotide introdotto dalla DNA-polimerasi I e il 5′-fosfato del nucleotide attaccato all'estremità distale dell'innesco dalla polimerasi III. In tal modo la continuità della doppia elica è assicurata anche sul filamento regressivo.
L'avanzamento grossolanamente simmetrico (a maggior risoluzione, come si è visto, asimmetrico) della forca replicativa avviene quindi grazie alla combinazione di due movimenti: da una parte, la DNA-polimerasi III avanza sul filamento progressivo in modo continuo e in direzione 5′ → 3′; dall'altra, la elicasi dnaB, assieme a diverse proteine accessorie e alla primasi, con cui forma il complesso detto ‛primosoma' (o ‛complesso di inizio', o priming), scorre in direzione 5′ → 3′ sullo stampo, spelandolo, per così dire, davanti alla polimerasi III che avanza sull'elica progressiva. A intervalli regolari il primosoma indugia brevemente per permettere alla primasi di produrre un breve innesco di RNA in senso retrogrado: quindi il primosoma riprende il suo cammino, producendo l'avanzamento della forca replicativa.
Oltre alle proteine che svolgono le reazioni fondamentali appena descritte (elicasi, DNA-polimerasi III, primasi, DNA-polimerasi I, ligasi), vi sono diverse proteine accessorie. Tra queste, per le loro proprietà, fondamentali nell'assicurare la struttura complessiva dei cromosomi, ne ricordiamo soprattutto due: la girasi e la proteina SSB.
La girasi è una topoisomerasi (v. cap. 2, § c) che utilizza energia prodotta dall'idrolisi dell'ATP. L'introduzione di superavvolgimenti, che avviene con la girasi disposta a valle rispetto alla forca replicativa, produce una tensione a livello della forca stessa che facilita lo svolgimento delle eliche e l'azione elicasica. Nei cromosomi circolari, come quello di Escherichia coli, si può anche ritenere che la girasi faciliti il districarsi delle due molecole circolari alla fine del processo di replicazione.
Un'altra proteina accessoria che merita menzione è la proteina che si lega al DNA a singolo filamento (singlestranded DNA binding, SSB). Questa proteina ha la proprietà di legarsi in modo cooperativo (ossia facilitando il legame adiacente di altre molecole dello stesso tipo) al DNA a singolo filamento mantenendolo disteso e quindi più adatto a essere copiato in modo complementare dalle DNA-polimerasi.
La DNA-polimerasi III consiste in un grosso complesso multimolecolare, formato da almeno 7 proteine diverse. Tale complesso viene chiamato oloenzima e, mentre la semplice attività polimerizzante può essere misurata in vitro anche su un'unica frazione polipeptidica (la subunità α), soltanto se il complesso oloenzima è legato al DNA per intero si può avere la sintesi al tasso fisiologico (750 nucleotidi polimerizzati al secondo) di tratti prolungati di DNA (praticamente la sintesi ininterrotta sul filamento progressivo).
Per quanto riguarda gli organismi eucariotici, e particolarmente le cellule animali, comprese quelle umane, si sono purificate e caratterizzate alcune proteine con proprietà analoghe a quelle principali descritte per Escherichia coli. A tutt'oggi, però, nel caso degli eucarioti, manca una descrizione dettagliata, analoga a quella ottenuta per E. coli, delle proprietà e delle funzioni delle singole proteine coinvolte nella replicazione del DNA e del loro ruolo nel processo di avanzamento della forca. L'enzima più importante è una DNA-polimerasi a funzione replicativa, detta DNA-polimerasi α: anch'essa risulta organizzata in una struttura sopramolecolare, come l'oloenzima batterico; sono inoltre state individuate una primasi, un'elicasi e delle proteine SSH. Gli inneschi di RNA sono probabilmente rimossi da una particolare ribonucleasi chiamata ribonucleasi H (da hybrid), che elimina l'RNA in una doppia elica ibrida RNA-DNA, e sono poi sostituiti grazie all'azione di una DNA-polimerasi, che potrebbe essere sia l'α che la β, meno abbondante nella cellula rispetto all'α e più piccola. È stata descritta anche una ligasi con proprietà analoghe a quella batterica (con l'unica differenza che utilizza ATP invece che NAD come donatore di energia).
Una peculiarità delle cellule eucariotiche, e particolarmente di quelle animali, è il fatto che il DNA è organizzato in strutture complesse (nucleosomi) insieme a particolari proteine, in prevalenza istoni. La forca replicativa quindi deve risolvere nel suo avanzamento anche il problema di come attraversare i nucleosomi. Pare che al passaggio della forca replicativa le 8 proteine che formano i singoli nucleosomi non vengano disperse ma restino legate tra loro. I nucleosomi vecchi (parentali), dopo il passaggio della forca replicativa, si trovano associati indifferentemente e casualmente all'una o all'altra delle due doppie eliche figlie.
Una peculiarità che distingue l'avanzamento della forca nelle cellule animali da quello nelle cellule batteriche (e che è probabilmente correlata alla presenza di nucleosomi nelle prime) consiste nel fatto che i frammenti di Okazaki, presenti sul filamento regressivo, sono nettamente più brevi nelle cellule animali (in media 200 nucleotidi) che in quelle batteriche (1.000 nucleotidi). È molto probabile che questa lunghezza sia correlata con la lunghezza del tratto di DNA organizzato nel nucleosoma: probabilmente il segnale per la partenza dell'innesco è localizzato in un punto del tratto di DNA di ogni nucleosoma, forse nel tratto internucleosomico, che è lungo in media 60 basi. In ogni modo la forca replicativa avanza nelle cellule animali a velocità molto inferiore che nei Batteri: 50 basi al secondo invece di 750.
Veniamo ora alla prima parte del processo di replicazione del DNA: l'attivazione delle origini della replicazione. Questa fase, che anche nei procarioti resta tuttora la meno conosciuta dell'intero processo, è di grande importanza, in quanto regola la velocità della replicazione, la quale non dipende dalla velocità di avanzamento delle forche replicative, che resta costante, bensì dal numero delle origini. In linea generale vale la regola per cui, quando un'origine di replicazione è stata attivata, e quindi da essa si distaccano le due forche replicative in direzione opposta, le due sequenze di origine nelle molecole figlie non vengono riattivate fino a che non sia passata una generazione cellulare con relativa segregazione dei nuovi cromosomi nelle cellule figlie (esistono eccezioni a questa regola: più di due forche replicative sono state identificate nei cromosomi di batteri che si stanno replicando in terreno ricco; l'attivazione diffusa della replicazione del DNA, inoltre, interessa un numero probabilmente elevato ma indeterminato di origini aspecifiche durante le primissime fasi della segmentazione degli embrioni).
Come abbiamo già visto, un replicone è una molecola di DNA capace di replicazione autonoma; pertanto esso è caratterizzato da una sequenza di DNA, che serve da origine, e da una o più proteine in grado di riconoscere in modo specifico tale origine e di attivarla. Dati genetici nei Batteri hanno permesso di definire l'esistenza di proteine che agiscono soltanto al momento dell'attivazione dell'origine della replicazione; ne è un esempio il prodotto del gene dnaA, l'unica proteina di questo genere che sia stata purificata e la cui azione sia stata riprodotta in vitro (dal gruppo di Kornberg).
Elemento essenziale nel processo di attivazione dell'origine, soprattutto nel caso dei Batteri, è la specificità di interazione tra proteine attivanti e sequenze di origine: repliconi diversi (quali, per es., all'interno di uno stesso batterio, il cromosoma batterico e un plasmide) hanno sequenze di origine diverse e quindi proteine attivanti diverse.
Il processo di attivazione dell'origine è stato parzialmente riprodotto in vitro in plasmidi che contengono l'origine di replicazione di Escherichia coli; sulla base di questo esperimento e di osservazioni compiute su batteriofagi come il lambda, che presentano un processo di attivazione dell'origine simile a quello dei Batteri, si è costruito un modello della fase iniziale della replicazione.
Il modello generale è ancora solo parzialmente descritto ed è il seguente: alla sequenza di origine, che contiene tratti ripetuti a tandem, si legano diverse subunità, probabilmente 4, di una proteina altamente specifica per la sequenza ripetuta. Una volta che si sia formato questo complesso, la sua interazione con altre proteine non specifiche per quella sequenza, quali la girasi e una proteina analoga agli istoni, sottopone la zona dell'origine a un forte stress torsionale. Con la mediazione di una proteina, che in Escherichia coli corrisponde probabilmente alla proteina codificata dal gene dnaC, oltre che delle proteine SSB, si ha a questo punto l'attacco, sui due filamenti parzialmente denaturati in modo simmetrico, di due molecole di elicasi, ciascuna associata alla primasi, e di altre proteine. Questo complesso, attaccato saldamente al singolo filamento tramite le proteine che lo compongono e associato a proteine accessorie, costituisce il ‛primosoma' già descritto.
Si formano in tal modo due primosomi con orientamenti opposti sulle due eliche complementari. La sintesi da parte della primasi di due brevi inneschi di RNA sulle due eliche complementari permette l'attacco agli inneschi della DNA-polimerasi III oloenzima: una molecola per innesco, quindi due molecole per zona di origine. A questo punto, in corrispondenza di ciascuna forca, inizia la sintesi del filamento progressivo da parte della DNA-polimerasi III oloenzima, mentre il primosoma (essenzialmente complesso elicasi/primasi) si sposta sull'elica stampo. A intervalli regolari il primosoma può innescare la primasi permettendo quindi la sintesi discontinua in senso retrogrado dell'elica regressiva.
Questo modello, nelle sue linee generali e almeno nel caso di E. coli, spiega abbastanza bene l'organizzazione iniziale delle due forche replicative opposte, che poi possono viaggiare in modo indipendente. Esso peraltro lascia senza risposta alcuni quesiti non secondari: innanzitutto non è chiaro perché il legame delle proteine attivatrici specifiche si abbia soltanto al momento dell'attivazione delle origini e non prima. In secondo luogo non si spiega perché le due sequenze di origine neosintetizzate a partire dalla sequenza parentale dopo l'allontanamento delle due forche replicative non vengano riattivate fino a che non sia avvenuto il completamento del cromosoma e si sia entrati in un nuovo ciclo di replicazione. Per quanto riguarda gli organismi eucariotici il problema è ancora meno chiaro ed è oggetto di intensa ricerca.
A proposito dei cromosomi eucariotici è infine da menzionare il problema della replicazione alle terminazioni: infatti, data l'impossibilità, da parte delle DNA-polimerasi, di iniziare la sintesi senza un innesco fornito da un'altra molecola, a ogni replicazione, quando la forca replicativa giunge a un'estremità, si avrebbe la mancata duplicazione totale di un'estremità del cromosoma, quella corrispondente all'ultima porzione dell'elica regressiva. È questa, probabilmente, la ragione per cui le terminazioni dei cromosomi eucariotici (telomeri) hanno particolari strutture e non possono essere perdute dal cromosoma, pena notevoli anomalie nella mitosi. Le strutture dei telomeri di alcuni eucarioti più semplici sono state identificate: si tratta di sequenze ripetitive con molte rotture a singolo filamento. Tali strutture garantiscono la replicazione della terminazione senza perdite progressive delle estremità. In ogni caso, organismi eucariotici diversi, anche se abbastanza simili, hanno telomeri diversi (anche se funzionalmente interscambiabili, come nel caso di protozoi ciliati e funghi). È quindi pensabile che le diverse cellule animali, comprese quelle umane, abbiano pure strutture telomeriche diverse; resta comunque il fatto che il meccanismo fine con cui i telomeri vengono replicati non è stato ancora definito.
5. Espressione dei geni
Secondo lo schema presentato all'inizio, i geni ‛esprimono' il loro contenuto informazionale mediante la trascrizione, cioè la copiatura, di uno o, raramente, di entrambi i filamenti della doppia elica del DNA, in sequenze di RNA, quindi mediante la traduzione di queste in proteine.
Esistono anche altri modi d'espressione genica, che si realizzano attraverso il riconoscimento di specifiche sequenze del DNA da parte di altre macromolecole. In generale, però, le funzioni di ogni cellula e la loro regolazione si attuano primariamente attraverso la sintesi di una serie di RNA: di questi, alcuni vengono poi ‛tradotti' in proteine, alcuni funzionano come tali, per esempio come adattatori tra sequenze di ‛codoni' (v. cap. 6) e amminoacidi nella sintesi proteica (i tRNA), altri infine concorrono a formare ribonucleoproteine, in cui RNA e proteine interagiscono a formare strutture complesse quali i ribosomi o le particelle ribonucleoproteiche citoplasmatiche e nucleari coinvolte nella maturazione degli RNA (v. sotto).
Nelle cellule procariotiche quasi tutte le sequenze del DNA vengono trascritte in RNA: alcune vengono trascritte più e più volte in prodotti stabili, che si accumulano sino a raggiungere decine (gli rRNA) o centinaia (i tRNA) di migliaia di copie. Altre sequenze vengono trascritte in RNA che di norma sono rappresentati nelle cellule da un numero relativamente basso di copie. È il caso degli mRNA, che, oltre a essere spesso sintetizzati solo quando la cellula li richiede (sistemi inducibili), sono sottoposti a un regime di più o meno rapida degradazione, che richiede minuti nei procarioti e ore negli eucarioti. Nella cellula eucariotica media la situazione è sostanzialmente simile, con l'importante differenza che una grossa frazione del DNA non è trascritta in RNA.
La distinzione tra DNA ‛funzionale' e DNA ‛a funzione sconosciuta' diventa quasi paradossale in alcuni eucarioti inferiori, quali i protozoi ciliati Tetrahymena e Oxytricha, nei quali si ha addirittura una separazione fisica tra DNA totale, che viene trasmesso alla progenie, e DNA ‛funzionale' o ‛informativo', pari a circa il 10% del totale, che viene amplificato ed espresso in prodotti genici. Il primo è contenuto in micronuclei, il secondo in macronuclei poliploidi. Perché la totalità delle sequenze del DNA di questi protozoi debba passare di generazione in generazione, visto che solo una frazione viene espressa, resta un interessante problema evolutivo. Sono casi di questo genere che hanno indotto alcuni autori a coniare il termine ‛DNA egoista' per indicare quel DNA che si replica ma non pare avere altre funzioni (v. Doolittle e Sapienza, 1980; v. Crick e Orgel, 1980).
Le molecole di mRNA sono in generale lunghe tra mille e diecimila basi e ammontano complessivamente a circa 5 × 105 ÷ 106 per cellula; il numero totale di proteine che ne deriva è circa 1.000 ÷ 5.000 volte maggiore. Il numero medio di specie diverse di mRNA per cellula è grosso modo diecimila, pari a un quinto ÷ un decimo di tutte le possibili specie di trascritti: si calcola infatti che i geni contenuti nel genoma di un animale superiore siano circa 5 × 104 ÷ 105.
La complessità di una popolazione di RNA è il numero di sequenze diverse che contiene, l'abbondanza è il numero di copie della stessa molecola. È possibile affermare che la regolazione dell'attività genica è soprattutto quell'insieme di fenomeni che controlla complessità e abbondanza degli RNA presenti in una cellula.
Con un certo grado di arbitrarietà si usa suddividere gli mRNA di ogni cellula eucariotica in tre classi: a) abbondanti; b) mediamente rappresentati; c) scarsi. Ciascuna delle 5 ÷ 10 specie molecolari degli RNA della prima classe è presente in 10.000 ÷ 15.000 copie. Nella classe mediamente rappresentata ciascuna delle 500 specie è rappresentata circa 300 volte. Gli RNA scarsi sono quelli che contano 10 ÷ 20 copie di ciascuna delle 10.000 ÷ 12.000 diverse specie. Paradossalmente, quindi, gli mRNA ‛abbondanti' ammontano solo a un 20% circa del numero totale delle molecole di mRNA presenti in una cellula eucariotica media.
Va infine ricordato che alcuni mRNA sono presenti in tutte le cellule, mentre altri concorrono a prestazioni specializzate. Fra i primi compaiono gli mRNA delle proteine ribosomiche e degli enzimi responsabili della replicazione del DNA: questi mRNA sono detti di house,keeping (‛di manutenzione ordinaria'). Fra i secondi ricordiamo gli mRNA responsabili della sintesi di prodotti specializzati, come le globine delle cellule del sangue.
a) Trascrizione
La trascrizione è la sintesi enzimatica di RNA a partire da sequenze di DNA. Le analogie con la replicazione del DNA sono molteplici: i precursori sono ancora nucleotidi 5′-trifosfati, ma della serie ribo.
La reazione di polimerizzazione presenta lo stesso meccanismo di crescita in direzione 5′ → 3′, per attacco nucleofilico del fosfato α, il primo in 5′, sull'OH in 3′ del ribosio. Il catalizzatore è un enzima a struttura quaternaria composto da diverse subunità (α, β, β′, σ), detto RNA-polimerasi. A differenza delle DNA-polimerasi, le RNA-polimerasi possono iniziare e terminare i loro prodotti grazie alla capacità (che le DNA-polimerasi non hanno) di riconoscere specifiche sequenze di DNA.
Nelle cellule procariotiche esiste di norma una sola RNA-polimerasi in grado di produrre tutti e tre i principali tipi di RNA (tRNA, rRNA, mRNA); in quelle eucariotiche ne sono state individuate almeno 3: la RNA-polimerasi I è responsabile della sintesi degli rRNA, la II produce i precursori degli mRNA, la III trascrive i geni degli RNA piccoli (il 5S, i tRNA e i piccoli RNA citoplasmatici e nucleari).
La trascrizione di un gene da parte delle RNA-polimerasi avviene attraverso una serie di eventi che vanno dal riconoscimento di speciali sequenze nello stampo di DNA all'inizio della polimerizzazione dei precursori, all'allungamento della catena di RNA, alla sua terminazione, al distacco dell'RNA e dell'enzima dallo stampo. Il prodotto primario di trascrizione di solito matura in un prodotto finale attraverso modificazioni che possono interessare sia le dimensioni del trascritto primario sia i singoli nucleotidi che lo compongono.
Il riconoscimento della sequenza da trascrivere da parte dell'enzima avviene in corrispondenza di una sequenza detta ‛promotore'. Essa si trova a monte del gene da trascrivere ed è caratterizzata da due elementi o ‛scatole': nei procarioti una è situata circa 10 basi a monte della prima base trascritta (in genere purinica) ed è chiamata ‛scatola di Pribnow', o ‛sequenza a −10'. La sua sequenza è del tipo 5′-TATAAT-3′ (sul filamento di DNA complementare allo stampo). L'altra è chiamata ‛scatola a −35' ed è del tipo TTGACA. La sequenza tra le due scatole è lunga tra 15 e 18 basi, 17 essendo il numero ottimale per il funzionamento del promotore (la sua forza). Sempre a monte del gene esistono altre sequenze che costituiscono elementi di controllo supplementari: tra questi ricordiamo i cosiddetti geni ‛operatori' (contigui o parzialmente sovrapposti ai promotori) ai quali si possono legare proteine regolatrici (tra le quali i repressori) che attivano o disattivano il gene interferendo con il legame tra RNA-polimerasi e promotore.
Alla corretta discriminazione del promotore tra tutte le altre sequenze di DNA da parte della RNA-polimerasi concorre una subunità accessoria legata al ‛cuore' della RNA-polimerasi, detta σ. Una volta avvenuto il riconoscimento del promotore, e verificata l'accuratezza della scelta mediante la trascrizione di circa 2 ÷ 10 nucleotidi all'inizio del gene, la subunità σ si stacca e viene riciclata. L'impiego di diverse subunità σ varia a seconda dei geni da attivare e quindi in risposta alle condizioni di crescita: il fenomeno è stato studiato soprattutto durante la crescita delle spore in B. subtilis.
Il ‛cuore' dell'enzima continua poi la trascrizione, sino a quando particolari sequenze dello stampo segnalano all'enzima (talvolta con l'intervento di fattori specifici di rilascio, tipo il fattore ρ) che è tempo di staccarsi e liberare il prodotto; il distacco dell'enzima e la concomitante liberazione dell'RNA prodotto avvengono di solito in corrispondenza di strutture terziarie a forcina, di fronte alle quali l'avanzamento delle RNA-polimerasi è rallentato.
Sostanzialmente identico è il meccanismo di trascrizione negli eucarioti, con la differenza che questi ultimi presentano siti di attivazione della trascrizione, detti ‛potenziatori' (enhancers), a sequenza spesso ripetuta, situati anche a diverse centinaia di basi a monte o a valle del gene da trascrivere. Particolarmente importanti per l'attività delle RNA-polimerasi II sono tre sequenze poste a 200 ÷ 100, a circa 70 e a 25 basi a monte dell'inizio della trascrizione; le prime sono chiamate ‛modulatori', le seconde ‛scatole CAAT' e le terze ‛scatole TATA' (dalle sequenze che spesso vi compaiono). Insieme regolano sia la forza del legame delle RNA-polimerasi, sia la selezione dell'inizio della trascrizione. Pure peculiare è la posizione dei promotori per le RNA-polimerasi III eucariotiche, i quali spesso si trovano all'interno della sequenza trascritta, come nel caso dei geni di alcuni piccoli RNA di adenovirus, di RNA 5S e di tRNA. Interessante il fatto che nei geni dei tRNA il promotore bipartito corrisponda a due zone di DNA altamente conservate, che vengono trascritte nelle anse 1 e 3, dette anche anse D e TΨC.
Oltre che specifiche sequenze (promotori, potenziatori), è probabile che anche speciali stati del DNA e della cromatina favoriscano la trascrizione. Tra questi occorre ricordare una condizione caratterizzata da una pronunciata sensibilità a nucleasi, che starebbe a indicare una struttura cr0matinica più rilassata, ad esempio grazie all'assenza di nucleosomi, e uno stato di ipometilazione transiente di specifiche regioni, che coinciderebbe con una loro attivazione trascrizionale, o almeno con una predisposizione alla trascrizione.
b) Maturazione dei prodotti di trascrizione
Non tutti i prodotti di trascrizione sono capaci di svolgere immediatamente le loro funzioni: infatti, mentre alcuni, come gli mRNA dei procarioti, man mano che vengono sintetizzati si staccano dal complesso di trascrizione (lo stampo di DNA e RNA-polimerasi) e vengono ingaggiati immediatamente dalle strutture preposte alla sintesi delle proteine (i ribosomi), senza bisogno di modificazioni di maggior rilievo, altri, prima di poter funzionare, devono subire una complessa serie di cambiamenti: devono cioè maturare.
Tanto nei procarioti quanto negli eucarioti sono stati riscontrati processi di maturazione a carico di tutti i tipi di RNA: la sintesi di prodotti immaturi che richiedono una serie di interventi per assumere una struttura funzionale potrebbe essere stata conservata nel corso dell'evoluzione, in quanto fornisce alle cellule un sistema per assicurarsi, in caso di necessità, una pronta disponibilità di prodotti quasi maturi senza saturare il sistema con un eccesso di prodotti finiti, né doverlo sottoporre a sintesi accelerate quando la richiesta di prodotti sia impellente.
I processi maturativi possono essere diversi: rimozione di parti del prodotto primario di trascrizione, sia dalle estremità, sia da regioni interne; aggiunta di materiale nucleotidico alle estremità; modificazione di singoli nucleotidi, specialmente nei tRNA. Di particolare interesse è il processo che comporta la rimozione di sequenze nucleotidiche all'interno di singoli prodotti di trascrizione. Questo processo è indicato con il termine inglese splicing, che significa ‛riunione di estremità tagliate'. È di questo che tratteremo più estesamente.
c) Splicing
Anche se non tutti gli RNA subiscono il processo di splicing, esso è stato riscontrato in ognuno dei 3 tipi di RNA delle cellule eucariotiche. Lo splicing non può essere considerato una caratteristica esclusiva degli RNA eucariotici, in quanto riscontrato nell'mRNA di un gene (timidilatosintasi) del batteriofago di E. coli chiamato T4 e nei precursori di tRNA di archeobatteri (v. Gilbert e altri, 1986).
La scoperta dello splicing degli mRNA ha infranto uno dei dogmi della genetica molecolare: la correlazione tra distanze intrageniche e distanze tra amminoacidi nella proteina corrispondente. I geni che codificano per quegli mRNA che richiedono splicing sono infatti caratterizzati da una struttura geneticamente discontinua, anche se fisicamente continua. Tali geni risultano infatti composti da un alternarsi di elementi codificanti, detti ‛esoni' (in quanto ‛espressi' o ‛esportati') e di elementi non codificanti, detti ‛introni' (in quanto ‛intervengono' tra i primi); i primi compaiono nel prodotto di trascrizione, i secondi no.
Annunciata nel 1977 da ricercatori americani come una scoperta ‛sbalorditiva' (v. Chou e altri, 1977), l'identificazione di una struttura discontinua in una zona del genoma di adenovirus 2 ha in effetti aperto un nuovo capitolo nello studio della genetica molecolare degli eucarioti. Molti dei geni degli organismi superiori presentano una struttura a pezzi alternati di esoni e introni. Tanto il significato biologico quanto il meccanismo di rimozione degli introni rappresentano problemi di grande interesse teorico e sperimentale.
Esistono diverse tecniche che permettono di individuare la struttura discontinua di un gene costituito da esoni e introni: le più informative sono l'analisi al microscopio elettronico di ibridi DNA-RNA maturi, lo studio dei profili elettroforetici di frammenti di restrizione del gene per mezzo di sonde polinucleotidiche corrispondenti a due o più esoni (ibridazione alla Southern con cDNA: v. cap. 11) e il confronto diretto della sequenza del gene con quella dell'RNA maturo (o della sua copia in DNA) o, infine, con quella della proteina corrispondente.
L'analisi dei numerosi geni eucariotici caratterizzati sinora suggerisce l'ipotesi che gli esoni rappresentino geni ancestrali corrispondenti a piccoli peptidi modulari dalla cui apposizione deriverebbero le più grandi e complesse proteine attuali: in effetti è spesso possibile individuare nella struttura secondaria e terziaria di molte proteine la presenza di ‛domini' funzionali la cui sequenza amminoacidica è codificata da singole sequenze esoniche. Esempi di questa correlazione sono dati da molecole tipo le immunoglobuline, le globine e diverse proteasi. Un'altra caratteristica dell'organizzazione dei geni discontinui è la maggiore lunghezza degli introni rispetto agli esoni: ad esempio nel gene umano del fattore antiemofilico VIII si sono riscontrati ben 26 esoni e 25 introni (v. Gitschier e altri, 1984). La lunghezza complessiva del gene è di 186.000 coppie di basi, di cui solo circa un ventesimo codifica per la proteina: l'esone più lungo, il 14, consta di 3.100 basi.
Ancora non sappiamo molto sull'origine e sulle funzioni degli introni: in particolare ignoriamo se l'evoluzione proceda verso l'acquisizione di introni da parte dei genomi procariotici, oppure verso la loro perdita da parte dei genomi eucariotici. Pare che la seconda ipotesi sia la più probabile, visto che in diversi geni codificanti per proteine ubiquitarie (ad es. triosofosfatoisomerasi, actina e altre) alcuni introni occupano esattamente la stessa posizione in organismi evolutivamente molto diversi come uccelli, piante e funghi (v. Gilbert e altri, 1986).
Un po' di più sappiamo sui meccanismi che permettono la rimozione degli introni. Ne sono stati finora caratterizzati almeno quattro tipi fondamentali.
1. Il meccanismo più semplice è forse quello che, in lievito, rimuove il singolo introne dai precursori di circa il 10% dei tRNA e in questo processo sblocca la tripletta dell'anticodone, altrimenti appaiata. I tagli a monte e a valle dell'introne sono prodotti da un'endonucleasi aspecifica, mentre le risultanti estremità libere dei due esoni sono saldate fra loro mediante l'azione di un secondo enzima, detto RNA-ligasi. Interessante è il fatto che nei Mammiferi la reazione è simile a quella del lievito, anche se non identica: questo è lo splicing del I tipo.
2. Un secondo meccanismo (splicing del II tipo) controlla, ad es., la rimozione dell'introne dell'RNA ribosomico maggiore di ciliati tipo Tetrahymena thermophila, a partire da strutture plasmidiche lineari, probabilmente prodotte per amplificazione genica. La reazione richiede come coenzima un composto di piccole dimensioni, identificato come un derivato del nucleoside purinico guanosina; l'enzima è lo stesso RNA intronico, che in questo caso è detto ‛ribozima' (v. Zang e altri, 1986). Tramite un meccanismo in gran parte oscuro, questo ‛enzima' permette una reazione di ‛transesterificazione' che unisce i terminali dei due esoni e rimuove l'introne sotto forma di struttura circolare ‛a lazo' (il terminale 3′ si attacca 15 nucleotidi circa a valle del terminale 5′). È questo un interessante esempio di reazione enzimatica in cui l'enzima non è una proteina, ma un RNA. Sono state individuate altre reazioni del genere, in cui fungono da enzimi rRNA nucleari e di organelli e mRNA di mitocondri di funghi. Lo splicing del II tipo è caratterizzato dalla presenza nell'introne di una struttura secondaria costante, e l'‛enzima' presenta specificità di sequenza, in questo simile alle endonucleasi di restrizione (v. cap. 11, § b).
3. Un terzo meccanismo porta alla rimozione degli introni degli mRNA (splicing del III tipo). In questo caso i tagli che separano gli esoni dagli introni sono introdotti nell'RNA precursore in corrispondenza di sequenze ‛consenso' (dette cosi in quanto sinora riscontrate su oltre 130 mRNA di geni animali e oltre 160 di geni vegetali: v. Gilbert e altri, 1986). La sequenza consenso è: ...AG ↓ GU... (Py)n...AG ↓ GG... (ove Py sta per pirimidina, C o U), in cui l'introne da rimuovere è compreso entro le frecce, che indicano i tagli che staccano gli introni dagli esoni. Spesso l'esone a monte dell'introne termina con AG, quello a valle inizia con GG. Poco si sa dell'enzimologia della reazione: essa richiede la giustapposizione delle estremità degli esoni da riunire e vi intervengono particelle ribonucleoproteiche composte da una decina di proteine e da un corto RNA, di circa 90 basi, la cui sequenza è in parte complementare alle estremità esoniche da saldare. L'introne viene rimosso attraverso una reazione di circolarizzazione che comporta la formazione di un legame tra il terminale 5′ dell'introne e una zona prossima al terminale 3′, e la comparsa, anche in questo caso, di strutture ‛a lazo' o ‛a lariat': è quindi anche questa una reazione in parte sequenza-specifica.
La stessa sequenza di esoni e introni può essere maturata in mRNA diversi attraverso splicings alternativi, spesso tessuto-specifici: una successione di due introni e un esone può talvolta fungere da unico esone, come nel caso dei geni per i due antigeni T e t del virus oncogeno a DNA SV40.
4. Un quarto tipo di rimozione di un introne dal precursore di un mRNA è stato caratterizzato nel trascritto di un gene, oxi3 (che codifica per una subunità della citocromossidasi b), del DNA mitocondriale di lievito: essa è catalizzata da un ipotetico enzima (detto ‛maturasi'), codificato dall'insieme delle sequenze del primo e del secondo esone e del secondo introne. Quando la maturasi ha esaurito la sua funzione di rimozione del primo introne, la sequenza che la codifica è scomparsa dall'mRNA in via di maturazione; questo, a seguito del successivo progredire dello splicing, conterrà solo il messaggio per oxi3.
d) Maturazione alle estremità
La maturazione dei trascritti avviene anche attraverso rimozione di sequenze da una o dall'altra delle due estremità. Classico è il caso del precursore degli rRNA: prodotto nei Mammiferi come unico filamento a velocità di sedimentazione pari a 45S (14.000 basi), viene progressivamente ridotto alle dimensioni dei due rRNA maggiori, 28S e 18S (4.700 e 1.900 basi rispettivamente), oltre che di uno minore, 5,8S (120 basi), a seguito della rimozione di sequenze sia ai due terminali, sia tra i due rRNA maggiori.
Nei procarioti la rimozione di materiale extra dal precursore degli rRNA produce anche dei tRNA. Questi ultimi, quando i loro geni sono adiacenti, vengono sintetizzati come un unico trascritto multiplo, che è ridotto alle dimensioni giuste dall'azione concertata di una batteria di RNAsi: tra queste merita particolare attenzione la RNAsi P, che taglia al terminale 5′. Questa RNAsi è una struttura ribonucleoproteica, il cui componente ribonucleico, in E. coli lungo 375 basi, come i ‛ribozimi' ricordati a proposito dello splicing del II tipo, è in grado di catalizzare da solo la reazione di maturazione. Interessante è la interscambiabilità degli RNA per le RNAsi P in organismi tanto distanti quanto l'uomo e il batterio E. coli: i loro RNA hanno sequenze primarie diverse, ma secondarie simili.
Due tipi di modificazioni terminali interessano spesso la maturazione dei precursori degli mRNA eucariotici: l'aggiunta di una coda di A (poliadenilazione) al terminale 3′ (forse presente anche negli mRNA dei procarioti: v. Karnik e altri, 1986) e l'aggiunta di un residuo G modificato al 5′. La poliadenilazione comporta la rimozione dell'ultimo tratto dal trascritto, con la risultante esposizione di una sequenza del tipo AAUAA che segnala a una poliA-polimerasi la necessità di aggiungere al terminale 3′, posto qualche decina di residui più a valle, qualche centinaio di residui A, utilizzando ATP. La catena di poliA si accorcia con l'età dell'mRNA. La poliadenilazione avviene nel nucleo, così come la modificazione al terminale 5′: questa interessa il primo nucleotide (A o G nel 75% dei casi, una pirimidina nel resto) con cui la RNA-polimerasi II inizia la trascrizione, e comporta l'aggiunta di un GTP (metilato) al secondo dei tre fosfati del primo nucleotide del trascritto. Peculiare è la natura del legame tra questo e il metil-GTP: si tratta di un legame non fosfodiesterico ma pirofosforico. Entrambe queste modificazioni contribuirebbero alla stabilizzazione dei trascritti. Una modificazione che ha luogo su alcuni tRNA è l'aggiunta di tre nucleotidi (-CCA, 3′) al terminale 3′ del trascritto immaturo. In alcuni tRNA i tre nucleotidi sono presenti nel gene corrispondente, in altri no; in ogni caso quasi tutti i tRNA sono soggetti a questa ricostruzione dell'estremità 3′ con funzione ignota.
e) Modificazioni di basi
Un tipo di maturazione dei trascritti è la trasformazione post-trascrizionale dei quattro nucleotidi originali (A, G, U, C) in residui modificati; nei tRNA è molto frequente e finora sono stati individuati oltre 50 nucleotidi modificati; le purine presentano modificazioni più complesse delle pirimidine. La loro distribuzione non è casuale: si trovano più facilmente nei tratti a singolo filamento delle strutture a forcina che concorrono alla versatilità funzionale di queste molecole, uniche nella loro capacità di riconoscere proteine (l'amminoacilsintetasi) e acidi nucleici (l'mRNA).
6. Codice genetico e sintesi proteica
I geni sono costituiti da differenti sequenze delle quattro basi del DNA e i loro prodotti da sequenze corrispondenti delle quattro basi dell'RNA o da differenti sequenze dei venti amminoacidi delle proteine. Specifiche mutazioni nei geni possono portare a specifici cambiamenti nelle proteine corrispondenti. La relazione che lega il linguaggio degli acidi nucleici con quello delle proteine e governata dal codice genetico; il processo che porta dai geni, attraverso gli mRNA, alle proteine è chiamato ‛traduzione' o ‛sintesi proteica'.
Sin dall'inizio degli anni sessanta considerazioni teoriche suggerivano che tre basi potessero bastare per codificare un amminoacido; successivamente una serie di convincenti esperimenti, conclusi entro il 1965, dimostrarono che la sintesi proteica era diretta da molecole di mRNA e che il messaggio genetico da esse portato consisteva nella successione di sequenze di tre basi. A esse si diede il nome di ‛triplette' o ‛codoni' e si verificò che assommano a 64 (43), cioè al numero di permutazioni anche ripetitive di quattro elementi, le basi, presi tre alla volta.
Particolarmente importante nella scoperta del codice genetico è stato il lavoro di H. G. Khorana (con Holley e Nirenberg vinse proprio per questo il Nobel nel 1968), che sintetizzò tutte le 64 possibili triplette sotto forma di ripetizioni polimeriche e dimostrò che questi mRNA sintetici, se aggiunti a estratti cellulari privi di mRNA, dirigevano la sintesi di proteine la cui sequenza amminoacidica era dettata sia dalle sequenze dell'RNA sintetico, sia dalla fase secondo cui tali sequenze venivano lette. Oli esperimenti di Khorana e di numerosi altri ricercatori dimostrarono inoltre che il messaggio genetico portato dagli mRNA è continuo e non sovrapposto, non contiene interpunzioni ma codoni specifici per l'inizio e la fine della traduzione ed è ridondante, come ci si deve aspettare dalla disponibilità di 64 triplette per 20 amminoacidi.
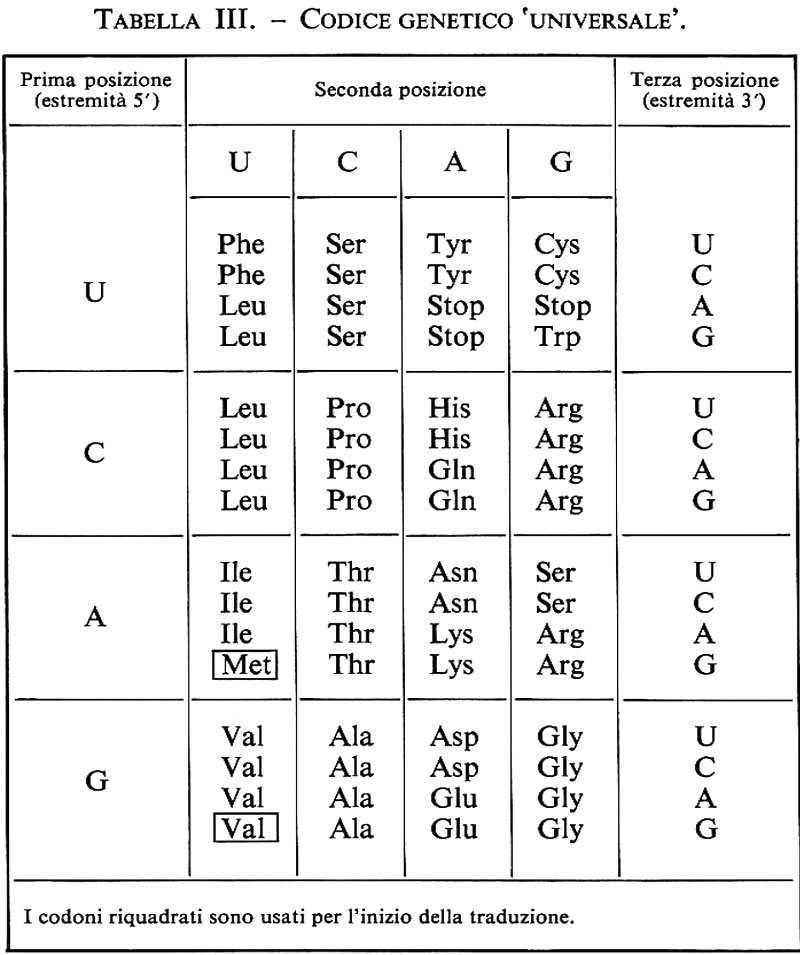
Il codice genetico viene ora rappresentato come nella tab. III: per individuare l'amminoacido codificato da una determinata tripletta basta identificarlo nella tabella e leggere le tre basi che ne costituiscono il codone: così per Trp (triptofano), contenuto nell'ultimo riquadro della prima riga, si identifica l'unica tripletta codificante, che risulta composta in prima posizione da U, in seconda da G e in terza ancora da G. Met (metionina) è codificata da A, U e G; Pro (prolina) da CCU, CCC, CCA e CCG; per Pro e per quasi tutti gli altri amminoacidi il codice genetico è quindi ridondante.
È importante ricordare che a ogni tratto di doppia elica di DNA possono corrispondere in teoria ben sei sequenze codificatrici diverse; esse risultano dalle tre diverse fasi di lettura per ognuno dei due possibili prodotti di trascrizione dei due filamenti del DNA. Non si riscontrano casi di simile supersfruttamento dell'informazione genetica, ma in alcuni virus la stessa regione di DNA origina sino a tre trascritti diversi, due sfasando la lettura dello stesso filamento del DNA, uno dal filamento complementare. In questo modo da una stessa regione del DNA si possono ottenere tre proteine diverse: ciò chiaramente complica la definizione molecolare di gene.
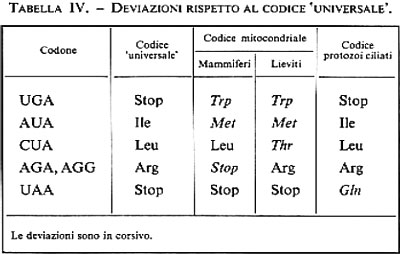
Un'altra caratteristica importante del codice è la sua universalità. Di recente sono state però scoperte delle eccezioni, dapprima limitate al codice dei mitocondri, poi estese a micobatteri e a protozoi ciliati. Esse riguardano soprattutto le triplette di stop, che nel codice ‛universale' sono tre, forse per garantire una più efficace terminazione della traduzione, mentre nei codici ‛non universali' sono due (v. tab. IV).
Nella sintesi proteica si distinguono tre stadi: inizio, allungamento, terminazione.
Inizio. - L'mRNA interagisce tramite la sua sequenza di Shine-Dalgarno (del tipo AAAGAGG) - che generalmente precede di poche basi la tripletta di inizio della traduzione, AUG- con la sequenza 3′-terminale dell'RNA 16S della subunità minore del ribosoma; questo complesso si associa poi con la subunità grande, sulla quale il tRNA che porta il primo amminoacido (metionina) di tutte le sequenze codificanti, ed è detto quindi ‛iniziatore' (Met-tRNAiMet), si è insediato nel sito detto P in risposta alla tripletta di inizio (AUG) e grazie al fattore di inizio (IF2 nei procarioti, eIF2 negli eucarioti). Sono richiesti anche GTP e altri fattori di inizio che, dopo essere stati usati, vengono rilasciati.
Allungamento. - Un nuovo amminoacido attivato e trasportato dal suo tRNA entra nell'adiacente sito A del ribosoma, in risposta alla tripletta che sull'mRNA segue quella di inizio e, grazie ai fattori proteici Tu e Ts e all'apporto energetico di GTP, si ha la formazione del primo legame peptidico (Met-Phe), la traslocazione del tRNA carico del dipeptide dal sito A al sito P e l'espulsione e il riciclaggio del tRNAiMet. La terza tripletta dell'mRNA è ora posizionata sul sito A e chiama un nuovo amminoacil-tRNA. Si ha sintesi del secondo legame peptidico in A, traslocazione, ecc., sino a tradurre l'intero mRNA.
Terminazione. - Sul sito A del ribosoma l'mRNA porta una delle tre triplette non senso o stop (UAA, UAG, UGA): anziché un tRNA questa tripletta chiama un fattore di terminazione, che rilascia nel citoplasma il peptide neoformato staccandolo dall'ultimo tRNA; a questo punto tutti i componenti vengono smontati e riciclati.
Nei procarioti sintesi, traduzione e degradazione dell'mRNA sono coordinate; negli eucarioti sono separate. Nei procarioti gli mRNA sono spesso policistronici, cioè contengono diverse unità di traduzione (dette anche ‛cistroni'); negli eucarioti sono in generale monocistronici e i polipeptidi vengono talvolta frazionati in proteine più piccole e funzionali.
7. Regolazione genica, differenziamento e sviluppo
Tutte le cellule di una popolazione di batteri discendenti da una singola cellula (clone) e tutte le cellule di un organismo multicellulare contengono lo stesso materiale genetico, tranne rare eccezioni (v. cap. 8). Nonostante questo, tanto le prime quanto le seconde possono essere profondamente diverse fra loro: basti pensare alle cellule vegetative di un batterio e alle sue spore; oppure, in un organismo superiore, qual è un mammifero, alle cellule del fegato e a quelle della pelle. Le cellule devono essere capaci di realizzare un programma di differenziamento e sviluppo che è geneticamente determinato; inoltre devono essere sufficientemente flessibili da rispondere a stimoli esterni.
Tutto questo è possibile in quanto il funzionamento di molti geni è regolato in modo da reagire prontamente a segnali cellulari ed extracellulari: i geni responsabili della sintesi di componenti essenziali delle cellule, quali alcuni enzimi coinvolti nella sintesi del DNA, funzionano in modo continuo e sono detti costitutivi. Altri geni, invece, funzionano solo quando richiesto (ad es. quando è presente una sostanza che deve essere metabolizzata o quando nel sistema di coltura manca un composto essenziale alla crescita delle cellule - un amminoacido, un nucleotide, ecc. -, che deve quindi essere sintetizzato), oppure quando si tratta di realizzare specifici piani di sviluppo e differenziamento. In questo caso si parla di geni regolabili, negativamente se repressi da un inibitore, positivamente se indotti da un effettore o attivatore.
Come già detto, in prima approssimazione la regolazione dei geni opera sulla loro trascrizione in RNA: in particolare può essere influenzata la frequenza d'inizio della trascrizione, la maturazione dei trascritti, la loro stabilizzazione e infine la loro traduzione in proteine. Un singolare modo di potenziare l'attività sintetica di un gene è l'aumento del numero di copie del gene stesso: il fenomeno è chiamato ‛amplificazione genica' ed è stato riscontrato in sistemi sia eucariotici che procariotici.
Mentre per alcuni fenomeni di differenziamento sono noti gli eventi e le strutture molecolari che ne sono responsabili, per altri si incomincia solo ora a intravedere qualche possibilità di approfondimento. Forse l'esempio meglio studiato di differenziamento è rappresentato dalla scelta tra via litica e via lisogenica da parte del DNA del virus lambda dopo infezione del batterio Escherichia coli. Nel primo caso (lisi) il virus distrugge la cellula dell'ospite e produce una progenie di un centinaio di particelle identiche a se stesso; nel secondo, invece, si stabilisce un'interazione molto più pacifica tra DNA virale e DNA batterico. Il primo si integra all'interno di una specifica sequenza del secondo e viene replicato passivamente insieme con il DNA batterico. Dei suoi circa quaranta geni uno solo viene espresso: è quello che codifica per la proteina detta CI, che funge da repressore delle altre funzioni virali. Il delicato meccanismo che porta CI a interagire con se stessa, con una sequenza del DNA di lambda detta OR (operatore di destra) e con la RNA-polimerasi dell'ospite determina la via di sviluppo adottata dal virus. Esso è stato in larga parte chiarito a livello delle interazioni tra i singoli amminoacidi del repressore e i nucleotidi posti nei solchi grandi della sequenza del DNA di OR. Questo rappresenta forse il più brillante esempio di descrizione di un meccanismo di regolazione genica attuato da molecole proteiche con funzioni di repressore e induttore (v. Ptashne, 1986).
Per gli organismi eucariotici, soprattutto per quelli pluricellulari, si è ancora lontani da questi livelli di analisi, ma per alcuni organismi si incominciano a individuare sistemi suscettibili di indagini egualmente sofisticate: il lievito con il locus MAT, che controlla il tipo coniugativo delle cellule aploidi; il nematode C. elegans, con le sue poco meno di mille cellule inattivabili una alla volta col laser; il moscerino D. melanogaster, in cui la comparsa e la funzione dei diversi segmenti larvali sono controllate da due complessi genici, detti appunto ‛di segmentazione' e ‛omeotici'. Dal loro corretto funzionamento deriva la comparsa nella larva dei gruppi di cellule ectodermiche detti ‛dischi immaginali', da cui si origineranno, nell'adulto, i tre segmenti cefalici, i tre segmenti toracici e gli otto segmenti addominali. I geni della segmentazione (per es. engrailed, fushi tarazu) determinano il numero dei segmenti, mentre quelli omeotici controllano la comparsa degli organi nel segmento appropriato. Mutazioni che colpiscano questi ultimi producono, infatti, variazioni qualitative e quantitative degli organi: per esempio mutazioni dette ‛nasobemia' causano la comparsa sul capo di zampe al posto delle antenne; mutazioni nel gene bithorax portano alla crescita sul terzo segmento toracico di ali rudimentali, le ‛altere', che possono raggiungere le dimensioni di quelle normali poste sul secondo segmento (v. Chisholm, 1986).
I geni della segmentazione e quelli omeotici sono stati identificati ed è stato scoperto che presentano sequenze altamente omologhe, dette homeoboxes, che codificano per una proteina di 60 amminoacidi. Homeoboxes a sequenza conservata sono state trovate in molti vertebrati (uomo compreso) e anche nel riccio di mare e nel lievito: ciò suggerisce che i loro prodotti genici, di cui è nota la capacità di legarsi al DNA e che risultano essenziali nelle fasi preliminari dello sviluppo degli eucarioti, svolgano un importante ruolo regolativo.
8. Elementi genetici mobili e riarrangiamenti nei geni degli anticorpi
Per molto tempo si è ritenuto che il DNA fosse il componente più stabile della cellula: a esso venivano rapportate le variazioni metaboliche di altri componenti cellulari, quali proteine ed RNA. In questi ultimi anni si sono però venute accumulando prove a favore di una notevole instabilità del genoma. Questa instabilità pare dovuta soprattutto alla presenza di elementi genetici mobili, ai quali è possibile ricondurre i quattro tipi principali di riarrangiamenti riscontrati nei cromosomi: inserzioni, delezioni, trasposizioni e amplificazioni.
Questi riarrangiamenti non alterano di solito la quantità totale di DNA presente in una cellula, né influiscono vistosamente sulla qualità del suo patrimonio genetico, che resta sostanzialmente lo stesso nonostante le opportunità di riarrangiamento offerte dalle numerose replicazioni che portano dallo zigote alla cellula differenziata: tranne che in alcuni casi, il patrimonio genetico cellulare pare conservare infatti la sua identità e quindi anche la sua ‛totipotenza'. Questo è stato dimostrato, almeno per gli Anfibi, dagli esperimenti di Gurdon e altri, che negli anni sessanta trapiantarono nuclei di cellule somatiche differenziate di rospo in oociti e ottennero, anche se con basse frequenze, cloni di individui identici al donatore dei nuclei. Questa stabilità sembra verificarsi in generale, tranne che nel caso dei riarrangiamenti genici che portano alla sintesi delle immunoglobuline (v. sotto) e alle variazioni delle proteine di superficie nei tripanosomi.
Tra i riarrangiamenti cromosomici particolare interesse rivestono le trasposizioni di elementi genetici mobili. Tutte le cellule ne contengono, con caratteristiche strutturali simili, anche se mobilizzabili con meccanismi diversi. I più semplici sono le cosiddette ‛sequenze di inserzione', o IS: ne sono note sei in E. coli, tutte funzionalmente caratterizzabili solo in modo negativo, in quanto causano l'inattivazione dei geni nei quali vengono (a caso, pare) inserite. Più informativa è la loro caratterizzazione strutturale: sono lunghe circa 1.000 basi e la loro comparsa porta alla duplicazione, ai loro lati, di brevi sequenze del DNA dove è avvenuta l'inserzione.
Di solito le IS non contengono sequenze codificatrici, ma può accadere che entro le IS si inseriscano geni codificanti - per es. la resistenza a un antibiotico - o un gene che codifica per un enzima coinvolto, in modo ancora imprecisato, nell'evento stesso di trasposizione, detto ‛transposasi', e talvolta anche un gene per un suo repressore; in tali casi si ha un ‛transposone' o Tn.
La struttura classica di un transposone comporta la presenza, ai suoi due estremi, di sequenze ripetute in modo diretto lunghe qualche centinaio di basi, fiancheggiate all'interno da brevi duplicazioni (5 ÷ 10 basi) della sequenza bersaglio (la sequenza di DNA entro la quale si traspone l'elemento mobile), come nel caso delle IS. I Tn sono lunghi qualche migliaio di basi e di solito entrano nel nuovo sito mediante un meccanismo di copiatura o replicazione ‛conservativa', che lascia una copia di Tn nel sito di origine e ne produce un'altra nel sito di trasposizione.
Sono noti altri esempi di riarrangiamenti cromosomici in procarioti (variazioni di fase nei geni della flagellina in Salmonella, assemblaggio e attivazione dei geni per la fissazione di N2 in Anabaena), che non richiedono la replicazione del DNA coinvolto.
Il fenomeno della trasposizione è noto anche negli eucanoti: la scoperta dei Tn in realtà avvenne proprio negli eucarioti, grazie all'intuizione di B. McClintock. Oltre trenta anni fa la McClintock spiegò con la trasposizione di elementi mobili di controllo la comparsa di variazioni reversibili nella colorazione della cariosside del mais, ma è stata premiata con il Nobel solo nel 1983. Oggi i Tn sono stati rinvenuti in quasi tutti gli organismi, dal lievito (Ty) ai Mammiferi (sequenze Alu), e risultano accomunati da interessanti analogie strutturali e funzionali. Gli elementi comuni del Tn eucariotico tipico sono la consueta ripetizione diretta di 5 ÷ 10 basi delle sequenze bersaglio alle due estremità e, procedendo verso l'interno del Tn, ripetizioni invertite di 10 ÷ 50 basi (simili a quelle delle IS dei Tn batterici?), che fanno parte di sequenze più lunghe, da 250 a 600 basi, chiamate LTR (Lunghi Terminali Ripetuti) e caratterizzate dalla presenza di singole triplette TGT e ACA alle estremità. Al centro si trovano gli elementi genetici mobili, lunghi qualche migliaio di basi.
Caratteristico dei Tn eucariotici è il meccanismo di trasposizione: a differenza di quello dei Tn procariotici, richiede l'intervento di intermedi a RNA e quindi implica fenomeni di trascrizione prima e di retrotrascrizione poi. Meccanismi simili operano nella trasposizione dei Retrovirus, oggetto di intenso e assiduo studio negli Uccelli e soprattutto nei Mammiferi, per l'importanza delle malattie che possono causare (dai tumori all'AIDS).
Probabilmente trasposte nel genoma di mammifero mediante coinvolgimenti di RNA sono anche le già citate sequenze Alu. Se ne contano diverse centinaia di migliaia di copie e ciascuna è lunga circa 150 ÷ 300 basi: esse ammontano da sole, quindi, a qualche percento del genoma umano. Sono considerate tipici esempi di sequenze mediamente ripetitive, intersperse a caso soprattutto tra unità trascrizionali, oppure entro sequenze introniche. Il nome ‛sequenze Alu' deriva dalla presenza di un sito di restrizione per questo enzima all'interno di molte di queste sequenze. Poco si sa sulla loro funzione: è possibile che vengano usate nella replicazione del DNA, in considerazione della presenza di una sequenza di 14 basi riscontrata anche nell'origine della replicazione di numerosi virus a DNA. Le sequenze Alu di solito vengono trascritte dalla RNA-polimerasi II, quella che produce gli mRNA.
Oltre alle sequenze Alu, è pure probabile che dai Tn si siano evoluti altri elementi genetici mobili, quali i plasmidi e successivamente i virus: per ottenere i primi è stato sufficiente che un ipotetico Tn ancestrale abbia incorporato un'origine di replicazione autonoma; per ulteriore aggiunta di sequenze geniche responsabili della sintesi di strutture morfogenetiche e biosintetiche si potrebbe originare un'altrettanto ipotetica particella virale.
Anche gli pseudogeni (v. cap. 2, § a) probabilmente derivano da retrotrascrizione di mRNA a diverso grado di maturazione e quindi dalla loro inserzione in punti casuali del genoma. La loro analogia con i Tn è confermata dalla presenza di ripetizioni dirette di circa 10 basi alle estremità.
Di particolare interesse sono gli eventi traspositivi che portano alla sintesi delle immunoglobuline. Queste rappresentano circa il 20% delle proteine del sangue e possono arrivare a essere oltre 1011 diverse molecole: dal momento che per codificarle sarebbero necessarie oltre 1014 basi, cioè centomila volte più DNA di quanto ne contiene una cellula diploide umana, il problema della genesi della diversità anticorpale è uno dei più interessanti della biologia molecolare. La sua soluzione è stata ottenuta grazie alla comprensione della struttura dei geni delle immunoglobuline: essa è risultata diversa nelle cellule germinali rispetto alle cellule somatiche che successivamente producono gli anticorpi (plasmacellule). Riarrangiamenti e trasposizioni permettono l'apposizione della sequenza per una regione variabile (V) a quella chiamata D (per diversità) e infine alla regione costante (C). Da notare le ulteriori possibilità di variazione dovute alla presenza di regioni N, dette cosi perché alcuni nucleotidi potrebbero esservi inseriti a caso dall'enzima polimerizzante ‛transferasi-terminale'.
Un altro evento che porta a variazioni di DNA in determinate cellule o in speciali condizioni è la già citata amplificazione genica: nelle uova di Anfibi, per far fronte alla maggior produzione di proteine richiesta dallo sviluppo dell'organismo, si ha amplificazione di migliaia di volte dei geni per l'rRNA: il meccanismo che ne è responsabile è la loro replicazione attraverso strutture tipo circolo rotante. Da notare che il corrispondente aumento delle proteine ribosomiche, necessarie a costituire i ribosomi richiesti dall'intensificata attività biosintetica, è invece ottenuto elevando il tasso di trascrizione dei geni corrispondenti.
9. Segnalazioni fra ed entro le cellule
In generale le cellule rispondono a segnali esterni riprogrammando almeno in parte la propria attività biosintetica. Questo richiede che lo stimolo extracellulare venga trasdotto sino al nucleo e qui induca particolari geni a produrre sostanze che mediano la risposta cellulare. Il messaggio esterno, portato da composti detti ‛primi messaggeri', di solito non penetra fisicamente entro le cellule bersaglio, ma viene ricevuto da strutture poste per lo più sulla membrana plasmatica, dette ‛recettori': questi trasformano il primo messaggero in un segnale che viene captato e trasformato in un ‛secondo messaggero', che trasferisce poi il segnale al sito di destinazione finale, di solito il nucleo.
Le cellule comunicano attraverso contatti fisici diretti, oppure a distanza. Si distinguono quindi segnalazioni ‛endocrine' - grazie alle quali determinati ormoni (quale, per es., il somatotropo o ormone della crescita, che è sintetizzato nell'ipofisi) sono secreti dalle cellule che li producono e raggiungono tramite i vasi sanguigni le cellule bersaglio che devono, ad esempio, essere stimolate a crescere - e segnalazioni ‛paracrine', quando la cellula che produce il segnale è vicina o attaccata alle cellule cui il messaggio è destinato: neurotrasmettitori e neurormoni sono tipici segnali paracrini. Esiste un terzo tipo di segnalazione cellulare, detta ‛autocrina', di solito associata a situazioni patologiche, quali i tumori, in cui le cellule autostimolano la propria crescita mediante la sintesi di fattori che agiscono come segnali sulla cellula stessa che li produce. Sostanze secrete da un organismo (di solito microbico) possono venire captate da un altro organismo della stessa specie che modifica in risposta il proprio comportamento: questo è anche il caso di insetti che rilasciano ‛feromoni' per attirare individui di sesso opposto.
Gli stadi attraverso i quali passa la comunicazione extracellulare sono distinguibili come segue: 1) sintesi del primo messaggero da parte della cellula segnalatrice; 2) rilascio extracellulare; 3) trasporto verso la cellula bersaglio; 4) ricezione da parte della cellula bersaglio mediante specifici recettori; 5) trasduzione e internalizzazione del segnale; 6) risposta.
La segnalazione tra le cellule viene realizzata da due categorie di composti: 1) ormoni liposolubili (steroidi e derivati) che diffondono attraverso la membrana plasmatica e interagiscono con recettori citoplasmatici o addirittura nucleari; 2) ormoni peptidici e idrosolubili (tipo adrenalina), che interagiscono con recettori esterni.
La rete di segnalazioni intere intracellulare usa come sistemi ricevente e trasmittente i recettori. In generale si tratta di composti di natura proteica, spesso glicosilati. Il numero dei recettori può oscillare in risposta a variazioni del flusso dei segnali ed è controllato geneticamente. Alcuni recettori internalizzano il segnale per endocitosi (ad es. quelli dell'insulina), se ne distaccano e poi vengono riciclati. Altri svolgono attività enzimatica stimolata dalla molecola del ligando: ad esempio, i recettori dell'ormone della crescita sono catene polipeptidiche la cui estremità carbossilica intracellulare ha attività fosforilante nei confronti di residui di tirosina su varie proteine intracellulari, per ora ancora in gran parte sconosciute.
L'interazione tra ormoni, quali il glucagone e l'adrenalina, e recettori di superficie induce l'attivazione di un enzima, l'adenilatociclasi, che trasforma ATP in AMP ciclico (cAMP). Questa interazione è mediata da una proteina che, in risposta al legame dell'ormone col recettore, reagisce con GTP. L'accumulo di cAMP causa un aumento di attività fosforilante nei confronti di diverse proteine. È noto, ad esempio, il caso della glicogenolisi indotta da adrenalina nel fegato e nel muscolo, dove una proteincinasi dipendente da cAMP fosforila l'enzima glicogenosintetasi e ne causa così l'inattivazione.
Nei casi in cui l'interazione tra ligando e recettore avviene sulla membrana plasmatica, il segnale arriva alle centrali operative della cellula, cioè al suo nucleo o ai suoi organelli, trasportato dai cosiddetti ‛secondi messaggeri': questi sono in numero sorprendentemente limitato, a suggerire che i canali di trasmissione intracellulare dei segnali sono universali. Oltre al cAMP essi utilizzano altri composti fosforilati, come l'inositolotrifosfato e il cGMP, il diacilglicerolo e gli ioni calcio.
In generale i secondi messaggeri si legano alla porzione regolatrice di un enzima che fosforila proteine (proteincinasi): le proteincinasi attivano a loro volta risposte tipo contrazione e secrezione. Il Ca2+, ad esempio, si lega a una famiglia di proteine, che include la calmodulina e la troponina: la calmodulina attiva un'altra proteinasi e la troponina stimola la contrazione muscolare.
Le evidenze a favore di un'interazione diretta tra ormoni steroidei e proteici e nucleo cellulare, con effetti di lunga durata, sono molteplici: basterà citare l'induzione di proteine dell'albume nell'ovidotto di gallina da parte di estrogeni, la stimolazione della sintesi di proteine nel fegato da parte di glucocorticoidi e la stimolazione della sintesi delle caseine nelle ghiandole mammarie da parte del progesterone e della prolattina. In questi casi è stato possibile evidenziare l'accumulo nel nucleo di complessi ormone-recettore che, legandosi a sequenze di DNA che incominciano a essere identificate, portano alla sintesi di nuovi mRNA.
10. Oncogeni
I tumori sono masse di cellule che derivano da una singola cellula nella quale, a seguito di eventi diversi, quali infezioni virali, esposizione a sostanze chimiche, irradiazioni, è stato perduto il controllo della divisione cellulare. La massa cellulare che ne risulta può essere un tumore benigno, se le cellule restano localizzate nel sito di origine, o maligno, se le cellule, superata la lamina basale che delimita il tessuto, vengono portate in circolo dal sangue, si installano in altri tessuti e vi proliferano, dando origine a metastasi.
Molte delle proprietà tipiche delle cellule tumorali possono essere riprodotte in provetta usando colture di cellule trasformate: tra le più importanti sono forse l'invasività e la diffusibilità. Si tratta evidentemente di problemi di interazioni cellulari, ed è per questo che l'argomento è trattato qui.
Tra i virus che possono indurre tumori negli animali ve ne sono sia a DNA che a RNA: entrambi i tipi trasformano le cellule introducendo nuovi geni nel genoma della cellula infettata. Nei virus a DNA (Papovavirus) i geni trasformanti sono coinvolti nella comparsa di nuove proteine che inducono nella cellula uno stato di crescita. I virus a RNA, detti Retrovirus in quanto il loro materiale genetico è costituito da molecole di RNA che vengono retrotrascritte in DNA e quindi integrate in posizioni variabili del DNA della cellula ospite, possono diventare tumorali in due modi. Uno consiste nella trasduzione di particolari geni cellulari, detti protoncogeni o oncogeni cellulari, che nel loro contesto normale non causano tumori; questi geni però, incorporati nel DNA virale, a seguito di un'infezione della cellula da parte del retrovirus così modificato, possono concorrere a indurne la trasformazione neoplastica. L'altro modo comporta l'integrazione del retrovirus in un protoncogene, la cui espressione varia, di conseguenza, diventando in tal modo un oncogene a tutti gli effetti.
Sono noti oltre venti diversi protoncogeni che possono diventare oncogeni effettivi: essi codificano per proteine coinvolte nella normale crescita cellulare ma che, per effetto anche di una singola sostituzione amminoacidica o per una variazione nel livello o nel momento o nella normale sede di sintesi, alterano il regolare funzionamento della cellula.
Spesso queste proteine sono enzimi fosforilanti (cinasi) specifici per tirosine (v. cap. 9), oppure sono simili a fattori di crescita, dei quali il primo, responsabile della crescita dei nervi, fu scoperto da R. Levi Montalcini, premio Nobel 1986. Particolarmente coinvolto in questi processi pare il fattore derivato dalle piastrine, così come i fattori che legano il nucleotide guanosinafosfato e quelli dotati di attività GTP-asica o che fungono da regolatori della trascrizione.
Gli oncogeni sono coinvolti anche nella cancerogenesi chimica: le sostanze carcinogeniche possono essere di varia natura (metilnitrosourea, aflatossina, benzopirene) ma devono presentare tutte una reattività di tipo elettrofilo, che permette loro di reagire con il DNA, alterandone la sequenza e causando translocazioni o amplificazioni, con l'induzione finale di stati tumorali.
Qualunque sia lo specifico agente induttore, pare accertato che la comparsa di un tumore richieda la presenza e l'attivazione di più di un oncogene: sembrerebbe quindi che cambiamenti genetici siano di fondamentale importanza nella comparsa, nel mantenimento e nella diffusione dei tumori, ed è sulla base di questa congettura che si orienta la maggior parte delle attuali ricerche.
Recenti acquisizioni portano inoltre a ritenere che la comparsa di uno stato neoplastico non richieda solo fenomeni di attivazione genica, ma anche, come nel caso del retinoblastoma (v. Kundson, 1985), l'inattivazione di funzioni essenziali per il controllo della crescita cellulare.
11. Ingegneria genetica
L'ingegneria genetica è una tecnica che permette il trapianto di geni in cellule evolutivamente diverse da quelle dalle quali deriva il gene trapiantato, utilizzando principi e metodi della genetica, della microbiologia, della biochimica, della chimica e della biologia molecolare. La sua portata può essere compresa per intero se si pensa che l'evoluzione naturale ha elaborato, attraverso centinaia di milioni di anni, un a serie di misure che concorrono a minimizzare la possibilità di scambi promiscui di geni tra individui di specie diverse. Infatti in generale le cellule non sono permeabili al DNA; inoltre in diversi procarioti sono stati scoperti degli enzimi che attaccano i DNA estranei: sono chiamati endonucleasi di restrizione e, per ironia, si sono rivelati strumenti fondamentali nello sviluppo dell'ingegneria genetica.
Negli organismi eucariotici esistono membrane cellulari e nucleari che proteggono il materiale genetico endogeno e, sui gameti femminili, recettori glicoproteici specifici per proteine di superficie dei gameti maschili, che permettono solo la fecondazione omologa. Infine il diverso assetto cromosomico dei due gameti partners innaturali impedisce di solito il corretto sviluppo di uova entro le quali fossero accidentalmente penetrati spermatozoi di una specie diversa.
L'ingegneria genetica permette invece un libero scambio di geni tra individui tanto diversi quanto piante e animali, Batteri e Mammiferi. Esso può essere realizzato a livello molecolare così come a livello cellulare: nel primo caso comporta l'assorbimento, da parte di una cellula, di un'appropriata combinazione di molecole di DNA purificate e manipolate in provetta; nel secondo caso può risultare da un'operazione di tipo citologico, qual è la fusione, o ibridazione, di cellule somatiche, che ha ad esempio portato alla produzione di ibridomi, o cellule ibride capaci di produrre anticorpi monoclonali. Sempre maggiore favore incontra la tecnica detta microiniezione, che permette di iniettare direttamente entro il nucleo di cellule minuscoli volumi di soluzione di singoli geni, poche decine di copie disciolte in goccioline dell'ordine di grandezza del picolitro, cioè di un miliardesimo di millilitro.
Gli obiettivi dell'ingegneria genetica sono di duplice natura, scientifica e applicata: da una parte, grazie a essa, si è potuto rilanciare all'inizio degli anni settanta una ricerca di base in genetica molecolare che a molti sembrava incapace di progredire, soprattutto per quel che riguarda i sistemi eucariotici più complessi; dall'altra si è avviata un'attività produttiva che ha portato alla creazione di una vera e propria industria, genericamente chiamata ‛biotecnologica' biotecnologie).
Storicamente si fa iniziare lo sviluppo dell'ingegneria genetica con tre scoperte fondamentali avvenute tra gli anni sessanta e settanta: 1) la sintesi totale di geni; 2) la possibilità di frammentare in modo preciso qualsiasi molecola di DNA e di ricombinarne in provetta i frammenti con quelli di un'altra molecola di DNA prodotti allo stesso modo; 3) la messa a punto di sistemi artificiali che permettono l'ingresso delle molecole cosi prodotte entro cellule ospiti.
Indicano tecnologie dell'ingegneria genetica, e sono spesso usati come suoi sinonimi, i termini ‛tecnologia del DNA ricombinante' e ‛clonazione': col primo si indica la produzione in provetta di combinazioni geniche ‛nuove' rispetto a quelle ‛naturali'; col secondo si intende la produzione di colonie di cellule, per lo più batteriche, contenenti tutte un determinato gene estraneo e discendenti da una singola cellula trasformata a seguito dell'introduzione o di una struttura ricombinante artificiale contenente quel gene o del gene stesso (v. Sgaramella, 1975).
a) Sintesi di geni
Grazie soprattutto al lavoro di H. G. Khorana, a partire dagli anni sessanta è stata sviluppata una tecnologia di tipo organo-sintetico (detta ‛sintesi totale') che permette di produrre oligonucleotidi a sequenza predeterminata e di lunghezza che di recente ha superato il centinaio di unità. Il principio fondamentale di questa tecnica consiste nel proteggere tutti i gruppi funzionali dei nucleotidi che si vogliono unire, tranne quelli che devono formare il legame fosfodiesterico (5′P o 5′OH e 3′OH o 3′P) e nell'attivare questi ultimi mediante appropriati reagenti. In questo modo a partire dal primo nucleotide, preferibilmente attaccato a un supporto solido per semplificare la successiva purificazione del prodotto, si allunga la catena per aggiunta di singoli nucleotidi. L'importanza della sintesi di geni è dimostrata, per esempio, dal suo ruolo nella scoperta del codice genetico e dalla sua diffusione nei laboratori di ingegneria genetica di tutto il mondo, diffusione favorita anche dal grado di sofisticazione e di efficienza raggiunto dagli apparecchi che possono effettuarla in modo del tutto automatizzato (v. Ferretti e altri, 1986).
Essa è particolarmente utile nei processi di sintesi di geni ibridi o mutati e di adattatori contenenti siti di restrizione da usare per l'unione di blocchi di geni; è fondamentale nelle reazioni di mutagenesi sito-specifica e nella preparazione di sonde molecolari che, marcate con radioisotopi o con cromofori, possono servire per individuare particolari sequenze in genomi complessi come quelli degli eucarioti, dopo che sono stati frammentati con enzimi di restrizione e risolti per elettroforesi (tecnica di Southern). I geni possono essere sintetizzati anche in vitro con procedure enzimatiche, usando la transcrittasi inversa che produce sequenze di DNA a partire da RNA.
b) Endonucleasi di restrizione
La caratteristica delle endonucleasi di restrizione è la capacità di riconoscere brevi sequenze ‛bersaglio' di DNA e di produrre dei tagli nella doppia elica, in corrispondenza (tipo II) o nelle vicinanze (tipo III) delle sequenze riconosciute o a una distanza variabile da esse (tipo I). Questi enzimi, meglio di altre strutture, evidenziano la differenza tra procarioti ed eucarioti: contro oltre duecento endonucleasi di restrizione sinora scoperte nei primi, solo pochi e poco convincenti dati sono comparsi circa la loro presenza nei secondi.
Esistono diversi tipi di endonucleasi di restrizione: spesso sono accoppiate ad altri enzimi (metilasi), pure ad azione sequenza-specifica, che riconoscono le sequenze bersaglio e le modificano in modo che non vengano più riconosciute e tagliate dalle endonucleasi.

Le endonucleasi di restrizione più studiate sono forse quelle di tipo II (v. tab. V); di estremo interesse è il fatto che le estremità prodotte da queste endonucleasi di restrizione siano saldabili fra loro a opera delle DNA-ligasi (v. Sgaramella, 1972); è stata questa scoperta che ha dato l'avvio alla tecnologia del DNA ricombinante. Le sequenze bersaglio sono lunghe 4 ÷ 8 coppie di basi e sono caratterizzate spesso da una simmetria binaria (sono quindi dette palindromiche). Il riconoscimento da parte dell'enzima avviene nel solco grande della forma B del DNA, interessa gruppi funzionali delle basi non impegnati nei legami a idrogeno tra basi complementari e talvolta comporta una leggera piegatura della doppia elica.
c) Vettori e sistemi di trapianto genico
La scoperta di vettori molecolari e di sistemi di trapianto genico è un capitolo di fondamentale importanza nello sviluppo dell'ingegneria genetica e continua a rappresentarne uno degli aspetti più stimolanti.
Perché un gene estraneo funzioni entro una cellula ospite, occorre che siano soddisfatte numerose condizioni: a) il gene estraneo deve penetrare nella cellula o nel suo nucleo; b) non deve venire degradato o riarrangiato; c) deve venire replicato stabilmente e passato alle cellule figlie; d) deve venire ‛espresso', cioè la sua informazione genetica deve essere decodificata; e) la sua presenza e la sua espressione non devono essere dannose per la cellula ospite.
Un frammento di DNA che sia penetrato in qualsiasi modo in una cellula non potrà come tale venire replicato e quindi passato alle generazioni successive; perché questo avvenga il frammento deve entrare a far pare di un ‛replicone' o unità funzionale di replicazione della cellula ospite. In risposta a questa esigenza sono stati sviluppati i ‛vettori molecolari', molecole di DNA di dimensioni maneggevoli (3 ÷ 50 migliaia di coppie di basi) e dotate di tutti i segnali necessari alla replicazione e all'espressione dei geni trapiantati. I vettori più usati derivano da plasmidi, elementi genetici citoplasmatici accessori presenti in piu copie rispetto ai cromosomi fondamentali, oppure da genomi di virus, siano essi a DNA o a RNA, capaci di infettare le cellule e di replicarvisi come entità autonome, oppure di integrarsi nel genoma dell'ospite (v. cap. 4).
Le ultime generazioni di vettori molecolari sono strutture ricombinanti molto complesse, caratterizzate dalla presenza di elementi genici di origine diversa e dotati: 1) della capacità di replicazione in E. coli, per permetterne un'ampia produzione e una completa analisi; 2) della capacità di replicazione (o integrazione) nella cellula ospite finale (ad es. in una cellula di mammifero); 3) di segnali genetici che permettono un efficiente e regolato funzionamento del gene donato; 4) di marcatori genetici o sistemi selettivi che consentono di distinguere o di selezionare le cellule che hanno ricevuto il trapianto genico dalle altre, che di norma sono la grande maggioranza; 5) di segnali che eventualmente portano alla secrezione del prodotto desiderato nel mezzo di coltura. Vettori dotati di queste proprietà sono disponibili per quasi tutti i tipi di cellule, così come si stanno approntando sistemi, quale ad esempio la microiniezione, che ne permettono un'efficiente introduzione.

Grazie a un esplosivo sviluppo di queste metodologie, l'ingegneria genetica in questi ultimi cinque anni ha impresso alla ricerca biologica un'accelerazione probabilmente senza precedenti. Ne sono risultate rivoluzionate tanto le ricerche di base, quanto l'attività produttiva, nonché le applicazioni analitico-diagnostiche in medicina (v. biotecnologie). Tra le prime possiamo ricordare i progressi fatti nella caratterizzazione di geni complessi di mammiferi, quale ad es. il gene umano per il fattore VIII della coagulazione ; nell'ambito dell'attività produttiva basterà ricordare la produzione mediante ingegneria genetica di insulina umana, di ormoni di crescita, di interferoni e di interleuchine, di vaccini, di agenti trombolitici e di immunoregolatori (v. tab. VI). Per quel che riguarda le applicazioni diagnostiche e terapeutiche, sono noti gli sviluppi che hanno portato di recente all'uso di sonde molecolari costituite da brevi sequenze nucleotidiche (sintetizzate ex novo o isolate da materiale naturale) per la diagnosi prenatale di malattie genetiche, quali l'emofilia A, l'anemia falciforme, la fibrosi cistica e la corea di Huntington, per citarne solo alcune, o alla manipolazione genetica diretta a modificare cellule responsabili di devastanti malattie, quali la sindrome di Lesch-Nyhan (v. Hooper e altri, 1987) o altri disturbi immunologici, mentre si stanno anche studiando protocolli tendenti a manipolare il patrimonio genetico di animali e piante di interesse economico al fine di potenziarne le prestazioni. In questo modo l'ingegneria genetica esce dal chiuso dei laboratori o degli impianti e affronta ambienti aperti o si cimenta col patrimonio genetico dell'uomo stesso.
Si è venuto cosi creando, forse in modo non deliberato, il presupposto per un intervento dell'uomo nel processo evolutivo dell'intera biosfera. Da alcune parti si teme che il progresso tecnologico stia sorpassando la responsabilità etica dell'uomo moderno (v. Sgaramella, 1979).
12. Conclusioni
Per molto tempo la biologia molecolare è stata una scienza in cerca di una definizione: F. H. C. Crick, uno dei suoi più autorevoli cultori, sosteneva che la biologia molecolare è quello di cui si occupano i biologi molecolari. Questo era vero 30 anni fa e forse lo è tuttora. Oggi però è possibile fornire indicazioni più illuminanti: la biologia molecolare è diventata biologia della cellula, non solo procariotica, ma anche eucariotica. Le principali funzioni cellulari possono essere oggi studiate a livello molecolare con approcci che in molti casi si stanno rivelando di insperata efficacia: basti pensare a problemi quali il differenziamento o la risposta immunitaria.
La biologia molecolare sta trasformando lo studio della biologia in diversi sensi: superata la fase puramente descrittiva, è oggi in grado di utilizzare le conoscenze acquisite per modificare le strutture studiate, manipolandole in modo mirato. L'ingegneria genetica, in particolare, non solo si sta dimostrando un efficace strumento per l'analisi della complessità della cellula eucariotica, ma sta offrendo ai biotecnologi la possibilità di creare nuovi organismi dotati di proprietà economicamente utili e ai medici protocolli diagnostici e forse terapeutici (terapia genica) di grandissimo interesse. Ma se alcune di queste possono essere considerate estrapolazioni verso un futuro che peraltro forse è meno lontano di quello che si tende a credere, è anche per la comprensione del passato che la biologia molecolare sta fornendo strumenti di indagine nuovi ed efficaci: lo studio dell'evoluzione molecolare si sta affiancando alla paleontologia e all'anatomia comparata per chiarire il mistero dell'origine e dello sviluppo della vita. Il cammino che sta davanti ai ricercatori è molto più lungo e impegnativo di quello finora percorso: basti pensare alla complessità dei problemi della neurobiologia, della esobiologia e della senescenza. Pare comunque probabile che, forse tra qualche decennio, non si parlerà più di biologia molecolare o non molecolare, ma soltanto di biologia, e alla sua unificazione concettuale quella che nella seconda metà degli anni ottanta viene ancora chiamata biologia molecolare avrà dato un contributo non secondario.
bibliografia
Alberts, B., Bray, O., Lewis, J., Raff, M., Roberts, K., Watson, J. D., Biologia molecolare della cellula, Bologna 1984.
Chambon, P., Split genes, in ‟Scientific American", 1981, CCXLIV, 5, pp. 60-71.
Chisholm, R. L., Homeoboxes: what do they do, in ‟Trends in genetics", 1986, II, pp. 224-225.
Chou, L.T. e altri, An amazing sequence arrangement at the 5′ end of Adenovirus 2 messenger RNA, in ‟Cell", 1977, XII, pp. 1-8.
Crick, F. H. C., Orgel, L., Selfish DNA: the ultimate parasite, in ‟Nature", 1980, CCLXXXIV, pp. 604-607.
Darnell, L., Lodish, H., Baltimore, D., Molecular cell biology, New York 1986.
Doolittle, W. F., Sapienza, C., Selfish genes, the phenotype paradigm and genome evolution, in ‟Nature", 1980, CCLXXXIV, pp. 601-603.
Du Praw, E. J., DNA and chromosomes, New York-Sydney 1970.
Falaschi, A., Struttura e sintesi del DNA. Quaderni di Biologia, Padova 1975, pp. 1-64.
Ferretti, L., Karnik, S. S., Khorana, H. G., Nossal, M., Oprian, D. D., Total synthesis of a gene for bovine rhodopsin, in ‟PNAS", 1986, LXXXIII, pp. 559-603.
Gilbert, W. e altri, On the antiquity of introns, in ‟Cell", 1986, XLVI, pp. 151-153.
Gitschier, J. e altri, Characterization of human factor VIII gene, in ‟Nature", 1984, CCCXII, pp. 326-347.
Hooper, M. e altri, HPRT-deficient (Lesch-Nyhan) mouse embryos derived from germline colonization of cultured cells, in ‟Nature", 1987, CCCXXVI, pp. 292-298.
Kang, D. S., Wells, R. D., B-Z DNA junctions contain few, if any, non paired bases ad physiological superhelical density, in ‟Journal of biological chemistry", 1985, CCLX, pp. 7783-7790.
Karnik, P., Gopalakrishna, Y., Sarkar, N., Construction of a cDNA library from polyadenylated RNA of Bacillus subtilis and the determination of some 3′-terminal sequences, in ‟Gene", 1986, IL, pp. 161-165.
Kornberg, A., DNA replication, San Francisco 19802.
Kornberg, A., Supplement to DNA replication, San Francisco 1982.
Kundson, A. C., Hereditary cancer, oncogenes and antioncogenes, in ‟Cancer research", 1985, XLV, pp. 1437-1443.
Lewin, B., Genes, New York 19852.
Old, R. W., Primrose, S. B., Principles of gene manipulation, Oxford 19853.
Ptashne, M., Phage lambda: a genetic switch, New York 1986.
Schleif, R., Genetics and molecular biology, Reading, Mass., 1985.
Sgaramella, V., Enzymatic oligomerization of SV40 DNA and P22 DNA, in ‟PNAS", 1972, LXXII, pp. 1045-1046.
Sgaramella, V., Ingegneria genetica, Padova 1975.
Sgaramella, V., Reality, psychosis and myth in genetic engineering, in Scientific culture in the contemporary world (a cura di V. Mathieu e P. Rossi), Paris 1979, pp. 205-226.
Shinozaki, K. e altri, The complete nucleotide sequence of the tobacco chloroplast genome: its gene organization and expression, in ‟EMBO journal", 1986, V, pp. 2043-2049.
Snyder, M. e altri, Bent DNA at a yeast autonomously replicating sequence, in ‟Nature", 1986, CCCXXIV, pp. 87-89.
Stryer, L., Biochemistry, San Francisco 19812.
Van Dilla, M. A. e altri, Human chromosome-specific DNA libraries. Construction and availability, in ‟Biotechnology", 1986, IV, pp. 537-552.
Watson, J. D., Tooze, J., Kurtz, D. T., Recombinant DNA: a short course, New York 1983.
Zang, A. J., Been, M. D., Cech, T. R., The Tetrahymena ribozyme acts like an RNA restriction endonuclease, in ‟Nature", 1986, CCCXXIV, pp. 429-443.