
corpora di italiano
corpora di italiano
Definizione
I cosiddetti corpora (sing. corpus) linguistici sono collezioni, per lo più di grandi dimensioni, di testi orali o scritti prodotti in contesti comunicativi reali (per es., registrazioni di discorsi o articoli di giornale), conservati in formato elettronico e spesso corredati di strumenti di consultazione informatici.
I corpora permettono di osservare l’uso effettivo di una lingua e di verificarne tendenze generali su base statistica (Lüdeling & Kytö 2008 e 2009). Rivestono un’importanza fondamentale nella lessicografia contemporanea, all’interno della quale sono utilizzati tra l’altro per selezionare lemmi in base alla loro frequenza d’uso, per identificare le costruzioni tipiche in cui una parola occorre e per coglierne le sfumature di senso in base ai contesti.
I corpora sono inoltre uno strumento importante nello sviluppo di tecnologie linguistiche quali la traduzione automatica e il riconoscimento automatico del parlato, in cui servono a costruire modelli statistici della lingua. Sono utilizzati anche nell’insegnamento delle lingue, dove possono essere un sussidio per la costruzione di materiali didattici e permettono, soprattutto agli apprendenti avanzati, di inferire proprietà di parole e costruzioni osservandone i contesti d’uso. Infine, i linguisti teorici affiancano oggi dati estratti dai corpora a fonti più tradizionali, quali le intuizioni linguistiche basate sull’introspezione e dati prodotti in condizioni sperimentali.
Tipologia, annotazione e consultazione
Da un punto di vista statistico, un corpus è un campione estratto dalla popolazione di tutti i testi prodotti in una certa lingua, in un certo periodo, in un certo registro, ecc., sulla base del quale possiamo trarre conclusioni che si applicano alla popolazione campionata nel suo insieme. Per es., analizzando un corpus di articoli di giornale pubblicati in Italia negli anni Novanta del Novecento possiamo formulare generalizzazioni che, se il corpus è sufficientemente grande e vario, in genere sono valide per i testi giornalistici italiani del periodo scelto.
Un corpus di riferimento si propone come campione rappresentativo di una lingua in tutti i suoi aspetti: scritto e parlato, registri e varietà d’uso, ecc. Questo obiettivo però non è mai pienamente raggiungibile, per ragioni sia pratiche (la raccolta dei dati richiederebbe costi enormi) che teoriche (quanti e quali registri e varietà andrebbero campionati? in che proporzione? ecc.). Tuttavia, più un corpus è composto da fonti variegate, più esso sarà rappresentativo di una lingua in generale. In questo senso, si possono ragionevolmente definire di riferimento corpora come il CoLFIS o il CORIS (§ 3).
I corpora specialistici si focalizzano su testi di una tipologia specifica, per esempio testi dal web, un linguaggio tecnico, la lingua parlata o un dato periodo storico. Poiché la ricchezza di una lingua, in termini di lessico e costruzioni, è tale che anche corpora di milioni di parole possono risultare insufficienti allo studio di vari fenomeni (➔ statistiche linguistiche), e i corpora di riferimento tendono ad essere più costosi e difficili da raccogliere, e conseguentemente ad avere dimensioni minori, si fa spesso un uso ‘opportunistico’ di corpora specialistici di grandi dimensioni, che vengono utilizzati per studiare non solo il linguaggio specialistico che rappresentano, ma la lingua in genere. Per es., nel corpus di riferimento CoLFIS, di circa 3.800.000 parole, il termine energumeno compare solo 2 volte. Nel corpus La Repubblica, composto di soli testi giornalistici, ma quasi 100 volte più grande del CoLFIS, energumeno ricorre 271 volte. Chi fosse interessato all’uso di questo termine in italiano otterrebbe quindi molte più informazioni consultando il corpus La Repubblica, piuttosto che il (pur teoricamente più rappresentativo) corpus di riferimento CoLFIS.
È sempre più comune la pratica di annotare i corpora, rendendo esplicite varie informazioni in essi contenute in modo da permettere ricerche più sofisticate. Molti corpora contengono un apparato di metadati riguardanti i testi campionati (cioè informazioni utili per identificarli e caratterizzarli: autore, anno di pubblicazione, argomento, ecc.), mentre a un livello più strettamente linguistico le parole nel corpus sono spesso annotate almeno indicandone la parte del discorso (rendendo dunque possibile, ad es., cercare porta come nome separatamente da porta come verbo) e lemmatizzate (in modo da cercare portare e trovare anche tutte le forme flesse di questo verbo). Nei corpora di grandi dimensioni, l’annotazione linguistica viene tipicamente condotta con metodi automatici, che implicano un certo margine d’errore.
I corpora si consultano con strumenti informatici specializzati di diversa natura. Gli strumenti di consultazione standard permettono di condurre ricerche per sequenze di lettere, spesso arricchite da caratteri jolly (per es., ascolt* indica che si cercano tutte le forme di ascoltare). Se il corpus è annotato, lo strumento di consultazione permetterà di filtrare la ricerca attraverso tale annotazione (e dunque formulare richieste quali: «trova tutte le forme di bamboccione in tutti i testi precedenti al 2007»; oppure: «trova tutti i nomi immediatamente seguiti dal lemma verbale remare solo nei testi di argomento sportivo»).
Gli strumenti di consultazione rispondono di solito all’interrogazione con informazioni sulla frequenza di occorrenza della stringa cercata e con liste di concordanze, che mostrano la stringa cercata nei contesti in cui essa si trova all’interno del corpus. È sempre più comune inoltre che gli strumenti di consultazione producano varie analisi automatiche delle occorrenze delle stringhe cercate, estraendo ad esempio i collocati tipici di una parola, ovvero altre parole che tendono ad occorrere con la parola cercata in maniera statisticamente significativa.
Principali corpora dell’italiano
Fra i principali corpora dell’italiano, di riferimento o specialistici, finora disponibili vanno anzitutto ricordati, per ragioni storiche, i lavori pionieristici di padre Roberto Busa (che già negli anni Cinquanta del XX secolo usò il computer per indicizzare l’opera di San Tommaso), e il primo vero e proprio corpus di riferimento della lingua italiana, che portò alla pubblicazione del Lessico di frequenza della lingua italiana contemporanea (LIF = Bortolini, Tagliavini & Zampolli 1971). Il LIF, che campiona circa 500.000 parole (tratte da testi teatrali, periodici, romanzi, cinema e sussidiari, in parti uguali), fu utilizzato, tra l’altro, da Tullio De Mauro per determinare la lista di lemmi del suo Vocabolario di base della lingua italiana (1987).
Il Corpus e lessico di frequenza dell’italiano scritto (CoLFIS: Laudanna et al. 1995; http://www.istc.cnr.it/material/database/colfis/) è un corpus di riferimento di circa 3.800.000 parole. Si distingue per l’attenzione prestata ai criteri di campionamento, che rispecchiano la proporzione di tipologie testuali diverse (quotidiani, periodici, libri) riscontrata nelle letture degli italiani secondo l’ISTAT.
Il Corpus di italiano scritto (CORIS; Rossini Favretti 2000; http://corpora.dslo.unibo.it/coris_ita.html) è un corpus di riferimento di dimensioni molto maggiori (100 milioni di parole, per lo più giornali e libri, ma anche testi accademici, legali, amministrativi, e altro), che può venire liberamente consultato in rete su registrazione. Il CODIS è una versione del CORIS che viene costantemente aggiornata in modo da monitorare lo sviluppo della lingua italiana.
Anche se non si propone come corpus di riferimento, quello de La Repubblica (Baroni et al. 2004; http://sslmit.unibo.it/repubblica/), che raccoglie le annate del quotidiano in questione dal 1985 al 2000, si distingue per le grandi dimensioni (circa 325 milioni di parole) e per l’interfaccia d’interrogazione (liberamente accessibile previa registrazione) che permette ricerche avanzate che sfruttano, tra l’altro, metadati, parti del discorso e lemmi.
Il corpus di maggiori dimensioni attualmente disponibile per l’italiano è itWaC (Baroni et al. 2009; http://wacky.sslmit.unibo.it), un corpus di testi scaricati con metodi automatici dal web che contiene più di un miliardo e mezzo di parole. Il corpus può essere liberamente scaricato previa registrazione e gli utenti possono disporre di un servizio on-line a pagamento che offre un’interfaccia di consultazione molto avanzata. Tale interfaccia permette, tra l’altro, di estrarre i complementi oggetto tipici di un certo verbo, di confrontare gli aggettivi più caratteristici di un certo sostantivo rispetto a un altro, ecc. Il corpus itWaC riflette la recente tendenza a costruire corpora raccogliendo testi web con procedure automatiche, ed esistono strumenti che permettono all’utente di costruire un proprio corpus dal web usando procedure simili.
I corpora di lingua parlata consistono invece in trascrizioni di registrazioni (anche associate alle registrazioni medesime), poiché gli strumenti di consultazione e analisi dei corpora operano su testi scritti, e non direttamente sull’audio. Il corpus del Lessico di frequenza dell’italiano parlato (LIP = De Mauro et al. 1993), raccolto nei primi anni Novanta del Novecento, contiene circa 500.000 parole (corrispondenti a circa 58 ore di registrazione effettuate a Roma, Milano, Napoli e Firenze) e campiona in dimensioni comparabili diverse situazioni comunicative (conversazioni in casa, telefonate, lezioni, ecc.). Il corpus può venire consultato liberamente all’indirizzo http://languageserver.uni-graz.at/badip/: l’interfaccia permette ricerche per sequenze di lemmi o forme flesse con filtri per parte del discorso e metadati concernenti la trascrizione (per es.: «cerca tutte le pause», «cerca gli applausi», ecc.). Sul medesimo sito è anche disponibile la lista completa di frequenza d’occorrenza dei lemmi nel corpus.
Il corpus parlato del progetto Corpora e lessici di italiano parlato e scritto (CLIPS: http://www.clips.unina.it/), sviluppato tra il 1999 e il 2004, spicca per la ricchezza di annotazione (comprendente anche una vera e propria trascrizione fonetica di alcune sezioni) e per la varietà di campionamento per tipo di lingua (parlato dialogico raccolto sul campo, parlato radiotelevisivo, telefonico, letto) e aree geografiche (15 città); è scaricabile nella sua interezza, corredato di vari livelli di annotazione e dei file audio corrispondenti alle trascrizioni.
Il corpus italiano del progetto C-ORAL-ROM (Cresti & Moneglia 2005; http://lablita.dit.unifi.it/coralrom/) contiene circa 300.000 parole che campionano l’orale formale (lezioni, conferenze, ecc.) e informale (dialoghi e monologhi in contesti pubblici e privati) nonché vari canali comunicativi (di persona, per telefono, attraverso i media), e rappresenta soprattutto il parlato toscano. Il corpus è annotato per lemmi, parti del discorso e struttura prosodica, e corredato di metadati sui tipi di testo e varie caratteristiche dei parlanti. Lo stesso progetto ha prodotto inoltre corpora comparabili per altre lingue romanze (francese, portoghese e spagnolo): accessibili mediante un dvd allegato alla pubblicazione di riferimento, sono corredati da liste di frequenza per lemma e forma flessa, e da strumenti che permettono l’allineamento della trascrizione e delle registrazioni originali, l’analisi delle registrazioni e la ricerca sulla trascrizione con vari parametri.
Infine, il Corpus di italiano televisivo (CiT: Spina 2005; http://www.sspina.it/cit) è di dimensioni ridotte (attualmente, circa 60.000 parole) e ovviamente limitato al solo parlato televisivo, ma è riccamente annotato a livello strutturale, grammaticale e lessicale, e consultabile tramite un’interfaccia che permette ricerche sofisticate.
Tra i corpora per usi specialistici, vi sono i corpora diacronici, o che comunque rappresentano una fase passata della storia della lingua italiana. Il Corpus dell’italiano antico dell’Opera del Vocabolario Italiano (http://www.ovi.cnr.it/index.php?page=banchedati) comprende circa 22 milioni di parole da testi in volgare anteriori al 1375. Il corpus, lemmatizzato, può venire consultato on-line, ed è alla base del Tesoro della lingua italiana delle origini. Un sotto-insieme di testi del Duecento (circa 260.000 parole) forma il Corpus Taurinense (Barbera 2009: http://www.bmanuel.org/projects/ct-HOME.html), che è alla base della grammatica dell’italiano antico ItalAnt.
Un altro tipo di corpus specializzato importante per studi linguistici in vari ambiti raccoglie trascrizioni di interazioni con i bambini nel periodo dell’acquisizione linguistica (parlato prodotto dai bambini, e parlato a essi rivolto). È disponibile in questo settore la grande raccolta di corpora CHILDES (MacWhinney 20003: http://childes.psy.cmu.edu/), che contiene anche corpora che documentano lo sviluppo linguistico di bambini italiani. Di grande interesse per la didattica dell’italiano come lingua straniera è il corpus VALICO, o Varietà di apprendimento della lingua italiana: corpus online (http://www.bmanuel.org/projects/br-HOME.html), una raccolta di circa 570.000 parole da testi di apprendenti di italiano come seconda lingua.
Esiste anche un dizionario di frequenza della varietà di italiano parlata nella Svizzera italofona (LIPSI; Pandolfi 2009), basato su un corpus di circa 400.000 parole raccolto mediante registrazioni di parlato conversazionale e radiotelevisivo.
Esempi di uso
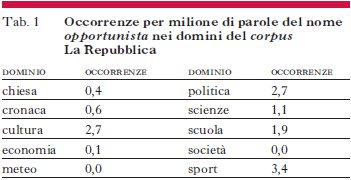
Un’analisi del nome opportunista nel corpus La Repubblica può esemplificare il tipo di lavoro che svolgono i lessicografi sui corpora. Un primo dato interessante riguarda la distribuzione della parola studiata nei vari domini rappresentati nel corpus. La tab. 1 riporta il numero di occorrenze del lemma nominale opportunista per milione di parole (l’annotazione permette di escludere casi in cui opportunista è un aggettivo, e di contare occorrenze del sostantivo sia al singolare che al plurale).
Dalla tab. 1 emerge che opportunista tende ad essere più comunemente usato negli articoli di politica, cultura e soprattutto sport. In (1), (2) e (3) sono riportati esempi di righe di concordanza, estratte a caso da testi, rispettivamente, di politica, cultura e sport.
(1) a. Denunciando la negligenza del presidente [...], il comitato dei Fronti Internazionalisti accusa Gorbaciov di essere un rinnegato e un opportunista
b. Nella gente apprezzo coraggio, franchezza e coerenza, detesto gli opportunisti pronti a tutto per la carriera
(2) a. Il suo biografo Alain Decaux afferma che in realtà Hugo non fu un socialista, ma un liberale riformista e talvolta un opportunista
b. Il nobel Carlo Rubbia non è certamente l’opportunista senza etica che l’americano Gary Taubes ha ritratto nel suo libro ‘Nobel dreams’
(3) a. La Fiorentina è stata messa sotto da un gol di quel grande opportunista che è Caimano Casiraghi, cinicamente punito in seguito dai toscani
b. Da opportunista vero alla fine del primo tempo, poi con un dribbling devastante, saltando due difensori e il portiere, come solo lui sa e può fare
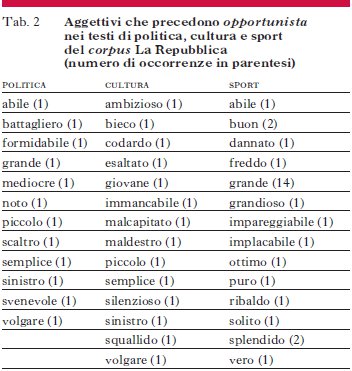
Da questi e altri esempi simili emerge che, se l’uso di opportunista in politica e cultura è molto simile e ha forte connotazione negativa (detesto gli opportunisti; opportunista senza etica), nello sport (o meglio, nel calcio) il termine ha un significato speciale (un attaccante in grado di sfruttare occasioni improbabili per segnare una rete), che si accompagna a una connotazione decisamente positiva (grande opportunista, opportunista vero). Una conferma quantitativa di quest’osservazione viene dalla tab. 2, dove sono riportati tutti gli aggettivi che precedono immediatamente il sostantivo opportunista nei sottoinsiemi di politica, cultura e sport, con la loro frequenza d’occorrenza in questa posizione.
La differenza negli aggettivi utilizzati con opportunista nello sport rispetto agli altri domini è molto chiara, così come la loro diversa valenza (positiva anziché negativa). Il lessicografo può quindi concludere che la voce del sostantivo opportunista deve comprendere il senso specifico della parola in campo sportivo, e in particolare che va sottolineata la connotazione diversa che il termine ha nello sport rispetto agli altri domini.
Studi
Barbera, Manuel (2009), Schema e storia del Corpus Taurinense. Linguistica dei corpora dell’italiano antico, Alessandria, Edizioni dell’Orso.
Baroni, Marco et al. (2004), Introducing the la Repubblica corpus. A large, annotated, TEI(XML)-compliant corpus of newspaper Italian. Proceedings of the 4th international conference on language resources and evaluation LREC (Lisbon, May 26-28 2004), edited by M.T. Lino et al., Paris, ELRA European Language Resources Association, pp. 1771-1774.
Baroni, Marco et al. (2009), The WaCky wide web. A collection of very large linguistically processed web-crawled corpora, «Language resources and evaluation» 43, 3, pp. 209-231.
Cresti, Emanuela & Moneglia, Massimo (a cura di) (2005), C-ORAL-ROM: Integrated reference corpora for spoken Romance languages, Amsterdam - Philadelphia, John Benjamins.
Laudanna, Alessandro et al. (1995), Un corpus dell’italiano scritto contemporaneo dalla parte del ricevente, in JADT 1995. III. Giornate internazionali di analisi statistica dei dati testuali, Consiglio nazionale delle ricerche (Roma 11-13 dicembre 1995), a cura di S. Bolasco et al., Roma, Cisu, 2 voll., vol. 1°, pp. 103-109.
LIF = Bortolini, Umberta, Tagliavini, Carlo & Zampolli, Antonio (1971), Lessico di frequenza della lingua italiana contemporanea, Milano, Garzanti.
LIP = De Mauro Tullio et al., Lessico di frequenza dell’italiano parlato, 1993, Milano, ETAS libri.
Lüdeling, Anke & Kytö, Merja (edited by) (2008-2009), Corpus linguistics. An international handbook, Berlin, Mouton de Gruyter, 2 voll.
MacWhinney, Brian (20003), The childes project. Tools for analyzing talk, Mahwah (N.J.), Lawrence Erlbaum, 2 voll. (1a ed. 1991).
Pandolfi, Elena M. (2009), LIPSI. Lessico di frequenza dell’italiano parlato nella Svizzera italiana, Bellinzona, Osservatorio linguistico della Svizzera italiana.
Rossini Favretti, Rema (2000), Progettazione e costruzione di un corpus di italiano scritto: CORIS/CODIS, in Ead. (a cura di), Linguistica e informatica. Corpora, multimedialità e percorsi di apprendimento, Roma, Bulzoni, pp. 39-56.
Spina Stefania (2005), Il Corpus di Italiano Televisivo (CiT): struttura e annotazione, in Tradizione e innovazione. Il parlato. Teoria, corpora, linguistica dei corpora. Atti del VI convegno della Società Internazionale di Linguistica e Filologia Italiana (Gerhad-Mercator Universität, Duisburg, 28 giugno - 2 luglio 2000), a cura di E. Burr, Firenze, Cesati, pp. 413-426.