
database
database
database struttura complessa di organizzazione di dati, che permette l’inserimento di nuovi dati o la rimozione di vecchi, nonché la modifica dei dati stessi, il loro aggiornamento e la loro elaborazione. L’unità informativa elementare del database è il record, inteso come stringa organizzata in campi per consentire l’archiviazione di un gran numero di informazioni anche di diverso tipo. Il record è, infatti, un insieme costituito da un numero finito di elementi, detti campi del record, ciascuno dei quali viene identificato da una stringa alfanumerica. L’agenda telefonica è un semplice esempio di database:

«Numero d’ordine», «cognome», «nome», «indirizzo» ecc. sono gli identificativi di campi che specificano le colonne della tabella, mentre il record è l’insieme degli elementi appartenenti a ciascuna riga; nell’esempio il secondo record contiene tutte le informazioni relative a Luigi Verdi. Una tabella visualizza contemporaneamente più record; a differenza di un’altra struttura, detta maschera del database che fornisce un solo record alla volta:
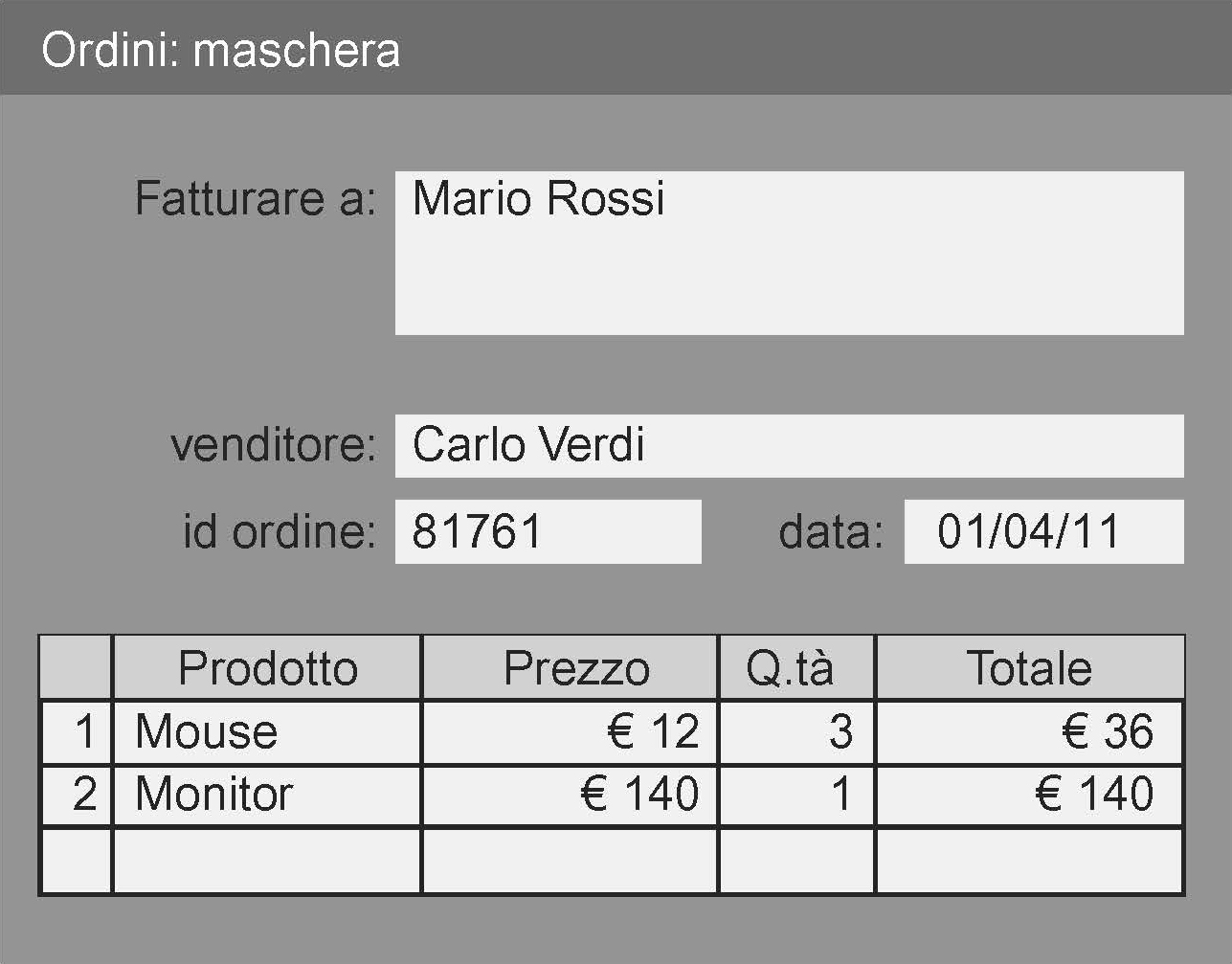
La maschera, oltre a dati alfanumerici, può contenere file multimediali o comandi di controllo come l’attivazione della stampa, l’avanzamento al record successivo ecc. La possibilità di ricercare, creare, aggiungere e modificare i campi record si realizza attraverso una interrogazione del database detta query. Essa consiste nella selezione di quei record del database che sono individuati in base ai criteri stabiliti, cioè a particolari valori dei campi record. Una query viene effettuata normalmente utilizzando un apposito linguaggio di programmazione di alto livello, oppure particolari funzioni e procedure previste all’interno dell’ambiente di sviluppo del database stesso. I campi record estratti devono verificare una condizione: questa non è altro che una proposizione logica il cui valore può essere «vero» o «falso». L’istanza di selezione dei dati desiderati pertanto sarà una formula ben formata che potrà contenere le operazioni dell’algebra di Boole (and, or, not) e le relazioni di uguaglianza e ordinamento naturale (<, >, =, ≤, ≥).
Il risultato di una o più query può essere alla base della creazione di nuove porzioni di database il cui contenuto può essere destinato a elaborazioni successive o alla visualizzazione del risultato finale della selezione voluta. Si definisce report l’output generato da un particolare raggruppamento dei dati prelevati tramite una o più query, solitamente usato per la visualizzazione o la stampa finale.
Un database è generalmente organizzato secondo un preciso modello logico (detto schema o metadati), che definisce la struttura con cui i dati sono memorizzati e fra loro collegati e le regole per la loro manipolazione. Nel corso degli anni sono stati sviluppati diversi modelli: gerarchico, reticolare, relazionale (oggi prevalente nei sistemi commerciali), a oggetti. Quest'ultimo rappresenta una evoluzione del paradigma relazionale che estende al database i concetti della programmazione a oggetti.
La necessità di strutturare il database con un gran numero di campi e di organizzare i dati in maniera complessa si traduce nella creazione di più tabelle, connesse tra loro tramite relazioni rappresentabili attraverso un particolare grafo. Quando almeno un campo record di una tabella è connesso attraverso una qualsiasi relazione a un campo record di un'altra tabella, il database prende il nome di database relazionale. La struttura di un database relazionale permette di ricercare, collegare ed elaborare efficientemente le informazioni memorizzate nelle varie tabelle correlate: ciò viene realizzato attraverso la definizione di particolari campi dei record, detti chiavi, che identificano univocamente ciascun record memorizzato del database. Si distinguono due tipi di chiavi, rispettivamente dette chiavi primarie e chiavi secondarie: per quelle primarie, è vietata la duplicazione della stessa chiave per due o più record differenti, mentre per le seconde è permessa la duplicazione delle chiavi. Le chiavi secondarie sono utilizzate per raffinare la ricerca in caso di record dotati di uguali valori in alcuni campi. I codici numerici identificativi univoci, o indici, corrispondenti alle chiavi primarie rivestono un'importanza notevole nella gestione dei database relazionali, che proprio per questo prendono il nome di database indicizzati. L’indicizzazione delle chiavi primarie è una condizione necessaria per l’integrità referenziale: proprietà particolare del database, consistente in un insieme di regole tese a validare le relazioni tra le tabelle e a evitare che i dati interessati vengano modificati o cancellati in maniera accidentale. L'integrità referenziale è assicurata quando si verificano le seguenti condizioni: 1) le tabelle devono appartenere allo stesso database e devono essere dotate di una chiave primaria univoca; 2) i campi correlati tra le varie tabelle devono essere omogenei nella dimensione e nel tipo di dato.
Le relazioni fra tabelle possono essere classificate per analogia con le relazioni tra gli elementi di un insieme secondo i tipi: uno-uno, uno-molti, molti-molti. Tali modalità vengono applicate a seconda delle esigenze di indirizzamento e di collegamento tra i dati e le tabelle; si usano pertanto le chiavi primarie per ottenere i codici univoci che garantiscono il collegamento diretto tra le varie tabelle. Per esempio, un database che contenga gli ordini di acquisto di alcuni prodotti, può essere formato dalle tabelle in figura, unite tra loro da relazioni di tipo molti-molti: la tabella «ordini», la tabella «dettaglio» e la tabella «prodotti»:
Come emerge dal grafo in figura, un ordine può contenere più prodotti, e ogni prodotto può essere contenuto in più ordini, come previsto dalla relazione molti-molti.
Una volta realizzato il database, è possibile mettere a disposizione i dati su una rete di computer, tipicamente una rete aziendale o Internet, affinché essi possano essere inseriti, analizzati e quindi elaborati da postazioni remote rispetto alla loro collocazione fisica. Utilizzando apposite maschere contenenti query predefinite, gli utenti possono così accedere ai dati anche a notevole distanza dal computer che li contiene fisicamente. Il controllo dell’integrità referenziale e una particolare gestione delle priorità di lavoro e dei privilegi per l’effettuazione di particolari operazioni (una per tutte, la cancellazione dei dati) evitano i possibili conflitti derivanti dall’accesso al database da parte di più utenti contemporaneamente.