
fonetica
fonetica
Fonetica e fonologia
Definizione
La fonetica linguistica è lo studio dei suoni (o foni; ➔ fonetica articolatoria, nozioni e termini di) prodotti dai parlanti nell’atto di pronunciare una lingua. Ciò non esaurisce la totalità dei suoni che l’apparato fonatorio umano può produrre (si pensi ai vari suoni o richiami di cui siamo capaci: imitazioni di voci animali, simulazione del russare, soffiare, fischiare, ecc.), ma, per quanto varie siano le nostre possibilità fonatorie, soltanto una parte dei suoni si presta a essere sfruttata nel linguaggio. I presupposti affinché ciò avvenga sono la relativa facilità articolatoria e la salienza percettiva; i foni che maggiormente rispondono a queste prerogative sono quelli che si incontrano più spesso nelle lingue naturali.
Ogni lingua possiede suoni vocalici (➔ vocali), mentre tra le ➔ consonanti più diffuse si trovano le occlusive sorde [p t k], le fricative [f s] e le nasali [m n]. Le fricative e le nasali sono dotate di intrinseca udibilità, tant’è vero che possono essere articolate in maniera prolungata fintantoché il fiato lo consente; le occlusive sorde sono invece eventi momentanei e di per sé scarsamente udibili. Tuttavia la pronuncia di una ➔ sillaba costituita da un’occlusiva sorda e da una vocale (ad es., [pa]) è un evento complesso, cui i due suoni, consonantico e vocalico, contribuiscono in maniera congiunta. Ciò che si crea dal punto di vista acustico – e ciò dunque che noi udiamo – è un evento coarticolatorio, caratterizzato da specifiche proprietà transizionali. La transizione da una consonante a una vocale, in ragione del modo di articolazione della prima e del luogo di articolazione di entrambe, è una parte costitutiva dell’evento acustico-uditivo. In altri termini: la parte iniziale di una [a] è diversa a seconda dell’occlusiva sorda che la precede. Questo ragionamento va esteso a ogni tipo di consonante, non riguarda soltanto le occlusive: nell’udire l’inizio di una vocale noi udiamo, contemporaneamente, il tipo di articolazione consonantica che la precede. Ciò spiega la salienza uditivo-percettiva delle occlusive sorde, e dunque la loro diffusione nelle lingue, data anche l’estrema facilità di realizzazione.
Coarticolazione
Da quanto detto emerge un’importante caratteristica dei foni linguistici. Una qualsiasi catena fonica, appartenente a un qualsivoglia atto di parola in una lingua data, non va intesa come mera sequenza lineare di eventi articolatori, analogamente a ciò che accade nella scrittura in stampatello (in cui ogni carattere segue ordinatamente il precedente, almeno nella maggioranza dei sistemi di trascrizione); le restrizioni coarticolatorie obbligano il parlante a produrre eventi che manifestano informazioni miste. Se infatti isoliamo una [a] entro una catena fonica, rischiamo di non riconoscerla; ma se la ricollochiamo nel contesto in cui è stata prodotta, non abbiamo dubbi circa la sua identità (posto che ci si trovi in situazioni normali di pronuncia; in caso di ipoarticolazione, la riconoscibilità di un suono può essere difficile perfino in contesto). Insomma, non si percepisce un suono alla volta, ma una catena di complessi eventi coarticolatori, da cui si ricevono informazioni che in parte confermano l’identità dei suoni appena uditi e in parte anticipano l’identità dei suoni che stiamo per udire.
Ciò comporta due conseguenze fondamentali:
(a) la dipendenza di ogni singolo evento articolatorio dal contesto fonico. La nostra capacità percettiva si avvale delle circostanze coarticolatorie e le sfrutta a proprio vantaggio. Il fatto che una [a] sia alterata dal contesto in cui viene prodotta non ostacola la comprensione, anzi la agevola, perché la nostra capacità percettiva si è sintonizzata proprio su siffatte compenetrazioni fra foni adiacenti;
(b) l’elevata velocità di trasmissione, poiché percepiamo contemporaneamente eventi acustico-articolatori passati e futuri, oltre che presenti. Coloro che parlano molto in fretta possono arrivare a produrre anche una decina di sillabe al secondo – molto più dei caratteri che potrebbe battere sulla tastiera il più veloce dattilografo – senza creare alcun disagio nell’ascoltatore (a patto che sappiano conservare una pronuncia accurata anche parlando veloci).
Queste proprietà risultano ancora più significative quando si rifletta sul fatto che l’apparato fonatorio umano non è nato in quanto organo specializzato. Il linguaggio stesso, a livello generale, non era, per così dire, previsto nella nostra architettura neuronale. L’evoluzione ha saputo quindi dotare gli esseri viventi di capacità vocali che sfruttano parassitariamente organi preesistenti. Nel caso dei mammiferi, è stato utilizzato l’apparato preposto alla respirazione e all’ingestione dei cibi, oltre che l’apparato uditivo. A partire da ciò, gli esseri umani hanno poi sviluppato specifiche capacità linguistiche, che hanno prodotto nel tempo la specializzazione di alcune aree cerebrali inizialmente adibite ad altra funzione. Un autentico prodigio evolutivo.
Sottosettori della fonetica
La fonetica, come si evince da quanto detto, comprende vari sottosettori. Si distinguono la fonetica articolatoria, che studia il modo in cui i suoni vengono prodotti dall’apparato fonatorio (➔ fonetica articolatoria, nozioni e termini di); la fonetica fisiologica, che studia i riflessi a livello muscolare e neuronale di detti eventi; la fonetica acustica (➔ fonetica acustica, nozioni e termini di), che studia la struttura fisica del suono generato; la fonetica uditiva, che ne studia la traccia lasciata nell’apparato uditivo (anche qui con opportuni riflessi a livello neuronale); e infine la fonetica percettiva, che studia la risposta del nostro sistema di comprensione del linguaggio a tali eventi articolatori-acustici-uditivi.
Non si confonda la percezione con la mera risposta uditiva. Uno stesso evento fonetico può essere percepito in modo diverso, a seconda:
(a) del contesto in cui è inserito (il che condiziona la nostra reazione, anche per effetto delle attese che si vengono a creare in base alla ridondanza semantica del testo ascoltato fino a quel momento);
(b) della lingua.
Quest’ultimo punto – il condizionamento del background linguistico del parlante – porta a considerare la differenza fra fonetica e ➔ fonologia.
Fonetica e fonologia
Mentre la prima riguarda lo studio oggettivo degli eventi linguistici, in rapporto alla loro struttura fisica e alla risposta uditiva da essi innescata, la seconda concerne il modo specifico in cui si organizza il sistema dei foni appartenenti a una data lingua. La fonetica percettiva costituisce un irrinunciabile ponte fra queste due discipline. Per fare un esempio intuitivo, si consideri il modo in cui un parlante nativo di lingua inglese pronuncia la parola two «due» ([thʊ], con riduzione vocalica in posizione deaccentata; ➔ indebolimento): all’orecchio di un italiano completamente ignaro di inglese questa sillaba può essere decodificata come [ʧu] (in grafia italiana: ‹ciu›), mentre per il parlante inglese il suono iniziale è l’allofono di /t/ a inizio di parola (➔ allofoni).
La diversa risposta percettiva dipende dal fatto che ogni parlante riferisce gli eventi acustici che investono l’apparato uditivo alle proprie abitudini linguistiche, ossia a una competenza fonologica esercitata sulla lingua nativa. Attraverso l’esposizione ad altri sistemi linguistici, è possibile relativizzare tale risposta, allenando il sistema percettivo a reagire in maniera differenziata a seconda della lingua che viene parlata. Ma la preminenza del sistema nativo resta sempre osservabile, in misura maggiore o minore.
Per comprendere che cosa si intende per fonologia di una lingua si può considerare il seguente esempio. Si confronti una lingua con sistema vocalico ridotto a tre sole unità ([i a u]) con una che ne possieda molte di più ([i y e ø ɛ œ æ ə a ɑ ɔ ʌ o ɤ u]). Risulterà subito evidente che le vocali della prima lingua possono tollerare livelli anche estremi di ipoarticolazione o di condizionamento da parte del contesto, mentre quelle della seconda lingua richiederanno una precisione articolatoria molto maggiore. In altri termini, lo spazio articolatorio delle vocali appartenenti al primo sistema è maggiore di quello a disposizione delle seconde, e questo dato è incorporato nella competenza linguistica dei parlanti. I parlanti delle due lingue daranno dunque risposte diverse ai medesimi eventi acustici, rapportandoli a un diverso sistema.
Su questo si basa la differenza tra fono e fonema.
Fono e fonema
Un fono corrisponde alla classe delle manifestazioni, fisicamente descrivibili, di un gesto articolatorio dell’apparato fonatorio umano; un fonema è la traduzione di tali eventi fisici in un’entità astratta, appartenente a uno specifico sistema fonologico. È importante cogliere qui la differenza tra livello concreto e livello astratto. Per il parlante inglese, esistono i foni [t] e [th], ma entrambi sono allofoni del fonema /t/ (si noti la convenzione di notazione: parentesi quadre per foni, barre oblique per fonemi; ➔ alfabeto fonetico). In inglese esiste anche il fonema /ʧ/, ma nessun parlante nativo lo confonderà (in condizioni normali di pronuncia e di ascolto) con l’allofono [th] del fonema /t/; il fatto che ciò possa avvenire per un parlante italiano ignaro della struttura fonetico-fonologica dell’inglese dipende, evidentemente, dal fatto che lo spazio acustico di [th] può risultare non di rado più simile a quello di [ʧ] che a quello di [t] (o, quanto meno, dal fatto che il parlante italiano non si aspetta di udire [th] come realizzazione di /t/).
Ogni lingua ha dunque la propria fonologia: i fatti fonetici vanno sempre interpretati in relazione a essa. Ciò non vieta i confronti tipologici fra lingue diverse, che sono anzi utili per meglio inquadrare le singole situazioni, ma comporta comunque la necessità di relativizzare le osservazioni rispetto allo specifico sistema entro cui gli eventi si manifestano.
Sottosettori della fonologia
Prima di affrontare la descrizione del sistema fonetico-fonologico dell’italiano, occorre precisare che la fonologia di una lingua si compone, come già si è visto per la fonetica, di alcuni sottosettori. Importante è soprattutto la distinzione fra comparto segmentale e comparto soprasegmentale o prosodico (➔ soprasegmentali, tratti; ➔ prosodia). Il primo è riservato allo studio dei fonemi vocalici e consonantici; il secondo riguarda le unità dette, appunto, prosodiche, quali: quantità (vocalica o consonantica; ➔ quantità fonologica), ➔ accento, ➔ intonazione, ➔ sillaba. Assai importante è anche il settore della cosiddetta fonotassi (➔ fonetica sintattica), che concerne i fatti relativi alla sequenza degli eventi fonematici, ossia:
(a) le restrizioni di combinazione dei suoni;
(b) le alterazioni condizionate dal contesto (per es., in italiano /np/ si trasforma automaticamente in /mp/ per assimilazione anche al confine tra due parole, come in in piedi).
Beninteso, i fatti fonotattici, così come la distinzione fra dominio segmentale e prosodico, non riguardano solo la fonologia; nella misura in cui hanno dei corrispettivi a livello di realizzazione fisica, essi sono di pertinenza anche della fonetica. Esiste quindi la fonetica prosodica (che studia la concreta realizzazione degli eventi prosodici), così come la fonetica fonotattica (che studia il riflesso fisico delle sequenze di foni).
Italiano standard e varietà locali
Il primo problema che si incontra, a proposito della fonetica dell’italiano, riguarda la scelta della varietà da descrivere. Ci si riferisce di solito alla nozione di ➔ italiano standard, ma occorre definirla con precisione. Non si tratta di mera astrazione, visto che è oggetto di insegnamento nelle scuole di dizione e costituisce il fondamento dei manuali di pronuncia (cfr. DOP 1969); né si deve ritenere che esista un luogo geografico preciso (una città o una zona) in cui tale varietà venga nativamente appresa dai parlanti. Essa si basa sulla lingua parlata a Firenze, di cui è possibile percorrere con esattezza l’evoluzione a partire dal Duecento; tuttavia, anche a Firenze esiste un complesso intreccio di comportamenti sociolinguistici. Le varietà maggiormente impregnate di tratti locali si caratterizzano come marcatamente dialettali; solo quella più elevata, e più conservativa, la cui padronanza non è garantita neppure per molti fiorentini colti, può fregiarsi del titolo di varietà standard. Come tale, essa è apprendibile anche da non fiorentini, salvo restando il diverso sforzo necessario per impadronirsene. Per un fiorentino colto si tratterà soltanto di disattivare alcuni processi fonologici di stampo prettamente locale; per un non fiorentino si tratterà invece di attivare una serie di processi fonologici, nonché comportamenti lessicalmente idiosincratici (si pensi al timbro delle e e delle o). Importa qui tuttavia sottolineare che perfino per un nativo di Firenze il possesso della varietà standard deve essere oggetto di un conscio sforzo di appropriazione; non si tratterà mai di passiva e automatica esposizione all’ambiente.
La vicenda attraverso cui il fiorentino è assurto a varietà di riferimento, nel contesto delle varietà italiane, è ben nota, benché non agevolmente riassumibile. Ci si dovrà riferire ai manuali di storia della lingua italiana (ad es., Migliorini 19613; Rohlfs 1966-1969; Marazzini 1994; Maiden 1995). Soprattutto a partire dall’unità d’Italia, la varietà fiorentina colta (il cosiddetto standard, appunto), che per secoli aveva costituito il punto di riferimento per la letteratura in lingua e le scritture di tipo giuridico-amministrativo (sia pure con illustri eccezioni, come nella Repubblica Veneta), fu assunta come base per l’insegnamento scolastico. In questa diffusione svolsero un ruolo importante istituzioni quali l’esercito, con la mescolanza forzata di individui provenienti da regioni diverse, e l’amministrazione dello Stato, coi trasferimenti dei propri funzionari; ma non c’è dubbio che l’accelerazione finale si sia avuta con la capillare penetrazione dei mezzi di comunicazione di massa. Non si deve peraltro credere che l’azione di questi ultimi abbia favorito l’affermazione del modello standard; ciò che essi hanno semmai prodotto, specie da quando gli speaker radiofonici e televisivi hanno cessato di essere rigorosamente addestrati dal punto di vista ortofonico, è la centrifugazione dei diversi modelli linguistici, che ha avviato un processo di omogeneizzazione, tuttora in corso, che, pur non avendo levigato del tutto le diversità, ha comunque contribuito a stabilizzare un certo numero di varietà regionali.
Da questo punto di vista, si può ormai asserire che la situazione dell’italiano sia affine a quella delle principali lingue di cultura, le quali:
(a) sono usate, come lingua d’uso, dalla (quasi) totalità degli appartenenti alla comunità linguistica;
(b) si caratterizzano per la frammentazione in macrovarietà a diffusione regionale (distinte, peraltro, dai veri e propri dialetti, nella misura in cui questi sopravvivano);
(c) ammettono l’esistenza di una varietà standard, la cui effettiva padronanza richiede un certo sforzo di appropriazione, non essendo varietà nativa per alcun parlante.
Le differenti varietà di pronuncia dell’italiano si caratterizzano, l’una rispetto all’altra, per diverse connotazioni di carattere culturale e sociologico (Bruni 1992): per es., il prestigio (o il fastidio) attribuito alle varietà lombarde (il milanese soprattutto) dipende dalla loro contiguità con ambienti influenti dal punto di vista dell’economia e della finanza.
È opportuno però sottolineare che le reazioni dei singoli alle pronunce altrui sono variabili e dipendono spesso da ragioni attinenti al vissuto di ciascuno. Merita accennarvi unicamente per rimarcare che la sensibilità dei parlanti alle differenze di pronuncia è vivissima e può suscitare sentimenti discordanti, di simpatia o antipatia; si tratta di un aspetto cui nessuno può dire di essere totalmente indifferente.
Tratti fonetici dell’italiano
Vocali
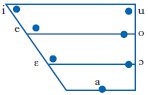
In sillaba accentata, l’italiano standard presenta i 7 fonemi vocalici riportati nella fig. 1, che riproduce il cosiddetto trapezio vocalico, che allude allo spazio articolatorio nel condotto orale. La collocazione in figura riflette i valori acustici medi di tali foni (per le caratteristiche spettrografiche ➔ nozioni e termini di fonetica acustica).
(1) pizzo ~ p[ɛ]zzo ~ pazzo ~ p[o]zzo ~ puzzo
b[o]tte (recipiente) ~ b[ɔ]tte (colpi violenti)
v[e]nti (numero) ~ v[ɛ]nti (evento atmosferico)
In posizione atona ricorrono solo i 5 fonemi [i e a o u]. Occorre precisare che l’effettivo livello di altezza delle vocali medie atone può variare in ragione del contesto, a seconda delle consonanti e vocali immediatamente precedenti e seguenti. Ciò non toglie che le vocali medio-basse [ɛ ɔ] non compaiano in posizione atona. Pertanto, in parole che siano connesse – per ➔ flessione o ➔ derivazione – con altre che contengono le suddette vocali medio-basse avviene, nel passaggio da posizione tonica ad atona, un processo di innalzamento:
(2) l[ɛ]gge (voce del verbo) ~ l[e]gge (nome),
ma l[e]ggiamo e l[e]ggina con neutralizzazione in [e]
f[ɔ]ro (come parte di una città) ~ f[o]ro (voce del verbo),
ma f[o]rense e f[o]rato con neutralizzazione in [o]
L’innalzamento, peraltro, non si applica nei primi membri di un composto quando la vocale interessata porti l’accento secondario:
(3) app[ɛ]ndiabiti (cfr. app[ɛ]ndo ~ app[e]ndiamo)
t[ɔ]ssicodipendente (cfr. t[ɔ]ssico ~ int[o]ssicare)
a meno che, beninteso, non si sia innescata una qualche forma di opacizzazione semantica nel rapporto fra il composto e le sue parti componenti. Ciò giustifica certe oscillazioni timbriche in parole come p[ɔ]rtafoglio / p[o]rtafoglio e c[ɔ]priletto / c[o]priletto (un copriletto designa infatti uno specifico tipo di oggetto, non una qualunque cosa posta sopra un letto).
Un caso analogo è costituito dai composti cosiddetti neoclassici (➔ elementi formativi), il cui primo elemento è un morfema di derivazione greca o latina, che non esiste in quanto parola autonoma. Anche in questi composti l’innalzamento è variabile, perché la trasparenza semantica non è altrettanto evidente per tutti i parlanti:
(4) gl[ɔ]ttologia / gl[o]ttologia
l[ɔ]gopedia / l[o]gopedia
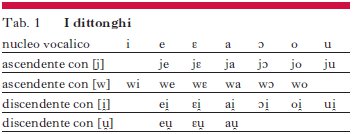
L’italiano presenta un vasto campionario di dittonghi (➔ dittongo) ascendenti e discendenti (Muljačić 1972; Mioni 2001). Le caselle vuote nella tab. 1 hanno per lo più una spiegazione di tipo fonetico, in quanto i dittonghi corrispondenti sarebbero difficili da articolare o percepire (cfr. */ji/, */wu/, */ii̯/, */uu̯/).

La trascrizione segue una tradizione consolidata: nei dittonghi ascendenti compaiono i legamenti [j w] (➔ semivocali), in quelli discendenti i foni semivocalici [i̯ u̯]. Lo scarto, in termini fonetici, è peraltro minimo; del resto, [j w] manifestano spesso comportamenti decisamente vocalici, come si noterà sparsamente nei paragrafi seguenti. L’unica ragione per mantenere la differenza di trascrizione discende da certe tendenze distribuzionali. Non si ritiene tuttavia necessario (sempre in ossequio alla tradizione) ribadire tale differenza in termini di inventario fonematico, dato che si tratta comunque di allofoni posizionali dei medesimi fonemi; pertanto, nella tabella dei fonemi consonantici (cfr. tab. 2) verranno indicati solo i legamenti /j w/. Qui sotto si riportano esempi dei diversi dittonghi italiani, in sillaba aperta e (ove possibile) chiusa:
(5) soff[je]tto, p[jɛ]no, ch[ja]ve, ch[jɔ]do, f[jo]re, b[jo]ndo,
p[ju]ma, g[wi]da, q[we]llo, q[we]rimonia, q[wɛ]rcia,
q[wɛ]rulo, g[wa]do, q[wɔ]ta, acq[wo]so,
pot[ei̯], s[ɛi̯], b[ai̯]ta, p[ɔi̯], v[oi̯], l[ui̯], pl[eu̯]rite, n[ɛu̯]tro, [au̯]to
I trittonghi (➔ trittongo) nascono di norma da sequenze di due legamenti ascendenti, spesso separati da un confine di morfema: ad es., contin[ɥja]mo (dove il legamento labio-palatale [ɥ] si crea da quello labio-velare [w] per ➔ assimilazione con [j]: Calamai & Bertinetto 2006). In pronuncia veloce, i trittonghi possono comunque originarsi anche dalla riduzione di uno iato (p[wɔi̯]). I trittonghi all’interno di radice sono alquanto rari (cfr. acq[ɥje]scenza), anche se possono talvolta crearsi in pronuncia veloce in parole che normalmente non li presentano (cfr. quiete [kwiˈɛte] con la pronuncia veloce [ˈkɥjɛte], peraltro normale per molti parlanti).
Consonanti
La tab. 2 presenta l’inventario dei fonemi consonantici dell’italiano: fonemi, si badi, non foni. Per es., la vibrante compare con un unico simbolo, corrispondente all’allofono non marcato – con punto di articolazione alveolare – anche se l’effettiva modalità di realizzazione di questo fonema dipende da fattori idiosincratici e in parte areali. Tra le sue diverse manifestazioni troviamo le realizzazioni uvulari (vibrante, approssimante o fricativa) e labiodentale (approssimante). Si noti che nella sua realizzazione più tipica il fono /r/ scempio dell’italiano comporta generalmente, in posizione intervocalica, un solo contatto tra lingua e alveolo; ma dopo pausa o prima di altra consonante (oltre che in geminazione), tale fono presenta un minimo di due contatti, e può dunque fregiarsi del titolo di polivibrante.
Secondo ben note convenzioni, le righe della tabella si riferiscono ai diversi modi di articolazione attivati in italiano, mentre le colonne si riferiscono ai luoghi (o punti) di articolazione; o, più esattamente, ai «punti di (maggior) costrizione» o «luoghi diaframmatici» – con termine di Walter Belardi (1959) –, visto che entra spesso in gioco più di un punto. Occorre peraltro precisare che nella tabella la variabile di luogo diaframmatico è indicata in funzione fonetica, piuttosto che fonologica, dato che in italiano solo quattro luoghi svolgono effettiva funzione distintiva, ossia creano opposizioni pertinenti. Le seguenti coppie non creano, infatti, alcuna opposizione pertinente: bilabiale ~ labiodentale, dentale ~ alveolare, postalveolare ~ palatale.
Qui di seguito si riporta un elenco di coppie minime, che illustrano le principali opposizioni distintive dell’italiano (quanto alle approssimanti, cfr. supra i dittonghi; per le caratteristiche spettrografiche delle consonanti, ➔ nozioni e termini di fonetica acustica):
(6) para [ˈpara] ~ bara [ˈbara];
tino [ˈtino] ~ Dino [ˈdino];
cala [ˈkala] ~ gala [ˈgala];
razza [ˈratːsa] ~ razza [ˈradːza];
cielo [ˈʧɛlo] ~ gelo [ˈʤɛlo] ;
lama [ˈlama] ~ lana [ˈlana] ~ lagna [ˈlaɲːa];
para [ˈpara] ~ pala [ˈpala] ~ paglia [ˈpaʎːa];
scafo [ˈskafo] ~ scavo [ˈskavo];
uso (il fatto di usare) [ˈuso] ~ uso (abituato, avvezzo) [ˈuzo] ~ uscio [ˈuʃːo]
Il fonema /z/ ha una distribuzione limitata. Si oppone a /s/ solo intervocalicamente, per lo più all’interno di radice come sopra illustrato (sia pure davanti a flessione), ma anche su confine morfologico davanti a radice (cfr. di[z]illusione). Ne consegue che /z/ non si trova mai a inizio o fine di parola (➔ parola italiana, struttura della). Quanto a /ʒ/, esso appare tra parentesi in tab. 2 data la sua marginalissima distribuzione, visto che compare soltanto in ➔ prestiti: abat-jour [abaˈʒur], garage [gaˈraʒ]. Si tratta insomma di un quasi-fonema, per riprendere un termine usato da taluni per casi analoghi di altre lingue.
A proposito dello statuto fonologico delle geminate si dovrà osservare che, dal punto di vista fonetico, esse si distinguono nettamente dai corrispettivi foni scempi per via della maggior durata. Tale fatto non si può riassumere in semplici indici numerici e neppure in un mero rapporto che esprima la proporzione fra scempia e geminata. Precise indicazioni (assolute o relative) sono rese impossibili dalla variabilità dei dati, che discende dalla diversa velocità di eloquio e dal tipo di fono (nonché dalle diverse varietà di italiano; ma le variazioni regionali saranno trattate nel § 6). Dal punto di vista fonologico, sullo statuto delle geminate italiane si è creato un dibattito tra chi le interpreta come unità «mono-» e chi le vede come «bi-fonematiche» (cfr. Muljačić 1972; Loporcaro 1996). Dal punto di vista articolatorio, e dunque fonetico, le geminate vanno considerate come singole unità, in contrasto quindi con i casi di più o meno evidente riarticolazione. Fonologicamente, tuttavia, le geminate dell’italiano vanno trattate come una sequenza di due unità identiche, distribuite su due sillabe adiacenti. Il confine sillabico spezza quindi la loro unitarietà fonetica, anche se non è possibile indicare il punto esatto della transizione fra le due sillabe.
La geminazione distintiva dell’italiano riguarda i seguenti 15 fonemi consonantici: [p b t d k g m n r f v s l ʦ ʣ]:
(7) fa[tː]o ~ fa[t]o, ca[lː]o ~ ca[l]o, caccio [ˈkatːʃo] ~ cacio [ˈkaʧo]
Le geminate ricorrono tra vocali (come negli es. visti) o prima di un legamento:
(8) occhiali [okˈːjali], assieme [asˈːjɛme], commuovere [komˈːwɔvere], annientare [anːjenˈtare], arruolare [arːwoˈlare]
Inoltre, un sottoinsieme di ostruenti geminate – le occlusive con l’aggiunta di [f] – può precedere una liquida (laterale o vibrante):
(9) a[kː]ludere, a[fː]litto, a[tː]rezzo, o[fː]ro, a[gː]lomerato, a[bː]reviare, ra[dː]rizzare
Restano esclusi dalla correlazione di geminazione /z j w/, sempre brevi nello standard, ma anche /ʎ ɲ ʃ ʦ ʣ/, che invece in posizione intervocalica (dunque, non dopo consonante o pausa) hanno durata simile a quella delle geminate:
(10) ragno [ˈraɲːo], aglio [ˈaʎːo], ascia [ˈaʃːa], organizzazione [organidːzatˈːsjone]
A dire il vero, la durata di [ʎ ɲ] (nonché l’effetto accorciante sulla vocale tonica precedente, in caso di posizione intonativamente prominente) si discosta dal comportamento delle autentiche geminate (Endo & Bertinetto 1999, Celata & Kaeppeli 2003). Comunque sia, con questi ultimi fonemi non è possibile creare coppie semi-minime, analoghe a quelle riportate, in cui si oppongano una scempia e una geminata; essi sono dunque tradizionalmente denominati consonanti rafforzate o geminate intrinseche. Dal punto di vista della scansione sillabica, le rafforzate in posizione intervocalica si comportano eterosillabicamente come le geminate, ossia si dividono fra due sillabe adiacenti. Tuttavia, esse differiscono dalle vere e proprie geminate in quanto (prestiti a parte) non possono precedere alcuna altra consonante, e inoltre possono ricorrere a inizio di parola (cfr. gnomo, gli, zio), sia pure con frequenza molto difforme fra di loro. Le uniche parole che nello standard iniziano con una geminata (purché pronunciate in contesto intervocalico) sono Dio (cfr. di [dː]io) e che [kːɛ] (interrogativo).
Fonosintassi
Tra i processi allofonici di tipo assimilativo, va citato il comportamento di /s/ preconsonantico (che secondo le convenzioni andrebbe indicato con la maiuscola /S/, a segnalare che si tratta di un arcifonema), che subisce assimilazione di sonorità da parte della consonante seguente: cfr. [z]velto o [z]memorato ~ [s]tanco (ciò non riguarda peraltro i legamenti, che in tal modo manifestano un’indole vocalica; cfr. [s]uono, [s]iero). Le nasali preconsonantiche si assimilano invece alla consonante seguente in rapporto al luogo diaframmatico (ma ancora con esclusione dei legamenti):
(11) ca[n⊓̪]to (con diacritico indicante contatto dentale)
co[nj]scio (contatto postalveolare)
a[ɱ]fora (contatto labiodentale)
fa[ŋ]go (contatto velare)
Questo processo, a differenza del precedente, si applica anche a livello post-lessicale: co[ŋ] Carlo, i[ɱ] vetta, i[m] barca, di contro a ga[s] velenoso.
Il processo di geminazione consonantica a inizio di parola, noto come raddoppiamento (o rafforzamento) fonosintattico (➔ raddoppiamento sintattico), è un tratto caratteristico dell’italiano, anche se non costituisce un unicum sul piano tipologico. Esso si applica automaticamente quando una consonante iniziale (con le precisazioni sotto indicate) segua immediatamente una vocale accentata, purché non si frapponga una pausa: per es., andò [vː]ia, sto [bː]ene. Il raddoppiamento fonosintattico è anche prodotto da un ristretto numero di monosillabi atoni e bisillabi piani: ad es., a [tː]e, come [lː]ui. In tal caso si parla di raddoppiamento irregolare o idiosincratico, in quanto condizionato da particolari lessemi, anziché governato da una regolarità fonologica.
Si tratta, chiaramente, del residuo del processo di ➔ assimilazione a confine di parola che si applicava in maniera automatica nell’italiano antico, e che continua ora a manifestarsi anche dopo che le consonanti etimologiche finali sono da lungo tempo cadute (ad es., a < lat. ad). Quando la consonante bersaglio appartiene al novero delle rafforzate /ʎ ɲ ʃ ʦ ʣ/, il raddoppiamento fonosintattico non produce alcun effetto, dato che si tratta di foni intrinsecamente geminati. Restano invece esclusi dall’effetto raddoppiante i legamenti /j w/ (cfr. tre [w]ova), il che ne conferma l’intrinseca debolezza articolatoria; e lo stesso accade per la /s/ iniziale preconsonantica, poiché ciò creerebbe una sequenza fonotatticamente impossibile in italiano (cfr. tre [s]cudi).
Tutti gli altri nessi consonantici iniziali, per contro, purché appartengano alla fonotassi nativa dell’italiano, soggiacciono al processo in questione: tre [fːr]agole, tre [fːj]ori. Ne restano esclusi soltanto i nessi non autoctoni appartenenti per lo più a prestiti colti di origine greca, come [ps] di psicologia, [kn] di Cnosso, [pn] di pneumatico, [pt] di pterodattilo. Peraltro, il nesso /vl/, estraneo al lessico italiano pur non violando le proprietà fondamentali della sua fonotassi, può subire raddoppiamento (cfr. a [vː]ladimiro). Conviene infine notare che, benché si sia cercato di individuare condizionamenti propriamente sintattici per il manifestarsi del raddoppiamento fonosintattico, l’unica regolarità che sembra davvero sussistere concerne l’assenza di fratture ritmico-intonative tra le due parole interessate dal fenomeno (per uno studio recente, cfr. Absalom, Hajek & Stevens 2004).
Come ogni lingua, l’italiano presenta restrizioni di carattere distribuzionale (➔ parola italiana, struttura della). Per quanto riguarda il vocalismo atono, emerge l’assenza di /u/ in fine di parola, tranne in rari prestiti quale bantu (di cui peraltro esiste anche la pronuncia tronca bantù); la /u/ atona in fine di parola è semmai una caratteristica di certi dialetti (reatino, sardo, salentino). Per ciò che riguarda invece il vocalismo tonico, la lacuna in posizione finale è costituita da /o/, mentre tutte le altre possibilità sono attestate: cfr. città, per[ɔ], caff[ɛ], perch[e], virtù, finì. La /o/ accentata ricorre solo nella pronuncia colta di certe parole straniere, come Bordeaux, anche se il prestito corrispondente, indicante un tipo di rosso, è stato adattato in (bord[ɔ]). Analogo processo di abbassamento si è avuto per no (< lat. nōn), che avrebbe dovuto a rigore presentare la vocale chiusa.
Un’altra restrizione distribuzionale riguarda /z/, che (come si è detto) non compare a inizio di parola né alla fine (tranne forestierismi come mise). Anche /ʎ/ ha una distribuzione molto ristretta in tali posizioni, benché compaia in un lessema ad alta frequenza come gli (ma cfr., per contrasto, la pronuncia di [gl]icine). Quanto alla posizione finale di parola, nel lessico tradizionale potevano comparirvi soltanto le sonoranti (/m n l r/), ed esse anzi emergevano spesso per effetto del ➔ troncamento (cfr. tenzon, amor). In compenso, in epoca moderna la quantità di parole terminanti per ostruente – da sempre presente nei prestiti – è enormemente aumentata (cfr. gas, FIAT e perfino relax [reˈlaks], INPS [ˈimps] con nesso consonantico). Ciò rappresenta forse la più vistosa innovazione dell’italiano rispetto alla fonologia trádita, anche se è un fenomeno non nuovo.
Prosodia
Della correlazione di geminazione consonantica già si è detto in § 3.2. Le geminate implementano nella fonologia dell’italiano la categoria della quantità (➔ quantità fonologica), che resta peraltro confinata al comparto consonantico, poiché la nostra lingua (a differenza del latino) non ha quantità vocalica. Esiste peraltro una tradizione che considera lunghe le vocali italiane toniche in sillaba aperta non finale. Va chiarito che non si tratta di quantità fonologica, poiché nessuna coppia di parole italiane differisce per la durata di una vocale, diversamente dal latino (cfr. pŏpŭlŭs «popolo» ~ pōpŭlŭs «pioppo»). Si tratta, dunque, di una mera regolarità distribuzionale, ossia di un allungamento condizionato dal contesto fonotattico.
Occorre del resto precisare che tale allungamento, che induce a trascrivere casa e cassa rispettivamente come [ˈkaːsa] e [ˈkasːa], si produce unicamente quando la sillaba accentata si trova sotto accento di frase, ossia in posizione prominente entro un sintagma intonativo. E poiché tale condizione si realizza per definizione nella pronuncia di parole isolate, dove il sintagma intonativo coincide con la parola medesima, ha finito per crearsi il mito dell’allungamento vocalico in italiano. Ma esso non è che un variabile comportamento intonativo, piuttosto che un fatto stabilmente incorporato nella struttura fonologica. Tutti gli studi dedicati al problema hanno infatti concordemente mostrato che in contesto (tranne appunto sotto prominenza di frase) non si riscontra alcun allungamento (Bertinetto 1981; Landi & Savy 1996; Dell’Aglio, Bertinetto & Agonigi 2002; McCrary 2003). A livello infralessicale, il controllo della durata vocalica dipende poi da circostanze strettamente prosodiche, come il numero di sillabe atone postoniche (Marotta 1985); ed è del resto provato da tempo che (contro una tendenza diffusa) le vocali toniche italiane finali di parola non subiscono allungamento, ma hanno una durata relativamente breve, anche in fine di enunciato. Per tutte queste ragioni, non si aderisce qui alla convenzione di indicare nelle trascrizioni l’allungamento delle toniche non-finali in sillaba aperta, trattandosi di comportamento di natura post-lessicale e variabile.
Perfino le occasionali reiterazioni di vocale al confine tra due morfemi si realizzano, in pronuncia accurata, con una sorta di rapida riarticolazione – almeno in rapporto al profilo intonativo – piuttosto che come singola vocale lunga: cfr. cooperare, linee (con entrambe le vocali atone) o finii, lineetta, piissimo (con accento su una delle due vocali). Del resto, in pronuncia veloce, le due vocali si fondono in un’unica vocale breve, soprattutto quando entrambe sono atone.
L’➔accento lessicale (indichiamo in questo paragrafo convenzionalmente con l’accento acuto l’accento primario, riservando l’accento grave alle prominenze secondarie) è distintivo in italiano (cfr. fático, fatíco, faticó), anche se in base alle norme ortografiche l’➔ accento grafico viene segnato soltanto nell’ultimo caso (più saggiamente, gli spagnoli hanno imposto il simbolo grafico anche sui proparossitoni: automático, omogéneo). Come mostrano gli esempi, l’accento cade su una delle ultime tre sillabe, con rare eccezioni. Nella flessione verbale accade infatti che venga accentata la quart’ultima sillaba della III persona plurale del presente di molti verbi della prima coniugazione (cfr. cálcolano, cálcolino). Inoltre, l’aggiunta di ➔ clitici può far sì che l’accento venga a trovarsi finanche sulla sest’ultima sillaba, dato che i clitici italiani – a differenza, peraltro, dei clitici di certi dialetti meridionali, come il napoletano – non interferiscono con l’assegnazione dell’accento: cfr. teléfonaglielo e perfino, benché non per tutti accettabile, teléfonamiglielo. Peraltro, l’aggiunta di clitici si realizza oltre il livello lessicale strettamente inteso, per cui, a rigore, questi casi di accentazione fortemente ritratta non violano la norma.
La posizione dell’accento sulle parole italiane non è predicibile, a parte certi casi regolati dalla morfologia flessiva o derivativa. Il primo caso (➔ flessione) riguarda in genere le forme verbali (cfr. áma, amáva, amó, amerébbe); il secondo (➔ derivazione) riguarda invece tutte le principali parti del discorso, poiché i suffissi derivativi – tranne pochi (come -ico di sinfonico) – attraggono su di sé l’accento (cfr. pérdere / perdíbile / perdizióne), a meno che non siano seguiti da altro suffisso derivativo (perdibilitá, immobilizzazióne). L’unica regolarità che si può citare, in merito alla localizzazione dell’accento italiano, è quella che riguarda le parole con penultima sillaba chiusa, che, con rare eccezioni, sono tutte parossitone (ad es., compatto, esperto); ciò si estende anche alle parole con nesso /S/ + consonante tra le ultime due vocali (contesto), il che indica che, storicamente, tali nessi erano eterosillabici, anche se oggi la loro interpretazione è sub iudice (Bertinetto 2004). Le eccezioni sono costituite da nomi di luogo di antica origine e da prestiti per lo più antichi: árista, Lépanto, pólizza, mándorla, líberty (quest’ultimo in opposizione a libérti).
Oggi, peraltro, la suddetta regolarità sembra essere entrata in crisi in quanto meccanismo produttivo, come si può dedurre dalla crescente tendenza a ritrarre l’accento su prestiti o nomi di ditte (cfr. la diffusa pronuncia Bénetton, Fíninvest). Se si pensa che ortoepicamente si raccomanda tuttora la pronuncia ossitonica, si ha un’idea della rapidità con cui si è imposto un tale mutamento di tendenza, verosimilmente dovuto alla frequente esposizione dei parlanti alle lingue straniere; anche se, per paradosso, la ritrazione di accento produce non di rado incongrue deviazioni rispetto alla pronuncia corretta (cfr. la pronuncia [ˈpɛrformans] di performance, laddove in inglese si ha un parossitono).
L’italiano non presenta accento secondario distintivo: non esistono parole che si distinguano per l’inversione tra accento primario e secondario, come in ted. ǜbersétzen «tradurre» ~ ǘbersètzen «trapiantare». Si rinvengono semmai delle prominenze secondarie nei composti, dove il primo membro conserva traccia della posizione dell’accento nella parola da cui deriva: attàccapánni, àpriscátole, càpostazióne, tèmperamatíte. Ciò spiega il mantenimento dei timbri delle vocali medie, come in t[ɔ]stapane (per altri esempi, cfr. § 3). In ogni caso, l’effettiva salienza dell’accento secondario dipende soprattutto da due fattori: la larghezza della distanza interaccentuale e la velocità di elocuzione. La probabilità che le prominenze secondarie vengano realizzate con sufficiente evidenza aumenta in rapporto al crescere della prima condizione (distanza) e al diminuire della seconda (velocità). Ciò discende dal fatto che le prominenze secondarie dell’italiano, non avendo una stringente giustificazione fonologica (tranne nel citato caso del timbro vocalico nei composti), hanno più che altro una funzione di sostegno all’articolazione ritmico-intonativa del parlato. Lo dimostra il fatto che, nei polisillabi, la posizione delle prominenze secondarie (che conviene appunto chiamare prominenze ritmiche) non è predeterminata, ma è semmai sensibile all’adiacente contesto fonico, ossia alla distanza dall’accento della parola precedente e seguente. Accade così che una medesima parola, quale per es., solidificazione, possa essere pronunciata, in contesto, come sòlidìficazióne o solìdifìcazióne, benché fuori contesto la prima soluzione sia nettamente preferita dai parlanti, in quanto serba traccia della collocazione dell’accento su sólido (ma, con minor grado di insistenza, le prominenze secondarie possono ridursi a una sola o, in contesto con velocità elevata, addirittura nessuna). Per analoghe esigenze di scansione insistita, le prominenze ritmiche possono anche collocarsi a destra dell’accento primario, come nelle parole con accento fortemente ritratto per via di clitici: cfr. mándamelò.
L’italiano non presenta vistosi segnali giunturali (➔ fonetica sintattica; Bertinetto 1981). I confini di parola non vengono segnalati ‘positivamente’, ossia attivamente, se non per ragioni di enfasi o per evitare eventuali fraintendimenti, quando (come si suol dire) si scandiscono le parole. Ne deriva che sequenze come le seguenti sono normalmente omofone, a meno appunto di un’intenzionale sottolineatura dello stacco tra le parole:
(12) di versi ~ diversi
al largo ~ allargo
vita normale ~ vita anormale
con piacere ~ compiacere
in quest’ultimo caso con assimilazione di luogo diaframmatico della prima nasale (cfr. § 4). Per contro, sequenze come li imitano e limitano possono confondersi solo in pronuncia veloce, per elisione o fusione vocalica sul confine di parola.
Perfino i segnali di confine di parola ‘negativi’, ossia fondati sulla presenza di nessi consonantici che non possono ricorrere internamente, si presentano piuttosto di rado, poiché quasi soltanto i prestiti recenti terminano in consonanti che nel lessico tradizionale non possono presentarsi in tale posizione (cfr. stop momentaneo). Quando una parola terminante in vocale ne precede un’altra parimenti iniziante per vocale, si verifica di solito una fusione tra le due sillabe (➔ sandhi), il cui esito è però condizionato dall’eventuale presenza dell’accento di parola su una delle vocali in contatto. Se la vocale accentata è la prima, essa mantiene il proprio statuto fonematico, mentre la seconda si tramuta nell’elemento debole di un dittongo: per es., propriet[ai̯]nalienabile, palt[ɔa̯]maranto. Si tratta di comportamenti variabili, specie in rapporto alla velocità di elocuzione; in pronuncia scandita, è sempre possibile inserire un arresto glottidale tra le due vocali (cfr. propriet[aʔi]nalienabile). Se invece la vocale accentata è la seconda, solitamente entrambe conservano il proprio ruolo di nucleo sillabico (cfr. molt[aˈɛ]nfasi), a meno che non vi sia ➔ elisione della prima (cfr. fort[ˈɛ]nfasi) o che quest’ultima si riduca a legamento (cfr. cert[ja]nni).
Quando infine le due vocali sono entrambe atone, ciascuna delle due può ridursi, ovvero la prima scomparire per elisione (cfr. cod[ai̯]mmensa, buon[ja]mici, rapid[o]cchiata: per ulteriori dettagli, cfr. Camilli (19653); Canepari (19992); Mioni (2001); Marotta & Sorianello (1998).
Sta di fatto che molte parole funzionali di alta frequenza presentano un allomorfo prevocalico con elisione, risultato di un’automatizzazione del processo di cancellazione di vocale: cfr. lo, la / l’; uno, una / un(’); dello, della / dell’, ecc.
Per converso, il processo noto come troncamento, consistente nella cancellazione di /e o/ finali atone dopo sonorante, che si realizza anche davanti a consonante, è ormai in forte regresso, in quanto avvertito come arcaico e aulico. Il troncamento è ora ristretto a una lista piuttosto limitata di parole ad alta frequenza, che dispongono di un apposito allomorfo tronco da usarsi tassativamente quando il caso lo richiede:
(13) buon consiglio (~ * buono consiglio, ma al plurale: buoni consigli)
quel giorno (~ * quello giorno)
bel cane (~ * bello cane)
Ciò accade anche negli infiniti seguiti da pronome clitico – mangiar(*e)lo, veder(*e)ci – ed è la scelta decisamente favorita nei titoli seguiti da nome proprio – dottor(*?e) / ingegner(*?e) X –, nonché in certe locuzioni idiomatiche – a maggior(*?e) ragione – o certi composti sintagmatici – calor(*e) bianco. Opzionalmente, il troncamento si verifica in certe forme verbali, come gli infiniti o la terza persona del presente di volere: cfr. andar(e) via, vuol(e) tornare; e inoltre, per quanto riguarda /o/, nelle forme verbali che presentano una nasale nell’attacco dell’ultima sillaba: fan(no) tutti, prendon(o) parte, andiam(o) via.
L’italiano usa l’➔intonazione per segnalare l’articolazione sintattica dell’enunciato o per esprimere specifiche intenzioni comunicative sul piano pragmatico. A livello sintattico, l’intonazione segnala la funzione illocutiva nelle sue articolazioni di base, distinguendo fra enunciato dichiarativo, continuativo e interrogativo (nella duplice variante di interrogativa polare – o globale – e parziale, quest’ultima introdotta da elementi interrogativi; ➔ frasi nucleari; ➔ illocutivi, tipi; ➔ interrogative dirette). La parte maggiormente informativa di un contorno intonativo è quella finale, che – con valenza pragmatica neutra – è discendente nelle dichiarative e non di rado anche nelle interrogative parziali (ma con forte innalzamento sull’elemento interrogativo in attacco di frase), mentre è nettamente ascendente nelle interrogative polari e in genere di tipo discendente-ascendente nelle continuative (➔ curva melodica; Magno Caldognetto 1978). Il focus contrastivo (➔ focalizzazioni) può realizzarsi su qualsiasi componente sintattico e si manifesta attraverso un rapido innalzamento della frequenza fondamentale sulla sillaba saliente – in concomitanza con un aumento di durata e intensità – cui fa seguito un’altrettanto rapida discesa (D’Imperio 2002; Avesani & Vayra 2003; Gili Fivela & Savino 2003; De Dominicis, 2010).
Rispetto alla tipologia ritmica (➔ ritmo), l’italiano è tradizionalmente considerato una lingua a «isocronia sillabica» (Bertinetto 1981), per riprendere una terminologia diffusa benché inesatta (stress- ~ syllable-timed). In particolare, non si assiste a marcati fenomeni di riduzione timbrica (la cosiddetta centralizzazione) delle vocali atone in parlato spontaneo, se non entro i consueti margini di fisiologica contaminazione a carattere coarticolatorio (Albano Leoni, Cutugno & Savy 1995). Ciò riguarda anche la coarticolazione timbrica tra vocali adiacenti, anch’essa misurabile acusticamente, ma realizzata in maniera non perfettamente convergente – rispetto alla direzione dell’assimilazione – dai diversi parlanti, a differenza di quanto si riscontra in lingue come l’inglese, che presentano fenomeni di riduzione timbrica fonologicamente regolati nelle vocali atone (Vayra & Fowler 1992).
Varietà locali
Un’analisi puntuale della variabilità nelle pronunce locali dell’italiano richiederebbe un’ampia trattazione. Ci si limiterà a fornire qualche spunto, rinviando a testi specifici per ulteriori dettagli, anche per quanto riguarda l’esatta delimitazione spaziale dei fenomeni qui segnalati: si vedano in proposito i lavori di Canepari (1979, 1980, 19992) e, su scala più limitata, Bertinetto & Loporcaro (2005), cui questo contributo apertamente si ispira; e cfr. anche Poggi Salani (1976), Galli de’ Paratesi (1985), Rizzi & Vincenzi (1987), Schirru (1997).
Fa parte della competenza di qualunque parlante la sensibilità alle fini variazioni articolatorie, e la conseguente capacità di individuare la provenienza di un parlante formatosi linguisticamente in una località non lontana da quella del valutante. Quando poi intercorra una grande distanza, la capacità di percepire le differenze diventa un fatto scontato, al prezzo di una minor precisione nella localizzazione del parlante. Tra gli aspetti che distinguono macroscopicamente le differenti varietà vi è la configurazione del contorno intonativo. La descrizione di queste caratteristiche, nella misura in cui esse siano state fatte oggetto di studio (cfr. Canepari 19992, Endo & Bertinetto 1997), non è agevole: basti qui accennare alla forte caratterizzazione della parlata veneta, con la tipica cadenza ascendente delle dichiarative, che costituisce un elemento di difformità rispetto al comportamento consueto della maggior parte delle lingue.
È forse superfluo aggiungere (ma utile a evitare fraintendimenti) che una parte delle osservazioni che seguiranno si riferiscono a pronunce dette basilettali, ossia di taglio sociologico basso (➔ variazione diastratica). Sarebbe tuttavia errato estendere questa cautela a tutte le specificità di pronuncia sotto elencate: accade infatti non di rado – benché oggi meno che un tempo – di riscontrare uno spiccato colore locale anche in persone di elevata cultura. In ogni caso, non è difficile comprendere il disagio dello straniero che, desiderando apprendere la nostra lingua, si trova esposto a una tale difformità di comportamenti.
Vocali
Il vocalismo tonico delle diverse varietà può differire dal vocalismo standard non solo sul piano qualitativo – in relazione all’esatto timbro dei foni – ma anche rispetto al numero dei fonemi facenti parte del sistema o alla loro distribuzione. Esistono varietà che presentano solo cinque vocali toniche, come quella siciliana; nella maggior parte dei casi, tuttavia, le vocali toniche sono sette, o almeno sei.
Sono sostanzialmente sei nella varietà piemontese, dove /e/ ed /ɛ/ si oppongono, sia pure marginalmente, mentre non esistono parole in grado di far emergere l’opposizione /o/ ~ /ɔ/. In quest’ultimo caso, si possono solo notare varianti allofoniche posizionali (ad es., l’abbassamento di /o/ in [ɔ] davanti a /r/). Per le vocali medie anteriori esistono invece sporadiche coppie minime, come r[ɛ] (nel senso di «sovrano») ~ r[e] («nota musicale»). Si noterà che questa coppia inverte curiosamente i timbri dello standard, com’è segnalato anche per la varietà lombarda. Altre marginalissime opposizioni si riscontrano, sempre nella varietà piemontese, confrontando parole come tè [te] e caff[ɛ], o i nomi di certe lettere dell’alfabeto ([ɛ]mme, [ɛ]lle, [ɛ]sse) con identiche sequenze di altre parole (Betl[e]mme, sor[e]lle, bad[e]sse). A parte queste marginali opposizioni, le due vocali medie anteriori si distribuiscono tuttavia in base a criteri rigorosamente posizionali, il che contrasta con la situazione, non solo dello standard ma delle varietà centrali in genere (e di gran parte delle meridionali), in cui la distribuzione di /e/ ed /ɛ/ è lessicalmente – anziché posizionalmente – condizionata, in base a ragioni storico-etimologiche (ossia, per lo più in base a timbro e quantità dell’antecedente latino). Da questo punto di vista, le situazioni delle varietà piemontese e lombarda si assomigliano: il rendimento funzionale dell’opposizione /e/ ~ /ɛ/ è assai limitato; prevalgono ragioni puramente distribuzionali, in cui [e ɛ] emergono come allofoni di un unico arcifonema /E/.
Le regolarità distribuzionali della varietà milanese, descritta da Poggi Salani (1976) (➔ Milano, italiano di), sono riassumibili come segue: l’allofono [e] compare in sillaba aperta non finale e di conseguenza anche in dittongo (cfr. ci[e]lo, b[e]ne, p[je]no), nonché davanti a nasale non geminata (p[e]nso ~ v[ɛ]nne); tutti i casi in cui lo standard presenta /ɛ/. Per contro, [ɛ] (con abbassamento in [ɛ⊤̞]) compare in sillaba chiusa o aperta finale (cfr. bicicl[ɛ]tta, v[ɛ]rde, tè [tɛ]). Non tutte le sillabe chiuse, peraltro, esibiscono l’allofono aperto: per es., si ha /e/ nella vocale accentata degli infiniti troncati davanti a clitico (ved[e]rlo) o davanti a /gː/ (l[e]ggo). Viceversa, in sillaba aperta in iato si trova [ɛ] (cfr. n[ɛ]i «macchie della pelle»).
La varietà piemontese (➔ Torino, italiano di) differisce dal quadro appena descritto essenzialmente perché in sillaba aperta finale (non, dunque, prima di iato) compare [e], e tale allofono compare anche davanti alle geminate, con esclusione di /rː/. Un’altra differenza tra lombardo e piemontese (ma qui si hanno soprattutto in mente le varietà di Milano e Torino) si osserva circa le vocali medie posteriori: nella varietà lombarda, /o ɔ/ hanno una distribuzione lessicale simile a quella dello standard, mentre nella varietà piemontese l’opposizione non sussiste e il timbro tende a essere intermedio in termini di altezza / apertura.
Una certa tendenza alla chiusura del timbro delle vocali medie in sillaba aperta si osserva anche nel vocalismo tonico della varietà veneta (➔ Venezia, italiano di), dove peraltro le opposizioni vengono mantenute, sia pure in maniera talvolta difforme dallo standard. Inoltre, il timbro dei fonemi medio-bassi è più aperto che nello standard.
Una tendenza verso la riduzione a cinque vocali toniche si osserva in Emilia e Sardegna, e soprattutto in Salento, Sicilia (➔ Palermo, italiano di) e Calabria. I timbri risultanti sono generalmente intermedi, con colorature diverse secondo il contesto fonotattico. Nella varietà sarda, per es., il persistere del meccanismo metafonetico (➔ metafonia) attivo in certi dialetti della zona provoca l’innalzamento di /e o/ qualora nelle sillabe seguenti della stessa parola vi sia un’atona alta /i u/ (cfr. c[o̝]ni ~ c[ɔ]no). La zona centrale della penisola presenta invece un vocalismo tonico a sette elementi, con differenze locali idiosincratiche. Nella varietà toscana (si ha qui in mente soprattutto Firenze) si può sentire infatti l[ɛ]ttera, tr[e]nta, g[ɔ]nna, col[o]nna, laddove nel Lazio (o quanto meno a Roma) si hanno l[e]ttera, tr[ɛ]nta, g[o]nna, col[ɔ]nna (➔ Roma, italiano di).
Quanto alla /a/ tonica, il suo timbro può variare in maniera caratteristica. Tale vocale tende ad avere, soprattutto in sillaba aperta, un’articolazione arretrata nelle varietà piemontese e ligure, come pure in certe varietà campane (per es., Napoli), e invece decisamente avanzata in certe varietà pugliesi (soprattutto nel barese); un’articolazione leggermente avanzata sembra peraltro in espansione in un certo stile di pronuncia romano. Sempre a Roma, /o/ tonico è marcatamente alto/chiuso. I dittonghi tonici /wɔ/ possono monottongarsi in /ɔ/ in Toscana e a Roma; per converso, al Nord, ma anche in Campania, la ‹i› grafica di parole come coscienza o lascia può essere udita come legamento [j] prevocalico. In Campania, inoltre, i dittonghi /jɛ/ e /wɔ/ tendono a trasformarsi negli iati [ie uo], e qualora il secondo sia preceduto da un legamento palatale si produce una sequenza di vocale più dittongo (per es., mar[iˈwo]lo).
Circa il vocalismo atono, merita di essere segnalata una certa tendenza alla centralizzazione (in direzione dello ➔ scevà [ə]) delle vocali finali di parola nel Sud, segnatamente in Campania, Puglia, Lucania, Molise, parte dell’Abruzzo.
Una qualche tendenza alla nasalizzazione di vocale davanti a consonante nasale, specie in sillaba chiusa, si manifesta non di rado soprattutto al Nord.
Consonanti
Per ciò che riguarda il consonantismo, si riscontra una caratteristica spaccatura in merito alla realizzazione della sibilante dentale intervocalica. Al Nord e in Sardegna si afferma nettamente la pronuncia sonora (per es., a[z]ino), con perdita di eventuali coppie minime dello standard, anche a causa della neutralizzazione dei timbri vocalici medi: cfr. chie[s]e (verbo) ~ chie[z]e (nome).
Nell’Italia centromeridionale non toscana, viceversa, si afferma la pronuncia sorda, con chie[s]e per entrambi i significati. Al Nord, peraltro, la presenza di un confine di morfema può spesso bloccare il processo di sonorizzazione, come in a[s]ociale, ri[s]ollevare, vende[s]i. Ciò sta a indicare che non si tratta di un processo dall’applicazione cieca, dato che il parlante resta sensibile alla restrizione che esclude /z/ dalla posizione iniziale di parola, ivi includendo i clitici (la stessa ragione, insomma, per cui non si ha sonorizzazione in la [s]ala). Peraltro, il blocco del processo di sonorizzazione agisce soltanto nel caso in cui vi sia assoluta trasparenza semantica (come in ri[s]ollevare), mentre si annulla nel caso in cui vi sia stata opacizzazione (cfr. ri[z]altare, nel senso di «mettere in risalto» ~ ri[s]altare, nel senso di «saltare di nuovo»). Vi sono poi casi di imperfetta ➔ univerbazione, in cui si assiste a una forte oscillazione (Bertinetto 1999; Baroni 2001). I parlanti sardi sembrano essere, in merito a questo fenomeno, meno condizionati dalla rappresentazione fonologica lessicale, dato che la sonorizzazione si può osservare anche a livello post-lessicale (cfr. ga[z] inodoro). A tal riguardo va osservato che la sibilante in fine di parola, laddove compaia, è sempre sorda: la mancata sonorizzazione di ga[s] inodoro nell’intera Italia settentrionale è dunque dovuta a ragioni distribuzionali analoghe a quelle appena indicate per la posizione iniziale; fa eccezione una zona dell’Emilia, in cui, per idiosincrasia lessicale, si ha ga[z] anche in parola isolata.
Si può dunque concludere che l’unica zona che osservi l’opposizione fonematica tra /s/ e /z/ è la Toscana; dove peraltro è stata denunciata una certa penetrazione della pronuncia settentrionale, al punto che per molti parlanti si ha chie[z]e per entrambe le accezioni precedentemente indicate.
In buona parte d’Italia si ha, in posizione iniziale, soltanto l’affricata alveolare sonora /ʣ/ (cfr. [ʣ]io, [ʣ]eppa), di contro allo standard che mantiene l’opposizione ([ʦ]eppa ~ [ʣ]ebra). Tale comportamento è in espansione anche nel Lazio e in Campania, e parzialmente in Toscana.
Sul versante centrale tirrenico, soprattutto dalla Toscana al Lazio, ma con tendenze di segno analogo più a sud fino alla Sicilia, si assiste regolarmente alla deaffricazione di /ʧ/ intervocalico in [ʃ], spesso realizzato piuttosto come fricativa debole (breve e con ridotto contatto) (➔ affricate). Si vedano parole come pace o la cena, che (timbro vocalico a parte) tendono a confondersi con pasce e la scena, distinti nello standard. In Toscana, e solo lì, è molto diffusa anche la deaffricazione di /ʤ/ intervocalico: cfr. a[ʒ]o e la [ʒ]oia di contro a con [ʤ]oia.
Ancora con riguardo alle ➔ fricative, si segnala come processo di segno opposto il rafforzamento in affricata (almeno tendenziale) di /s/ dopo sonorante dentale, diffuso in gran parte della Toscana e nel versante medio-tirrenico, con crescente espansione al Sud e in Sardegna: pen[ʦ]o, cor[ʦ]a. Tale processo trova applicazione anche a livello post-lessicale (cfr. col [ʦ]ole). Caratteristica delle parlate campane è invece la palatalizzazione di /S/ davanti a consonante non dentale / alveolare (cfr. [ʒ]mania, [ʒ]garbo, [ʃ]pesso, [ʃ]fitto). Analoghe palatalizzazioni di /S/ in determinati contesti si riscontrano in altre parti d’Italia, e segnatamente in Emilia, dove l’articolazione arretrata di /S/ è generalizzata.
La vibrante è generalmente pronunciata con articolazione alveolare, salvo deviazioni individuali. In alcune aree del Nord (come in Emilia e in Piemonte) si osserva, peraltro, una significativa presenza dell’articolazione uvulare, mentre in Sicilia è diffusa l’articolazione fricativa, non di rado retroflessa soprattutto dopo occlusiva dentale (tre), mentre in posizione di coda sillabica, e dunque prima di consonante, /r/ può assimilarsi (cfr. la pronuncia Pale[mː]o).
La laterale in coda sillabica mostra una vistosa tendenza alla velarizzazione in certe zone dell’Emilia (tipicamente, il Ferrarese) o del Friuli, mentre a Venezia può vocalizzarsi in posizione intervocalica. Quanto alla laterale palatale, essa può realizzarsi come fricativa palatale sonora geminata nella varietà laziale, e spesso anche umbra e marchigiana (cfr. a[ʝː]o, con confusione tra aio e aglio); lo stesso fenomeno si osserva in Campania e in Sicilia. Per contro, nelle pronunce settentrionali in genere può accadere che le sonoranti palatali /ʎ ɲ/ siano prodotte con punto di contatto avanzato, tanto da creare a volte la sensazione di una convergenza fra le pronunce di l’Italia e li taglia, Campania e campagna (Mioni 2001).
Le geminate sono pronunciate in maniera meno marcata al Nord, dove anzi le pronunce basilettali possono connotarsi per la labilità della correlazione di geminazione, soprattutto nelle varietà veneta e friulana. Questo si ripercuote anche sulla realizzazione delle geminate intrinseche [ʎ ɲ ʃ ʦ ʣ], che al Nord non sono tali, al punto da consentire l’insorgere di occasionali coppie minime, come vizi (con [ʦ]) ~ vizzi (con [tːs]). Si tratta di un tipico caso in cui l’➔ortografia sembra ispirare la pronuncia, come è proprio delle zone della penisola in cui l’italiano è stato per lungo tempo una lingua riservata alle élite scolarizzate, mentre la maggior parte della popolazione parlava soltanto la lingua evolutasi spontaneamente in loco, ossia il dialetto. Peraltro, a dispetto di quanto appena notato, tra le consonanti rafforzate quelle che tendono ad accorciarsi di meno, in termini di misurabilità acustica, sono proprio le affricate dentali [ʦ ʣ]. Caratteristicamente discordante dallo standard è anche il controllo della quantità consonantica in Sardegna, dove le geminate (anche intrinseche) tendono ad accorciarsi, mentre in compenso diventano semilunghe certe consonanti postoniche (cfr. anda[tː]o).
Nella pronuncia laziale (specialmente a Roma; ma anche in altre parti d’Italia, come la Versilia) un analogo processo di degeminazione può riguardare [rː]. In compenso, nella varietà romana certi fonemi intervocalici figurano sempre rafforzati: il legamento /j/ (ma[ʝː]ale) e le ostruenti /ʤ b/ (cfr. fa[dːʒ]olo, tu[bː]o), che si rafforzano anche a livello post-lessicale (lo [ʝː]ato, la [dːʒ]emma, la [bː]uca). L’allungamento di /ʤ b/ è un fenomeno largamente diffuso in tutto il Sud.
Un fenomeno marginale e basilettale di rafforzamento è la geminazione iniziale lessicalmente idiosincratica, riscontrabile in poche parole nella pronuncia laziale in sequenza fonica, ossia non a inizio assoluto d’enunciato: cfr. la [kː]iesa, la [sː]edia, la [mː]erda, di [lː]à, di [kː]uà (fenomeni analoghi si osservano in vari dialetti centromeridionali; Bertinetto & Loporcaro 1999; Romano 2003).
Il fenomeno contrario, l’indebolimento delle occlusive sonore intervocaliche /b d g/, che tendono a spirantizzarsi in [β δ γ], si manifesta in parte della Toscana e altre zone centrali. Assai noto è, a tal riguardo, l’➔indebolimento delle occlusive sorde intervocaliche (dunque, non dopo pausa o sia pur lieve frattura ritmico-intonativa) tipico di molte parlate toscane e conosciuto col nome di gorgia (➔ gorgia toscana). Esso tocca soprattutto la velare, ma anche – per lo meno nell’area fiorentina – la bilabiale e la dentale: cfr. coca-cola [kɔhaˈhɔla]. La gorgia ha varia implementazione fonetica (Sorianello 2003). Limitatamente alla velare, in certe zone della Toscana (specie occidentale) si può arrivare al dileguo: cfr. pisano popolare [ˈbuo] per buco. Analogamente, nel Lazio le occlusive sorde intervocaliche (ma anche prima di legamento o liquida tautosillabici) si leniscono, dando vita a foni leggermente sonorizzati (resi, in trascrizione, mediante i simboli di occlusive sonore desonorizzate): cfr. hai capito [ai̯g̊aˈb̥id̥o], i quadri [iˈg̊wadri], litro [ˈlid̥ro]. Come si evince dal primo esempio, il processo non viene bloccato dalla presenza di un legamento palatale precedente, riconfermando la natura vocalica di /j/. Inoltre, il processo può estendersi – benché con minor regolarità – alla sibilante (ripósati [riˈb̥ɔz̥ad̥i]. Ancora con riguardo alle occlusive sorde, non può passare inosservata l’➔aspirazione – un fenomeno tipicamente rafforzante – che contraddistingue tali consonanti in certe pronunce calabresi.
A livello di fonotassi, merita segnalare che il raddoppiamento fonosintattico, sopra descritto per quanto riguarda lo standard, caratterizza praticamente tutte le varietà centromeridionali, sia pure con comportamenti differenziati da luogo a luogo. In Toscana e a Roma vale la regolarità che impone il raddoppiamento della consonante iniziale (tranne per i nessi che lo impediscono) dopo sillaba tonica aperta; ma per quanto riguarda il cosiddetto raddoppiamento irregolare – indotto idiosincraticamente da liste chiuse di lessemi – regna una forte variabilità (Loporcaro 1997; Fanciullo 1997). Per es., mentre in Toscana la preposizione da genera quasi ovunque raddoppiamento (cfr. da [vː]oi come nello standard), in altre varietà ciò non accade. In ogni caso, la totale assenza del raddoppiamento fonosintattico al Nord costituisce un caratteristico discrimine, attestando una volta di più il forte influsso della grafia sulle pronunce settentrionali.
Sempre in merito alla fonotassi, va citato il comportamento delle nasali in coda sillabica, preconsonantiche o prepausali. In gran parte del Nord – ma con esclusione del Friuli – emerge l’articolazione velare (a[ŋ]fora, pe[ŋ]so), su confine di morfema anche davanti a dentale (u[ŋ] lume, co[ŋ] Dino). Al Centro, per contro, la nasale è rigorosamente omorganica alla consonante seguente per assimilazione di luogo diaframmatico: a[ɱ]fora, a[n]tico, a[ŋ]cora. In certe zone del Sud si assiste invece alla frequente sonorizzazione della consonante post-nasale (cfr. tan[d]o), con occasionale perdita di coppie minime (come manto e mando dello standard). Un diverso processo assimilatorio, rispetto al luogo diaframmatico, si riscontra spesso nell’Italia centromeridionale per i nessi di nasale + sonorante: un ramo [uˈrːamo], un lago [uˈlːago], in mente [iˈmːente] (l’ultimo caso rientra nell’assimilazione di luogo diaframmatico della nasale preconsonantica).
Ancora a livello fonotattico, nell’Italia centrale compare – in pronuncia basilettale – una /e/ finale epitetica (➔ epitesi) in parole terminanti per consonante, con allungamento di quest’ultima (cfr. gasse, tramme).
Studi
Absalom, Matthew, Hajek, John & Stevens, Mary (2004), Il fenomeno del raddoppiamento sintattico nella realtà linguistica italiana, in Il parlato italiano. Atti del convegno nazionale (Napoli, 13-15 febbraio 2003), a cura di F. Albano Leoni et al., Napoli, M. D’Auria (CD-Rom).
Agostiniani, Luciano (1989), Fenomenologia dell’elisione del parlato in Toscana, «Rivista italiana di dialettologia» 13, pp. 7-46.
Albano Leoni, Federico, Cutugno, Francesco & Savy, Renata (1995), The vowel system of Italian connected speech. Proceedings of the XIIIth international congress of phonetic sciences (Stockholm, 13-19 August 1995), edited by K. Elenius & P. Branderud, Stockholm, Royal institute of technology, Department of speech communication and music acoustics, 4 voll., vol. 4°, pp. 396-399.
Avesani, Cinzia & Vayra, Mario (2003), Broad, narrow and contrastive focus in Florentine Italian. Proceedings of the XVth international congress of phonetic sciences (Barcelona, 4-9 August 2003), edited by M.J. Solé, D. Recasens & J. Romero, Barcelona, Universitat Autonoma de Barcelona, 3 voll., vol. 2°, pp. 1803-1806.
Baroni, Marco (2001), The representation of prefixed forms in the Italian lexicon. Evidence from the distribution of intervocalic [s] and [z] in Northern Italian, in Yearbook of morphology 1999, edited by G. Booij & Z. van Marle, Dordrecht, Kluwer Academic Publishers, pp. 121-152.
Belardi, Walter (1959), Elementi di fonologia generale, Roma, Edizioni dell’Ateneo.
Berruto, Gaetano (1987), Sociolinguistica dell’italiano contemporaneo, Roma, La Nuova Italia Scientifica.
Bertinetto, Pier Marco (1981), Strutture prosodiche dell’italiano. Accento, quantità, sillaba, giuntura, fondamenti metrici, Firenze, Accademia della Crusca.
Bertinetto, Pier Marco (1989), Reflections on the dichotomy ‘stress- ~ syllable-timing’, «Revue de phonétique appliquée» 90-93, pp. 99-130.
Bertinetto, Pier Marco (1999), Boundary strength and linguistic ecology (mostly exemplified on intervocalic /s/-voicing in Italian), «Folia linguistica» 33, pp. 267-286.
Bertinetto, Pier Marco (2004), On the undecidable syllabification of /sC/ clusters in Italian. Converging experimental evidence, «Italian journal of linguistics», 16, pp. 349-372.
Bertinetto, Pier Marco & Loporcaro, Michele (1999), Geminate distintive in posizione iniziale: uno studio percettivo sul dialetto di Altamura (Bari), «Annali della Scuola Normale Superiore di Pisa» s. 4a, 4, pp. 305-322.
Bertinetto, Pier Marco & Loporcaro, Michele (2005), The sound pattern of standard Italian, as compared with the varieties spoken in Florence, Milan and Rome, «Journal of the International Phonetic Association» 35, 2, pp. 131-151.
Bruni, Francesco (a cura di) (1992), L’italiano nelle regioni. Lingua nazionale e identità regionali, Torino, UTET.
Calamai, Silvia & Bertinetto, Pier Marco (2006), Per uno studio articolatorio dei glides palatale, labio-velare e labio-palatale dell’italiano, in Scienze vocali e del linguaggio. Metodologie di valutazione e risorse linguistiche. Atti del III convegno nazionale dell’Associazione italiana di scienze della voce (Povo di Trento, 29 novembre-1 dicembre 2006), a cura di V. Giordani, V. Bruseghini & P. Cosi, Torriana, EDK.
Camilli, Amerindo (19653), Pronuncia e grafia dell’italiano, a cura di P. Fiorelli, Firenze, Sansoni (1a ed. 1941).
Canepari, Luciano (1979), Introduzione alla fonetica, Einaudi, Torino.
Canepari, Luciano (1980), Italiano standard e pronunce regionali, Padova, CLEUP.
Canepari, Luciano (19992), Il MaPI. Manuale di pronuncia italiana, Bologna, Zanichelli (1ª ed. Manuale di pronuncia italiana, con un pronunciario di oltre 30.000 voci, 1992).
Castellani, Arrigo (1956), Fonotipi e fonemi in italiano, «Studi di filologia italiana» 14, pp. 435-453 (poi in Id., Saggi di linguistica e filologia italiana e romanza (1946-1976), Roma, Salerno Editrice, 1980, 3 voll., vol. 1°, pp. 49-69).
Celata, Chiara & Kaeppeli, Barbara (2003), Affricazione e rafforzamento in italiano: alcuni dati sperimentali, «Quaderni del laboratorio di linguistica» 4, pp. 43-59.
Coveri, Lorenzo & Bettoni, Camilla (1991), Italiano e dialetti italiani fuori d’Italia. Bibliografia, Siena, Scuola di lingua e cultura italiana per stranieri.
De Dominicis, Amedeo (2010), Intonazione, Roma, Carocci.
Dell’Aglio, Monica, Bertinetto, Pier Marco & Agonigi, Maddalena (2002), Le durate dei foni vocalici in rapporto al contesto nel parlato di locutori pisani. Primi risultati, in La fonetica acustica come strumento di analisi della variazione linguistica in Italia. Atti delle XII giornate di studio del Gruppo di fonetica sperimentale (AIA) (Macerata, 13-15 dicembre 2001), a cura di A. Regnicoli, Roma, Il Calamo, pp. 53-58.
De Mauro, Tullio (19723), Storia linguistica dell’Italia unita, Bari, Laterza (1a ed. 1963).
D’Imperio, Maria Paola (2002), Italian intonation. An overview and some questions, «Probus» 14, pp. 37-69.
DOP 1969 = Migliorini, Bruno, Tagliavini, Carlo & Fiorelli, Piero, Dizionario di ortografia e pronuncia, Torino, Eri (ed. 2008 in rete: http://www.dizionario.rai.it/).
Endo, Reiko & Bertinetto, Pier Marco (1997), Aspetti dell’intonazione in alcune varietà di italiano, in Fonetica e fonologia degli stili dell’italiano parlato. Atti delle VII giornate di studio del Gruppo di fonetica sperimentale (AIA) (Napoli, 14-15 novembre 1996), a cura di F. Cutugno, Roma, Esagrafica, pp. 27-49.
Endo, Reiko & Bertinetto, Pier Marco (1999), Caratteristiche prosodiche delle così dette ‘rafforzate’ italiane, in Aspetti computazionali in fonetica, linguistica e didattica delle lingue. Modelli e algoritmi. Atti delle IX giornate di studio del Gruppo di fonetica sperimentale (AIA) (Venezia, 17-19 dicembre 1998), a cura di R. Dalmonte & A. Bristol, Venezia, Università Ca’ Foscari.
Fanciullo, Franco (1997), Raddoppiamento sintattico e ricostruzione linguistica nel sud italiano, Pisa, ETS.
Galli de’ Paratesi, Nora (1985), Lingua toscana in bocca ambrosiana. Tendenze verso l’italiano standard: un’inchiesta sociolinguistica, Bologna, il Mulino.
Giannelli, Luciano (2000), Toscana, in Profilo dei dialetti italiani, a cura di M. Cortelazzo [poi di] A. Zamboni, Pisa, Pacini, 23 voll., vol. 9°.
Gili Fivela, Barbara & Savino, Michelina (2003), Segments, syllables and tonal alignment. A study on two varieties of Italy. Proceedings of the XVth international congress of phonetic sciences (Barcelona, 4-9 August 2003), edited by M.J. Solé, D. Recasens & J. Romero, Barcelona, Universitat Autònoma de Barcelona, 3 voll., vol. 3º, pp. 2933-2936.
Landi, Rossella & Savy, Renata (1996), Durata vocalica, struttura sillabica e velocità d’eloquio nel parlato connesso. Atti del XXIV convegno nazionale dell’Associazione italiana di acustica (Trento, 12-14 giugno 1996), a cura di A. Peretti & P. Simonetti, Trento, Provincia autonoma; Padova, Arti grafiche padovane, pp. 65-70.
Lepschy, Giulio C. (1964), Note sulla fonematica italiana, «L’Italia dialettale» 27, pp. 53-67.
Loporcaro, Michele (1996), On the analysis of geminates in standard Italian and Italian dialects, in Natural phonology. The state of the art. Papers from the Bern workshop on natural phonology (1989), edited by B. Hurch & R. Rodhes, Berlin - New York - Amsterdam, Mouton de Gruyter, pp. 153-187.
Loporcaro, Michele (1997), L’origine del raddoppiamento fonosintattico. Saggio di fonologia diacronica romanza, Basel - Tübingen, Francke.
Loporcaro, Michele (2009), Profilo linguistico dei dialetti italiani, Roma - Bari, Laterza.
Magno Caldognetto, Emanuela (1978), F0 contours of statements, Yes-No questions and Wh-questions of two varieties of Italian, «Journal of Italian linguistics» 3, pp. 57-68.
Maiden, Martin (1995), A linguistic history of Italian, London, Longman (trad. it. Storia linguistica dell’italiano, Bologna, il Mulino, 1998).
Marazzini, Claudio (1994), La lingua italiana. Profilo storico, Bologna, il Mulino.
Marotta, Giovanna (1985), Modelli e misure ritmiche. La durata vocalica in italiano, Bologna, Zanichelli.
Marotta, Giovanna (1988), The Italian diphthongs and the autosegmental framework, in Certamen phonologicum. Papers from the 1987 Cortona phonology meeting, edited by P.M. Bertinetto & M. Loporcaro, Torino, Rosenberg & Sellier, pp. 389-430.
Marotta, Giovanna & Sorianello, Patrizia (1998), Vocali contigue a confine di parola, in Unità fonetiche e fonologiche. Produzione e percezione. Atti delle VIII giornate di studio del Gruppo di fonetica sperimentale (AIA) (Pisa, 18-19 dicembre 1997), a cura di P.M. Bertinetto & L. Cioni, Pisa, Scuola Normale Superiore, pp. 101-113.
McCrary, Kristie (2003), Reassessing the role of the syllable in Italian phonology. An experimental study of consonant cluster syllabification, definite article allomorphy and segment duration (Ph.D. Dissertation), University of California, Los Angeles.
Migliorini Bruno (19613), Storia della lingua italiana, Firenze, Sansoni (1a ed. 1937).
Mioni, Alberto M. (2001), Elementi di fonetica, Padova, Unipress.
Muljačić, Žarko (1972), Fonologia della lingua italiana. Bologna, il Mulino.
Nespor, Marina (1993), La fonologia, Bologna, il Mulino.
Pellegrini, Giovanni Battista (1960), Tra lingua e dialetto in Italia, «Studi mediolatini e volgari» 8, pp. 137-153.
Pellegrini, Giovanni Battista (1977), Carta dei dialetti italiani, Pisa, Pacini.
Poggi Salani, Teresa (1976), Note sull’italiano di Milano e in particolare sulla ‘e’ tonica, in Studi di fonetica e fonologia. Atti del convegno internazionale di studi (Padova, 1-2 ottobre 1973), a cura di R. Simone, U. Vignuzzi & G. Ruggiero, Roma, Bulzoni, pp. 245-260.
Rizzi, Elena & Vincenzi, Giuseppe C. (1987), L’italiano parlato a Bologna. Fonologia e morfosintassi. Bologna, CLUEB.
Rohlfs, Gerhard (1966-1969), Grammatica storica della lingua italiana e dei suoi dialetti, Torino, Einaudi, 3 voll. (ed. orig. Historische Grammatik der Italienischen Sprache und ihrer Mundarten, Bern, A. Francke, 3 voll.).
Romano, Antonio (2003), Geminate iniziali salentine. Un contributo di fonetica strumentale alle ricerche sulla geminazione consonantica, in Parole romanze. Scritti per Michel Contini, a cura di R. Caprini, Alessandria, Edizioni dell’Orso, pp. 349-376.
Schirru, Carlo (1997), Aspetti consonantici nell’italiano del Piemonte. Versione ampliata, «Bollettino dell’Atlante linguistico italiano» s. 3a, 21, pp. 1-21.
Schmid, Stephan (1999), Fonetica e fonologia dell’italiano, Torino, Paravia.
Sorianello, Patrizia (2003), Spectral characteristics of voiceless fricative consonants in Florentine Italian, Proceedings of the XVth international congress of phonetic sciences (Barcelona, 4-9 August 2003), edited by M.J. Solé, D. Recasens & J. Romero, Barcelona, Universitat Autònoma de Barcelona, 3 voll., vol. 3°, pp. 3081-3084.
Tekavčić, Pavao (1972), Grammatica storica dell’italiano, Bologna, il Mulino, 3 voll.
Turchi, Laura & Bertinetto, Pier Marco (2000), La durata vocalica di fronte ai nessi /sC/: un’indagine su soggetti pisani, «Studi italiani di linguistica teorica e applicata» 29, pp. 389-421.
Vayra, Mario & Fowler, Carol A. (1992), Declination of supralaryngeal gestures in spoken italian, «Phonetica» 49, pp. 48-60.