
La vita artificiale
La vita artificiale
La vita artificiale (VA) estende il campo di indagine della biologia, permettendo di studiare forme di vita diverse da quelle che si trovano naturalmente sulla Terra. In questo senso, si può dire che lo VA sta alla biologia come lo chimica dei prodotti sintetici sta alla chimica dei composti naturali. Alcuni dei progressi più significativi nel campo della VA riguardano l'area della evoluzione sintetica, realizzata mediante elaboratori. Le ricerche più attuali in questo campo riguardano lo sviluppo di sistemi che si evolvono liberamente entro un ambiente digitale, in modo simile all'evoluzione per selezione naturale in ambiente organico che ha generato lo vita sulla Terra. Obiettivo principale di queste ricerche è lo realizzazione di sistemi evolutivi digitali in grado di generare un livello artificiale di complessità comparabile, come ordine di grandezza, alla complessità della vita organica.
Evoluzione sintetica
La nostra conoscenza della vita è limitata a un singolo esempio: la vita sulla Terra. Ciò rende difficile capire in cosa consista realmente, e quale sia la sua possibile evoluzione futura. Essere in grado di trasferirci su altri pianeti e osservare gli eventuali esempi di vita presenti, completamente diversi, aumenterebbe senz'altro la nostra conoscenza.
Se potessimo osservare le forme di vita in altri pianeti, è probabile che anch'esse risulterebbero basate principalmente sulla chimica del carbonio e, perciò, sarebbero molto simili agli organismi terrestri.
Le opinioni dei biologi evoluzionisti su quanto eventuali forme di vita autonome extraterrestri possano somigliare a quelle terrestri sono molteplici e differenti. Sfortunatamente, è probabile che non sapremo mai la verità. Le opinioni variano molto anche riguardo la plausibilità di forme di vita basate su mezzi diversi da quelli della chimica del carbonio. Comunque, è certo che la possibilità di osservare forme di vita di questo tipo aumenterebbe di molto il nostro livello di conoscenza, più di quanto non sarebbe possibile dall'osservazione di forme di vita su altri pianeti. La vita non basata sulla chimica del carbonio sarebbe aliena ancor più di quella extraterrestre.
Il campo relativamente nuovo della vita artificiale (VA) esplora la possibilità di creare nuove forme di vita indipendente, o elementi dei loro processi evolutivi. La VA punta alla comprensione della vita attraverso la costruzione di sistemi viventi piuttosto che attraverso la loro scomposizione sperimentale. Si tratta perciò di un tipo di approccio sintetico piuttosto che riduzioni sta oppure analitico.
Lo studio della VA può essere messo in relazione con la biologia così come la chimica dei composti sintetici lo è con la chimica dei composti naturali. Se la chimica fosse stata ristretta allo studio delle sostanze naturali che si trovano sulla Terra, essa non avrebbe mai raggiunto né l'efficacia teorica né i benefici pratici che offre oggi. Analogamente, la biologia può senza dubbio arricchirsi estendendo il proprio campo allo studio di sistemi biologici diversi da quelli che esistono naturalmente sulla Terra.
Vita sintetica?
Attraverso la costruzione di nuove forme di vita, la VA offre la possibilità di studiare forme di vita nuove (almeno dal punto di vista genetico) senza lasciare il nostro pianeta. Inoltre, queste nuove forme di vita possono includere entità non basate sulla chimica del carbonio. In effetti, parlare della creazione di nuove forme di vita può sembrare assurdo e anche spaventoso. Si deve, perciò, chiarire cosa si intende. Purtroppo, non essendoci un accordo generale sulla definizione del concetto di vita, non è facile spiegare cosa significhi crearla. Generalmente, i tentativi di definire la vita consistono nell' elencarne alcune proprietà. Il problema nasce dalla mancanza di accordo su che cosa si dovrebbe includere in un tale elenco. Le proprietà comunemente elencate sono la capacità di replicarsi, evolversi, metabolizzare, rispondere agli stimoli e riparare i danni. La maggior parte degli esempi di vita artificiale non superano una selezione basata su elenchi di questo tipo, a meno che non si riduca il numero delle proprietà considerate. Questo tipo di approccio, basato sull'elenco di proprietà vitali, non è affatto soddisfacente. Come esempio provocatorio si potrebbe considerare una qualche macchina in grado di essere coinvolta in questa stessa discussione al pari di un essere umano. Anche se tale macchina non fosse in grado di riprodursi, né di evolversi, né dimostrasse molte delle proprietà definite generalmente vitali, sarebbe difficile negare che essa sia in un certo senso viva.
Considerazioni di questo tipo ci portano ad affrontare il problema in modo diverso, ovvero costruendo una lunga lista di proprietà di cui solo i sistemi viventi siano effettivamente dotati, e richiedendo che una forma di VA mostri non tutte le proprietà elencate, ma almeno qualche esempio chiaro di qualcuna di esse. Se è così, allora possiamo dire che nel nostro sistema sintetico abbiamo isolato una qualche forma originale di vita. Molto del lavoro sulla VA deriva da questa idea. Lo studioso è interessato ad alcuni particolari aspetti della vita, come l'evoluzione, l'intelligenza, il linguaggio, il comportamento sociale, lo sviluppo, ecc.; perciò, crea un sistema che, se funzionante, presenta alcune proprietà caratteristiche della vita per quanto riguarda l'area specifica di interesse, ma che può anche non comprendere alcuna delle altre proprietà vitali. Questi sistemi diventano, in un certo senso, esempi di vita 'incorporea'. Può non essere appropriato chiedersi se essi siano vivi, dato che questa è una domanda a cui non possiamo dare una risposta; piuttosto, è più facile chiedersi se essi mostrino qualcuna delle proprietà caratteristiche dei sistemi viventi.
Il campo della VA opera in tre aree principali: la sintesi hardware, quella software e quella wetware. Nel linguaggio informatico l'hardware è la parte fisica di un elaboratore, il software è la sua parte non fisica, cioè l'insieme dei programmi e dati che esso contiene. Con wetware s'intende un sistema o modello teorico speculativo: letteralmente 'sistema [cellulare] umido' (come il cervello umano) contrapposto ai sistemi informatici artificiali ('asciutti'). Questo saggio tratterà in particolare dell' evoluzione, processo vitale di primario interesse per l'autore, e più specificatamente dell'evoluzione del software, sebbene di recente sia stato svolto un lavoro molto interessante riguardante l'evoluzione sintetica in ambiente chimico (Joyce, 1992; Hong et al., 1992), e alcuni recenti sviluppi possono finalmente permettere l'evoluzione fisica dell'hardware (Sanchez et al., 1996).
Sintesi e simulazione
La vita sulla Terra è il prodotto dell'evoluzione per selezione naturale, la quale opera nell' ambiente basato sulla chimica del carbonio. In teoria, comunque, il processo dell'evoluzione non è limitato né alla Terra, né all'utilizzo del carbonio come unico substrato chimico; infatti, così come potrebbe verificarsi su altri pianeti, esso potrebbe operare in altri ambienti, per esempio entro un sistema di calcolo digitale. Quindi, come l'evoluzione su altri pianeti, anche l'evoluzione in un ambiente digitale non rappresenterebbe necessariamente un modello dei processi vitali esistenti sulla Terra.
Poiché la sintesi software inerente alla VA si svolge in un elaboratore elettronico, c'è una grande ambiguità circa il reale significato di questo tipo di ricerche. Anche se generalmente i biologi intendono per VA modelli all'elaboratore o simulazioni di processi biologici, ovvero qualcosa con cui hanno familiarità, si deve considerare che lo scopo della VA è sostanzialmente diverso. Una simulazione è un modello di qualcosa di esistente nel mondo 'reale'; quindi, in una simulazione ci sono simboli che rappresentano altri oggetti e ci sono regole che determinano il modo in cui i simboli stessi debbano essere manipolati. Di conseguenza, la veridicità della simulazione può dipendere da quanto accuratamente i simboli e le regole corrispondano agli oggetti e ai processi che si vogliono rappresentare. In genere, i biologi sono interessati ai modelli informatici, in quanto rappresentazioni accurate di particolari processi biologici naturali. Gli studiosi della VA non utilizzano l'elaboratore come uno strumento per costruire modelli di vita organica. Piuttosto, l'elaboratore è considerato un ambiente popolabile con forme di vita non basate sulla chimica del carbonio. Il lavoro sulla VA consiste quindi nel 'seminare' questo ambiente con vari 'organismi' e 'coltivare' il sistema così che possa sostenere anche forme più evolute di vita digitale. Nella sua forma più avanzata, gli elementi di un programma di VA sono studiati in qualità di oggetti con identità propria, non come simboli che rappresentano qualcosa di diverso. Gli elementi del software sono entità digitali (costituite da bit e byte) e non interessano direttamente i biologi, abituati a pensare solamente a processi vitali basati sulla chimica del carbonio; d'altra parte, se i bit di un elaboratore producessero processi vitali, allora dovrebbero ricadere nel campo di studio della biologia. Ciò sarebbe possibile se i processi vitali non fossero necessariamente dipendenti da un ambiente basato sulla chimica del carbonio, ipotesi che rappresenta il cuore dei modelli per lo sviluppo di sistemi per le sintesi hardware e software nel campo della VA.
Lavorare con l'evoluzione digitale
La vita digitale estende la nostra concezione di vita organica ed è un utile strumento per alcuni tipi di studi biologici; in particolare, la vita digitale possiede alcune proprietà uniche che la rendono più semplice da studiare. Per prima cosa, dato che essa esiste all'interno di un elaboratore, è molto più facile ottenere i dati necessari per il suo studio. In realtà, se gli organismi digitali vivono confinati in un singolo elaboratore, è possibile raccogliere informazioni su ogni aspetto della loro esistenza senza interferire con il sistema organismo-ambiente. Ciò è impossibile con gli organismi viventi. Per esempio, nel caso di un sistema artificiale è prassi comune definire la sequenza dell'intero genoma di ogni essere digitale, sin dalla sua nascita, e questo campionamento non ha alcun effetto sull'evoluzione del sistema stesso.
Inoltre, i sistemi digitali di VA possono facilmente essere manipolati in modo molto più completo rispetto a quanto sia possibile nel caso di organismi reali e, se lo si desidera, ogni esperimento può essere ripetuto esattamente, per svolgere osservazioni non eseguite in un esperimento precedente. Inoltre alcuni processi vitali, come l'evoluzione, possono procedere molto più velocemente nei sistemi digitali piuttosto che quelli organici naturali.
Queste proprietà si combinano facendo sì che lo studio della vita digitale rappresenti un contributo essenziale allo studio della biologia. Un campo in cui questo approccio è stato molto utile è quello degli studi sull'evoluzione. Infatti, un elaboratore contenente organismi digitali può essere pensato come un sistema modello per lo studio sperimentale dell'evoluzione, alla stregua di un chemostato (dispositivo che serve a mantenere costanti alcuni parametri delle colture batteriche) contenente virus e batteri. In ogni caso, l'evoluzione di organismi digitali rappresenta una simulazione dell'evoluzione naturale tanto quanto l'evoluzione in condizioni sperimentali controllate di colture di batteri e virus.
L'evoluzione organica naturale si verifica così lentamente che è stato possibile osservare e sperimentare solo cambiamenti nelle dimensioni e nella forma di parti degli organismi (micro-evoluzione). Eccettuato lo studio dei fossili, non è stato possibile studiare l' acquisizione o la perdita di parti degli organismi, né l'origine delle specie e delle maggiori unità tassonomiche (macro-evoluzione).
D'altro canto, l'evoluzione dei sistemi digitali si realizza così velocemente che da un giorno all'altro si verificano cambiamenti sostanziali nella struttura degli organismi ed emergono intere nuove filogenie. Nonostante ciò, i sistemi digitali sono molto meno complessi rispetto alle forme di vita organica, e si può ritenere che nel momento in cui gli organismi digitali aumenteranno il loro grado di complessità, il loro tasso di evoluzione rallenterà proporzionalmente.
Evoluzione e ambiente
L'evoluzione è un processo attraverso cui vengono esplorate le possibilità date dall'ambiente circostante. Gli individui di ogni popolazione si riproducono e le popolazioni di replicatori si evolvono sperimentando nuove variazioni evolutive, senza alcun tipo di limitazione a priori. Quando il processo è basato sulla chimica del carbonio, esso si inquadra nella fisica dell'universo naturale: le leggi della chimica (per esempio, il carbonio forma quattro legami singoli in una configurazione tetraedrica), le leggi della termodinamica (per esempio, l'entropia cresce spontaneamente), e così via. Invece, quando l'evoluzione si verifica all'interno di un sistema digitale, essa si inquadra in un universo completamente differente, governato da leggi proprie, in cui non sono determinanti le leggi della termodinamica che governano interazioni tra molecole di un particolare tipo di sistema chimico. Si tratta, quindi, di un universo logico di informazione binaria invece che di un universo materiale. La 'fisica' che l'evoluzione digitale sperimenta nell' ambiente dell'elaboratore consiste nell'insieme delle operazioni logiche svolte dal processore, nella topologia (non euclidea) caratteristica della memoria, nelle regole per la distribuzione delle risorse definite nel sistema operativo, nel tempo definito dalla frequenza base della CPU (CPU clock cycle), l'unità centrale operativa dell'elaboratore.
Quando avviene nel mezzo digitale, l'evoluzione non dipende dal materiale con cui l'elaboratore è costruito. L'elaboratore potrebbe essere costituito da circuiti a elevata integrazione, da valvole o da interruttori meccanici; il processo di evoluzione è indipendente dai diversi tipi di hardware, se questi funzionano in base alla stessa logica.
Dal nostro punto di vista, differenti tecnologie hardware potrebbero, tutt'al più, funzionare a diverse velocità. Ma, dal punto di vista dell'evoluzione, l'unità di tempo è costituita dalla durata di un ciclo della CPU: indipendentemente dal fatto che essa corrisponda a un nano secondo o a un minuto, produrrà lo stesso effetto sul processo evolutivo operante all'interno dell'elaboratore. D'altra parte, nel caso di una rete di elaboratori, le frequenze relative delle diverse CPU collegate sono, invece, importanti.
Gli organismi digitali in evoluzione occupano uno spazio nella memoria RAM dell'elaboratore; poiché alle locazioni di memoria si assegnano indirizzi sequenziali, si tende a pensare a tale memoria come a uno spazio euclideo monodimensionale. Questo, però, non è vero. La topologia di uno spazio può essere definita esaminando l'insieme delle relazioni di distanza tra diversi punti appartenenti allo spazio stesso. Nel caso della memoria di un elaboratore, il concetto di distanza lineare non è significativo. L'analogo più appropriato del concetto di distanza è in tale contesto il tempo necessario a spostare informazione tra punti diversi. In questo caso, la misura del tempo costituisce la metrica per la misura delle distanze nello spazio della memoria.
In molti tipi di elaboratori (con memoria cosiddetta 'piatta'), tutte le locazioni di memoria sono equivalenti, rispetto al tempo necessario per spostare informazioni tra di esse. In un elaboratore con memoria segmentata (come nel caso dei processori Intel 80X86) esistono due possibili distanze tra le diverse coppie di locazioni, a seconda che esse appartengano allo stesso segmento di memoria oppure no. In questo caso, abbiamo uno spazio di memoria chiaramente non euclideo.
Se consideriamo la topologia della memoria di tutti gli elaboratori connessi in rete (ciberspazio), troviamo che essa è molto complessa e dinamica. Il tempo necessario a trasferire dati tra le memorie di due elaboratori dipende sia dalla loro distanza relativa, sia dalle condizioni di traffico al momento del trasferimento. In genere, i trasferimenti tra elaboratori fisicamente vicini sono più veloci di quelli tra elaboratori distanti nella rete, ma tutti dipendono dal carico di lavoro della rete in un determinato momento.
Evoluzione digitale: eliminazione del controllo esterno
Sebbene coesistano tendenze diverse per lo sviluppo di sistemi per l'evoluzione sintetica, qui tratteremo in particolare dei tentativi rivolti alla riduzione del controllo esterno sui sistemi in evoluzione digitale. Questi tentativi hanno lo scopo di permettere l'instaurarsi di processi evolutivi sintetici maggiormente simili a quelli operanti negli organismi naturali viventi sulla Terra.
Algoritmi genetici
Probabilmente, i lavori iniziali e più conosciuti sull'evoluzione digitale sono quelli noti come algoritmi genetici (AG) (Holland, 1975; Goldberg, 1989; Belew et al., 1991). Generalmente, gli AG usano porzioni di informazione (stringhe) per codificare la soluzione di un qualche problema ingegneristico. L'algoritmo genetico può ricercare la soluzione ottimale mutando e scambiando stringhe all'interno di una popolazione, valutando ripetutamente la 'idoneità' della soluzione, e poi replicando le soluzioni migliori fino a individuare quella ottimale. Durante la progettazione di un AG, per prima cosa viene determinato il modo in cui l'insieme delle soluzioni è rappresentato dalle diverse stringhe. Normalmente ciò implica una stringa di lunghezza fissata, le cui porzioni in successione rappresentano quantità ben definite (per esempio i coefficienti di una equazione). Quindi la forma della soluzione è determinata in anticipo e non prende parte al processo evolutivo. Anche se i ricercatori nel campo degli AG usano normalmente l'espressione 'selezione naturale' per descrivere i processi evolutivi, gli AG non usano affatto tale metodo di selezione, dato che utilizzano la selezione artificiale. Il progetti sta di un AG scrive un algoritmo per la funzione di idoneità, che determina quali elementi della popolazione di stringhe debbano essere favoriti. Di conseguenza, le stringhe che sono favorite si replicano con una probabilità maggiore rispetto alle altre, mentre le meno favorite possono anche essere completamente eliminate in una particolare generaZIone. Inoltre, è importante notare che le stringhe di un AG non si autoreplicano. Esse sono copiate dal programma di simulazione dopo essere state valutate dalla funzione di idoneità, e possono essere copiate esattamente o con qualche 'mutazione' nella struttura dei bit o, come avviene in molti casi, solo una porzione della stringa è copiata, in combinazione con la porzione complementare proveniente da un'altra stringa idonea opportunamente scelta. Gli AG di tipo più flessibile non richiedono stringhe di lunghezza fissata e, in questo caso, nelle stringhe possono anche esservi inserzioni o delezioni di bit. Dal punto di vista del livello di controllo, gli AG rappresentano un caso estremo, ovvero costituiscono il controllo totale del processo evolutivo. Il programma degli AG controlla tutto: la forma della soluzione, la funzione di idoneità, la natura degli operatori genetici e il metodo di replicazione. Si noti che gli AG non sono sempre conformi alle specifiche descritte precedentemente. Molte innovazioni e forme ibride possono essere studiate consultando, per esempio, le pubblicazioni della leGA (Belew et al., 1991).
Programmazione genetica
Uno sviluppo ottenuto più di recente è noto come programmazione genetica (PG). In questo caso, l'analogo delle stringhe è costituito da espressioni ad albero simili a quelle del Lisp (linguaggio di programmazione interpretato, orientato allo studio della Intelligenza Artificiale, inventato presso il MlT di Boston). Le operazioni genetiche di mutazione e scambio possono verificarsi per ogni nodo dell'albero. Nel caso di uno scambio, un nodo è scelto a caso in più alberi differenti (solitamente due) e i nodi selezionati, con tutti i loro rami e le foglie superiori, sono semplicemente scambiati.
Nel caso di una mutazione, il nodo di un albero può essere sostituito da un nodo scelto a caso, ma con lo stesso numero di rami discendenti, lasciando invariati i rami superiori e le foglie. Altrimenti, può essere messo al suo posto un nodo con maggiori o minori ramificazioni, in modo che altri rami superiori siano aggiunti o eliminati. O ancora, il nodo può essere sostituito con tutte le ramificazioni e le foglie superiori. Nel caso della sostituzione o dell'aggiunta di un ramo mutato, la sorgente dei rami utilizzati per la sostituzione e la loro struttura sono arbitrarie, e possono essere generate in modo casuale. Con questo metodo non è necessario che la forma della soluzione sia definita in precedenza, e così anch'essa può evolversi. Questo approccio permette un utilizzo più creativo del processo di evoluzione ed è stato applicato a una vasta gamma di problemi, in particolare da J. Koza (Koza, 1992, 1994). Una particolare proprietà che si osserva nell'evoluzione attraverso la PG è rappresentata dalla tendenza delle espressioni ad albero a crescere di dimensioni durante il processo evolutivo. Ciò può essere interpretato come una evoluzione a più alti livelli di complessità, realizzando in questo modo uno dei principali obiettivi della ricerca sull' evoluzione sintetica. D'altra parte, in assenza di ogni pressione selettiva sfavorevole all'acquisizione di grandi dimensioni, la crescita può implicare l'incorporazione di codice 'spazzatura', essenzialmente senza significato. Nella PG questo codice sarà nondimeno valutato dal sistema, così che gli algoritmi più grandi richiederanno un maggior sforzo computazionale per essere valutati. Per questa ragione, è desiderabile che gli algoritmi di programmazione genetica incorporino meccanismi selettivi contro la tendenza a una crescita inutile delle dimensioni.
Anche se i programmi per la PG presentano uno spazio delle soluzioni con codice a struttura libera, essi condividono con gli AG un controllo totale sulla natura della 'funzione di idoneità' e sul processo di replicazione.
Selezione estetica
K. Sims ha usato il metodo della programmazione genetica combinando lo con una selezione basata su regole 'estetiche' espresse dall 'utente per fare evolvere immagini astratte (Sims, 1991; 1993). Questo approccio costituisce un progresso verso la possibile sostituzione della funzione di idoneità. Nei tradizionali AG e PG, la funzione di idoneità è intrinsecamente codificata nel sistema computazionaIe; nelle immagini genetiche di Sims, invece, la funzione di idoneità è sostituita dalla selezione estetica dell 'utente umano, a ogni generazione di immagini. Questi criteri di selezione sono imprevedibili e cambiano a ogni generazione, mentre gli operatori genetici creano nuovi gruppi di immagini tra cui scegliere.
Le creature virtuali di Sims
Sims ha usato un sistema genetico altrettanto flessibile per risolvere il problema di definire una 'creatura' costituita di blocchi, collegati con giunti flessibili, mossi da 'muscoli' e controllati da circuiti (Sims, 1994a; 1994b); inoltre, egli ha inserito queste creature a blocchi in una simulazione della realtà fisica, per esempio in acqua o su una superficie. Esse venivano, quindi, selezionate in base alla capacità di svolgere un certo insieme di attività; per esempio nuotare, dirigersi verso una sorgente di luce, muoversi lungo una superficie, saltare su una superficie e tentare di impossessarsi di un blocco quadrato in competizione con un'altra creatura.
Questi esperimenti hanno prodotto una grande e affascinante varietà di creature. Alcune hanno l'aspetto familiare di un 'serpente' che nuota o di un 'granchio' che cammina; altre sono specializzate nei loro compiti, ma possiedono forme e movimenti assolutamente inusuali. Questa enorme proliferazione di forme ricorda quella che si è verificata tra gli animali nella fase evolutiva nota come esplosione cambriana, quando sono state sperimentate dall'evoluzione molte più strutture e forme animali di quante siano successivamente sopravvissute e siano attualmente presenti sulla Terra.
In pratica questo lavoro è paragonabile agli AG e alla PG, ma i genotipi sono basati su rappresentazioni grafiche, invece che su stringhe o strutture ad albero. La funzione di idoneità è prede finita (per esempio la velocità massima), così come in tutti i sistemi di ottimizzazione. Tuttavia, l'obiettivo del lavoro non era quello di trovare la soluzione ottimale, ma piuttosto generare una diversità di soluzioni per le diverse funzioni di idoneità. In effetti, il sistema progettato ha generato una sbalorditiva varietà di soluzioni.
Invece di presentare il risultato sotto forma di una curva di ottimizzazione, mostrando la crescita di ciascun parametro evolutivo (per esempio la velocità massima), Sims ha presentato i suoi risultati sotto forma di un trattato di storia naturale, riportando le forme anatomiche e il comportamento di molti individui nel corso del processo evolutivo.
Nell'esperimento in cui l'obiettivo era rappresentato dal possesso di un blocco è stato diminuito il controllo esercitato dalla funzione di idoneità. Questo tipo di esperimento produceva una competizione tra due popolazioni evolutesi contemporaneamente, e saggiate attraverso il confronto di coppie di individui. Ogni singola creatura in competizione contribuisce alla trasformazione evolutiva dell'intero sistema, indipendentemente dalla definizione iniziale della funzione di idoneità. Quindi, in questo caso, la selezione naturale costituisce una componente significativa dell'intero processo evolutivo.
Coevoluzione
Una caratteristica comune agli AG e alla PG è che la funzione di idoneità valuta i singoli genomi indipendentemente dagli altri elementi della popolazione. In pratica, i diversi organismi interagiscono soltanto con la funzione di idoneità (e in qualche caso con i dati), ma non reciprocamente. Questo schema preclude l'evoluzione di soluzioni collettive ai problemi evolutivi che potrebbero rivelarsi molto interessanti.
L'esempio delle creature di Sims che competono per il possesso di un blocco è il primo caso tra quelli che abbiamo finora considerato in cui si verifica una interazione diretta tra gli elementi della popolazione in evoluzione. Altri esempi di questa interazione saranno considerati nei paragrafi successivi. D.W. Hillis (1991) si è servito degli algoritmi genetici per fare evolvere algoritmi che ordinano liste di sedici numeri. L'idoneità di questi algoritmi è stata valutata sulla base della percentuale di liste di prova che venivano ordinate correttamente. L'autore ha riscontrato che questo processo evolutivo non è particolarmente efficiente, perché in breve tempo l'evoluzione produceva algoritrni di ordinamento che potevano ordinare correttamente la maggior parte delle liste di prova. In realtà, molte delle liste utilizzate non risultavano sufficientemente discriminatorie per la selezione di algoritmi di ordinamento altamente efficienti. Inoltre, l'intero processo tendeva ad arenarsi in corrispondenza di 'massimi locali' delle funzioni descriventi l'andamento dei parametri evolutivi. Nel tentativo di migliorare l'efficienza dell'intero processo, Hillis ha permesso che le liste di prova venissero determinate da un insieme di algoritrni genetici che si evolveva in connessione con tali liste. L'idoneità di ciascuna lista di prova veniva calcolata come l'inverso dell'idoneità degli algoritrni di ordinamento, considerata come il numero degli algoritrni di ordinamento che non erano in grado di ordinare correttamente la lista esaminata. Nel sistema in cui gli algoritmi di ordinamento e le liste di prova si evolvevano simultaneamente, il processo era molto più efficiente (in termini di sforzo di calcolo richiesto), e alla fine produceva algoritmi di ordinamento più semplici ed efficienti rispetto a quelli prodotti in assenza di evoluzione simultanea.
Selezione naturale
Mentre di solito nei lavori sull'evoluzione digitale gli obiettivi sono determinati in fase di progettazione, ci sono stati alcuni lavori elaborati con il solo scopo di esplorare lo sviluppo di un processo evolutivo in un ambiente inusuale. In questo caso, sono state create le condizioni affinché programmi autoreplicanti si evolvessero liberamente attraverso la selezione naturale. Come risultato si è avuta la produzione filogenetica spontanea di differenti stirpi di organismi digitali, all'interno di una comunità ecologica nel ciberspazio.
Nel 1994, L. Yaegerharealizzato un sistema basato sugli A G, chiamato PolyWorld, che si è evoluto liberamente per selezione naturale (Yaeger, 1994). L'AG defmisce le caratteristiche di alcuni 'organismi' in grado di vivere su una superficie piatta simulata, sulla quale possono essere presenti alcune barriere. Inoltre, distribuito sulla superficie, c'è del 'cibo'. Tali organismi hanno corpi poligonali colorati, un sistema visivo, e reti neurali che utilizzano i modelli di apprendimento di Hebb per il funzionamento delle loro sinapsi. I dati elaborati dalla rete neuronale determinano il comportamento di ciascun organismo, attraverso l'impiego di specifici neuroni in grado di controllare l'attivazione di sette tipi di azione: mangiare, accoppiarsi, combattere, muoversi, girare, mettere a fuoco, illuminare. Tutti i comportamenti, inclusa l'attività della rete neurale, consumano energia, la quale può essere ricostituita mangiando il cibo. La stringa principale dell'AG determina la struttura e alcune caratteristiche funzionali dell'organismo. Essa rappresenta i valori seguenti: la dimensione, la forza, la velocità massima, la sfumatura della colorazione verde, il tasso di riproduzione, la durata della vita, la frazione di energia necessaria per la riproduzione e undici parametri caratteristici della rete neuronale. PolyWorld può essere inizialmente popolato con genomi generati a caso; talvolta questi non sono in grado di riprodursi e, di conseguenza, il sistema si estingue. Altre volte si creano delle popolazioni stabili, e si genera una grande varietà di comportamenti e di ecologie.
Il sistema Tierra
La mia attività di ricerca segue (concettualmente e in parte cronologicamente) la tendenza a lasciare una sempre maggiore libertà al processo di evoluzione digitale. A questo scopo, ho costruito un sistema in cui alcuni programmi per elaboratore si autoreplicano, e l'unico criterio di 'idoneità' chiaramente definito e imposto è lo stesso che si trova nella evoluzione organica: la capacità di riprodursi, cioè trasmettere il proprio patrimonio genetico alle generazioni successive. Il mio sistema, chiamato Tierra (Terra in spagnolo) crea un semplice scenario darwiniano di base: entità finite con una grande variabilità genetica che si autoreplicano in un ambiente, all'interno dell'elaboratore. L'indirizzo World Wide Web è http://www.hip.atr.co.jp/ ~ray/tierra/tierra.html (Ray, 1991; 1994a; 1994b).
La metafora
In Tierra, le entità che si autoreplicano sono programmi eseguibili in linguaggio macchina; essi non fanno altro che ricopiare sé stessi nella memoria RAM dell'elaboratore. Pertanto, il codice in linguaggio macchina rappresenta l'analogo del codice genetico della vita organica, basato sugli acidi nucleici. La replicazione dei programmi è realizzata mediante la loro esecuzione da parte della cpu. Pertanto, il tempo dedicato dalla cpu alla loro elaborazione è l'analogo dell'energia che guida il metabolismo. I programmi in linguaggio macchina occupano spazio nella memoria RAM, quindi essa rappresenta l'analogo dello spazio fisico per la vita organica. Ciascun programma 'possiede' il blocco di memoria che esso stesso occupa e ha il privilegio esclusivo di scrivere all'interno del proprio blocco. Però ogni processo può leggere, o eseguire, istruzioni in ogni parte della memoria; quindi, il privilegio parziale (accesso alla scrittura) nello spazio occupato da ciascun programma può rappresentare l'analogo della membrana semipermeabile che circonda le cellule organiche, e che protegge parzialmente dalla distruzione l'apparato biochimico contenuto all'interno.
Nella popolazione dei programmi che si riproducono sono state introdotte mutazioni geniche, scambiando a caso gli elementi del codice in linguaggio macchina, inducendo un fenomeno analogo alle mutazioni in cui si creano sostituzioni di nucleotidi nelle sequenze del DNA degli organismi viventi. Al sistema è stato aggiunto un altro elemento di variazione casuale sotto forma di errori occasionali nei calcoli eseguiti dalla cpu. Per esempio, quando la CPU deve sommare due numeri, talvolta il risultato è inesatto per più o meno uno. Quando la CPU esegue l'operazione di scalare di una posizione a sinistra tutti i dati in un registro di memoria, talvolta essi risultano scalati di due posizioni, oppure non sono scalati affatto. Quando una informazione deve essere spostata tra due locazioni, può essere trasferita a una locazione vicina invece che a quella corretta. Errori di calcolo di questo tipo, poco frequenti, sono considerati l'analogo dei sottoprodotti chimici dei processi metabolici che hanno luogo all'interno delle cellule organiche. Tali errori non costituiscono di per sé mutazioni geni che, ma possono esserne la causa. Quando la memoria dell' elaboratore si satura, il sistema operativo darwiniano comincia a eliminare i programmi più vecchi e più difettosi, e ciò lascia spazio libero per le nuove generazioni. Quindi, l'eliminazione di un particolare programma da parte del sistema operativo rappresenta l' analogo della morte. L'ambiente dell'elaboratore viene seminato all'inizio con un singolo organismo digitale, detto progenitore. Si tratta di un programma in linguaggio macchina di una ottantina di byte. Esso prima di tutto esamina se stesso per determinare la sua dimensione e la sua locazione nella memoria; poi individua e riserva la memoria libera per il proprio discendente, usando il servizio di allocazione di memoria del sistema operativo darwiniano. Successivamente, copia se stesso byte per byte, dal 'programma madre' al 'programma figlia'; dopo la riproduzione, lancia l'esecuzione del programma figlia come un processo indipendente.
La macchina virtuale
Tentare di creare un processo darwiniano su un elaboratore convenzionale sarebbe impossibile per molte ragioni, tra cui le principali sono le seguenti: l) gli elaboratori convenzionali non hanno istruzioni in linguaggio macchina per lo scambio casuale di dati, e non fanno errori di calcolo; 2) il tentativo di eseguire istruzioni che siano state alterate in modo casuale porterebbe velocemente a una condizione di errore che arresterebbe l'elaboratore; 3) i sistemi operativi degli elaboratori multi-processore permettono ai programmi di lanciare processi figli, ma non hanno la funzione di eliminare i processi più vecchi in modo da produrre il ricambio di generazioni richiesto da un ambiente darwiniano.
Superare questi problemi utilizzando un elaboratore convenzionale richiederebbe considerevoli modifiche al sistema. Una volta fatto questo, se i programmi fossero in grado di evolversi, potrebbero in teoria riprodursi senza controllo, come un programma virus, su altri elaboratori dello stesso tipo (per esempio da Macintosh a Macintosh). Ma la loro evoluzione, o la semplice riproduzione, non potrebbe continuare sulle macchine infettate a meno che quest'ultime fossero modificate in modo analogo all'elaboratore originale.
Tutti questi problemi possono essere superati progettando un nuovo elaboratore con lo scopo specifico di permettere l'evoluzione dei programmi. Questo nuovo elaboratore avrà sia un'architettura fisica che un sistema operativo progettati per sostenere i processi darwiniani. Il progetto di ogni nuovo elaboratore (o di qualunque prodotto complesso) oggi comincia con una sua simulazione utilizzando un apposito programma. È possibile creare un programma che abbia le stesse caratteristiche dell'elaboratore che si vuole costruire. Questa, per esempio, è l'idea di base dei programmi soft-PC, che rendono possibile eseguire su un Macintosh o su un elaboratore Sun i programmi per un personal computer IBM-compatibile.
Una simulazione di un elaboratore è chiamata elaboratore virtuale. Poiché essa funziona esattamente come l'oggetto reale (eccetto che per la limitata velocità di esecuzione dei programmi), non è necessario costruire fisicamente il nuovo elaboratore. L'elaboratore darwiniano è stato chiamato Tierra ed esiste solo come elaboratore virtuale. Esso è in grado di funzionare su molti sistemi operativi diversi (DOS, Windows, Macintosh, Unix, VMS, Amiga) rendendo non più necessaria la progettazione e costruzione di sistemi hardware dedicati. Inoltre, il sistema virtuale di simulazione è dotato di una sicurezza assoluta perché solo nel proprio ambito i programmi per la creazione degli organismi virtuali sono in grado di funzionare. Per i sistemi operativi convenzionali essi rappresentano solo insiemi di dati, e non possono essere eseguiti, esattamente come non possono essere eseguiti i file di testo creati da un qualsiasi programma di scrittura.
Tipi di evoluzione
I risultati dell' evoluzione finora osservati individuano una molteplicità di soluzioni al problema di ottenere programmi in linguaggio macchina che si autoreplicano. Possiamo dividerli in due classi distinte: soluzioni ecologiche e ottimizzazioni. Le soluzioni ecologiche sono rappresentate dai programmi che interagiscono reciprocamente e condividono porzioni di memoria, mentre le ottimizzazioni sono irmovazioni individuali in particolari algoritmi, tali da renderli più veloci nella riproduzione.
Evoluzione ecologica
Gli adattamenti ecologici sono causati dalla presenza stessa degli organismi digitali nell'ambiente. Quindi alcuni organismi possono sviluppare adattamenti, in relazione ad altri organismi, come il parassitismo, l'immunizzazione, la cooperazione e l'inganno. Sono stati ottenuti adattamenti che utilizzano le due più importanti risorse possedute dagli organismi digitali: il tempo di utilizzo della CPU e l'informazione contenuta nel codice genetico, cioè nel linguaggio macchina (Ray, 1991). Uno dei primi adattamenti ecologici scoperti è una forma di parassitismo dell'informazione, in cui un organismo ha ridotto il suo codice della metà, perché ha eliminato il codice necessario alla sua riproduzione eseguendo il corrispondente codice degli organismi vicini. Questi organismi parassiti possono riprodursi circa due volte più velocemente dei loro ospiti perché devono copiare da madre a figlia solo metà dell'informazione. l parassiti, tuttavia, non possono cacciare i loro ospiti dalla memoria, perché dipendono da essi per porzioni essenziali dell'informazione. L'andamento ciclico delle popolazioni dell' ospite e del parassita seguono i modelli di Lotka-Volterra, che prevedono che le abbondanze delle due popolazioni (della preda e del predatore) subiscano delle continue oscillazioni accoppiate.
Inoltre, dato che gli ospiti sono in continua evoluzione, occasionalmente sviluppano meccanismi di immunità che li liberano dai parassiti. Generalmente i parassiti ricompaiono dopo un po' di tempo, e le popolazioni di ospiti e parassiti mostrano un andamento in cui si alternano le condizioni di rispettivo vantaggio, poiché i parassiti superano continuamente le difese degli ospiti mentre gli ospiti sviluppano nuove difese. Siccome il parassitismo dell'informazione coinvolge l'esecuzione di un codice appartenente a un altro organismo digitale, esso crea una vulnerabilità che è stata utilizzata da una nuova classe di adattamenti. Certi ospiti hanno sviluppato mezzi per acquisire il controllo della CPU quando è utilizzata dai parassiti per l'esecuzione di porzioni del loro codice. In pratica riescono a eseguire il loro codice in parallelo sottraendo il controllo della CPU ai parassiti. La presenza di questi 'iper-parassiti' nell'ambiente può causare la rapida eliminazione dei parassiti.
Sono stati osservati algoritrni cooperativi in evoluzione quando un singolo tipo di organismo digitale (per esempio un iper-parassita) domina completamente la memoria. In questi organismi, un individuo singolo isolato non è in grado di riprodursi; ma quando due o più individui dello stesso tipo sono presenti contemporaneamente nella memoria, essi sono in grado di riprodursi attraverso combinazione cooperativa tra due copie dello stesso algoritmo. Tale cooperazione crea una nuova forma di vulnerabilità, e tali aggregazioni cooperative possono essere invase da 'ingannatori' che si inseriscono tra gli individui che cooperano sottraendo loro il controllo della CPU quando questo passa da un individuo all'altro. L'evoluzione degli adattamenti ecologici è un processo tuttora in corso. Sembra che qualsiasi forma di algoritmo domini la memoria diventi un bersaglio per lo sfruttamento (o la difesa) da parte di altri organismi. Quando un organismo dominante diventa il bersaglio di una nuova forma di sfruttamento o di difesa, egli cede il suo dominio all'organismo che possiede la nuova forma di adattamento, e il ciclo ricomincia.
Ottimizzazione
L' ottimizzazione si distingue dall' adattamento ecologico per il fatto che l'innovazione nell'algoritmo individuale non coinvolge interazioni con altri individui. Un tipo di ottimizzazione è la riduzione del numero di istruzioni dell'algoritmo, e il limite di questo processo ha portato a un organismo (non parassita) di ventidue byte. Questo organismo è circa un quarto della grandezza del suo progenitore di ottanta byte, e si riproduce circa sei volte più velocemente. Comunque, l' ottimizzazione non necessariamente porta a un codice più compatto. Alcune ottimizzazioni raggiungono una grande efficienza tramite un codice più complesso. Un esempio è la tecnica dello srotolamento del ciclo. Il programma originario contiene una sequenza di istruzioni che copia un byte alla volta durante la riproduzione da madre a figlia. La copia dell'intero genoma avviene reiterando questa sequenza ottanta volte. Sono stati trovati algoritmi evoluti che copiano due o tre byte per iterazione, aumentando l'efficienza.
L'efficienza può essere calcolata dividendo il numero totale di istruzioni (in linguaggio macchina) eseguite durante il processo di riproduzione per il numero di byte dell'organismo; il risultato è espresso in numero di cicli eseguiti per byte copiato. Per esempio, un progenitore di ottantadue byte esegue 8,39 cicli per byte copiato. Il suo più piccolo discendente ha venti due byte, copia un byte per ogni iterazione, ed esegue al meglio 4,96 cicli per byte copiato. Un discendente un po' più grande di ventisei byte può copiare due byte per iterazione, ed esegue solo 3,73 cicli per byte copiato. Un altro discendente di quarantatré byte, copia tre byte per ogni iterazione, ed esegue solo 3,33 cicli per byte copiato.
Un altro metodo per velocizzare il processo di riproduzione è operare in parallelo. Abbiamo visto come questo accade in modo opportunistico nel caso degli iper-parassiti, i quali acquisiscono il controllo della CPU impegnata dai parassiti, e in questo modo possono produrre più figli contemporaneamente.
Successivamente è stato migliorato il set di istruzioni con l'aggiunta dei comandi "dividi" e "unisci". Essi permettono ai programmi di dividersi in più processi operanti simultaneamente, e riunirsi eventualmente in un processo unico. È stato creato un organismo progenitore in cui il programma iniziale si divide in due processi, subito prima di entrare nel ciclo di riproduzione. Due processori si dividono, quindi, il lavoro di copiare il codice: la prima CPU copia la prima metà del codice, l'altra CPU copia la seconda metà, e al termine del ciclo di riproduzione i due processi si riuniscono. Attraverso l'evoluzione, alcuni programmi hanno accresciuto il loro parallelismo fino a trentadue processori. In un programma di questo tipo non esistono cicli di istruzioni. Ogni processo semplicemente copia due byte. Sono stati trovati organismi divisi in sedici processi con algoritmi di sessanta byte. In questo caso, poiché sessanta non è esattamente divisibile per sedici, la divisione del lavoro è più complicata e la replicazione coinvolge talvolta la copiatura e la sovrapposizione dei dati tra processi diversi.
Confronto tra i diversi sistemi per l'evoluzione sintetica

Abbiamo mostrato il progressivo aumento di capacità dei sistemi per l'evoluzione sintetica, fino alla creazione di sistemi il cui processo evolutivo è molto simile a quello dell' evoluzione organica. In tabella (tab. I) sono messe in relazione tre caratteristiche importanti di questi sistemi.
Evoluzione della struttura genetica
In tutti i sistemi per l'evoluzione sintetica che sono stati esaminati in questo saggio, il codice genetico è in pratica rappresentato da una stringa di informazioni. In alcuni sistemi la composizione di questa stringa è fissata; per questi sistemi c'è uno spazio vuoto in corrispondenza della colonna 'Struttura genetica in evoluzione' presente nella tabella. Per altri sistemi, la composizione della stringa è in grado di evolversi, così che la forma della soluzione rappresentata dalla stringa non è fissata, ma cambia durante l'evoluzione; in questo caso viene posta una X nella colonna Struttura genetica in evoluzione.
Interazione
In alcuni sistemi, i singoli individui in evoluzione sono valutati da una funzione di idoneità non dipendente da essi, e non sono in grado di interagire in alcun modo con gli altri membri della stessa popolazione; per tali sistemi c'è uno spazio vuoto nella colonna Interazione. In altri casi l'idoneità dei singoli individui può essere determinata anche dalle loro interazioni con altri membri della popolazione; per essi c'è una X nella colonna Interazione.
Selezione naturale
In alcuni sistemi, la selezione è determinata da una funzione di idoneità fissata a priori che non cambia durante tutto il corso della simulazione; in questi casi c'è uno spazio vuoto nella colonna Selezione naturale. Nel sistema Immagini genetiche, la selezione è determinata dal senso estetico dell'utente, indicato con la lettera E nella tabella. Nel caso delle creature virtuali di Sims che competono per il possesso di un blocco, la funzione di idoneità esterna è costituita dall'abilità di possedere un blocco. Al tempo stesso, questa abilità dipende in modo complesso dalle interazioni con le altre creature con cui ciascuna compete. In questo caso abbiamo, quindi, una parziale selezione naturale, indicata da una P nella tabella. In pochi sistemi la selezione è completamente naturale, basata solo sulla abilità di sopravvivere e riprodursi, ed è stata indicata da una X nella colonna Selezione naturale.
Evoluzione e linguaggio
Uno studio condotto allo scopo di paragonare i modelli di evoluzione in quattro differenti (ma molto simili) linguaggi macchina (Ray, 1994b) ha dimostrato che due linguaggi su quattro presentano una capacità di evoluzione (misurata come ottimizzazione attraverso la diminuzione delle dimensioni) molto maggiore degli altri. Inoltre, i due linguaggi caratterizzati da livelli di evoluzione relativamente bassi forniscono esempi di evoluzione di tipo molto graduale, mentre gli altri due presentano grosse discontinuità nel processo evolutivo. Di questi ultimi due sistemi, l'uno presenta una evoluzione graduale, l'altro una stasi pressoché totale negli intervalli tra due punti di discontinuità. Secondo la teoria degli equilibri di interpunzione, o degli equilibri intermittenti o punteggiati (punctuated equilibria), formulata agli inizi degli anni Settanta dai paleontologi statunitensi N. Eldredge e S.J. Gould, i cambiamenti evolutivi più rilevanti, punctuations, si verificano durante periodi di speciazione brevi - anche inferiori a 100.000 annie le specie risultanti, dopo essersi affermate e aver proliferato, sostanzialmente non cambiano per milioni di anni e quindi si estinguono.
È evidente che molti aspetti del processo evolutivo dipendono dalla struttura del linguaggio genetico coinvolto. Allo stato attuale, però, non esiste alcuna teoria in grado di mettere in relazione la struttura di un particolare linguaggio con le corrispondenti modalità di evoluzione. Ciò rappresenta una difficoltà della teoria evolutiva che non era evidente fino all'avvento dell' evoluzione sintetica.
Questo aspetto pone un problema serio a molti ingegneri che usano l'evoluzione come strumento per progettare od ottimizzare. In questi casi, si crea un sistema genetico per descrivere lo spazio delle soluzioni e poi si cerca di far evolvere il linguaggio utilizzato. Alcuni di questi linguaggi sono facilmente soggetti a evoluzione, altri no. Tuttavia, non esiste alcuna teoria che guidi la progettazione per aumentare in modo mirato la capacità di evoluzione.
Evoluzione del linguaggio
L'evoluzione organica operante sulla Terra organizza strutture e processi chimico-fisici dal livello molecolare fino al livello degli eco sistemi (coloro che accettano l'ipotesi Gaia devono includervi anche l'intera biosfera). Al di sotto del livello molecolare, e al di sopra del livello degli ecosistemi, l'evoluzione non gioca alcun ruolo. Esistono limiti analoghi nel campo di azione dei sistemi digitali di evoluzione sintetica.
In tutti i sistemi descritti, il limite inferiore è proprio il linguaggio di rappresentazione del sistema nel cui ambito opera l'evoluzione. Negli AG, ogni programma realizzato defrnisce il significato di ciascun gruppo di bit che compongono una stringa (per esempio, i valori dei coefficienti di un'equazione). Nella PG, un linguaggio tipo Lisp contiene un insieme prede finito di espressioni linguistiche primitive, le quali permettono di produrre strutture logiche ad albero creando nodi (per esempio aggiungere, sottrarre, scambiare bit) e foglie (per esempio numeri, costanti, valori interi o reali, generatori di numeri casuali, altre funzioni di rumore). In Tierra il linguaggio consiste in un piccolo insieme di istruzioni in linguaggio macchina.
In che modo l'evoluzione possa operare sul linguaggio di rappresentazione stesso è materia di numerose discussioni. Una realizzazione molto interessante in questo campo è costituita dalle funzioni definite automaticamente (Angeline et al., 1994; Koza 1994). Esse usano espressioni ad albero in linguaggio Lisp, in cui uno speciale operatore genetico può convertire ogni sotto-albero in una espressione primitiva. Questi sotto-alberi sono chiamati moduli, e in pratica sono frammenti di strutture ad albero inalterabili, protette contro le mutazioni. In quanto nuovi elementi dellinguaggio, diventano disponibili come moduli unitari per l'utilizzazione da parte di un operatore di mutazione. Dato che sono protette dalla frammentazione grazie a un operatore di scambio, sono in grado di propagarsi e integrarsi stabilmente all'interno della popolazione.
In questo modo, la rappresentazione del linguaggio è in grado di evolvere con funzioni di livello più alto. Angeline e Pollack osservano che "l'emergere di un modulo utile riduce le dimensioni dei genotipi e, conseguentemente, il numero delle protezioni necessarie e dei punti di mutazione. Ciò fa sì che il processo di evoluzione si concentri nel portare a un livello più elevato di astrazione i programmi in evoluzione, invece che distruggere blocchi già costituiti". Questo tipo di approccio sarà probabilmente sviluppato a fondo in futuro. Mentre le funzioni defrnite automaticamente forniscono uno strumento per l'evoluzione di funzioni di livello più elevato, si discute molto anche il problema opposto, ovvero la definizione di un sistema di rappresentazione a basso livello, in grado di permettere l'evoluzione ottimale del linguaggio utilizzato. Questa idea è stata spesso proposta nell'ambito del dibattito riguardante la possibilità di progettare linguaggi capaci di evolversi (vedi il paragrafo precedente). Ci si può domandare se la selezione naturale possa favorire tale capacità, sempre che sistemi di questo tipo possano essere realizzati. Non si conosce attualmente alcun esempio in cui questa idea sia stata messa in pratica. Anche se costituisce un aspetto interessante da approfondire, rimane dubbia la sua potenziale produttività. Vi è comunque un livello al di sotto del quale l'evoluzione non opera: quello della fisica. Dobbiamo accettare, in ultima analisi, che l'evoluzione è immersa nel mondo fisico e che le leggi fisiche non si evolvono.
Modificare il rapporto con l'evoluzione
Mentre il lavoro con i sistemi di evoluzione artificiale, completamente creati dall'uomo, ha solo due o tre decenni di storia, e la teoria dell'evoluzione ormai comunemente accettata ha avuto origine con Darwin e Wallace nel 1859, l'applicazione della scienza dell'evoluzione risale a diecimila o quindicimila anni prima. Sin dall'origine dell'agricoltura, il controllo sull'evoluzione di altre specie è sempre stato un aspetto fondamentale della condizione umana e ha fornito le basi per la civilizzazione. In quel periodo, gli esseri umani avevano già esplorato tutte le regioni disabitate della Terra e avevano cominciato ad addomesticare piante e animali. Il processo di domesticazione coinvolge anche il controllo dei processi evolutivi delle altre specie. Il genere umano influenza i luoghi dove esse vivono, il numero di individui nelle diverse popolazioni e quali individui debbano riprodursi. Tramite questo processo, abbiamo trasformato i prodotti grezzi dell' evoluzione organica (piante di qualità scarsa e piccoli animali) negli organismi addomesticati di grande qualità che possiamo osservare ancora oggi: riso, mais, frumento, polli, suini, bovini, cani, gatti, ecc. Tramite incroci selezionati (l'applicazione di una funzione di idoneità) tutti questi organismi sono stati fortemente modificati rispetto alla loro condizione originaria. Comunque, questo non è l'unico metodo con cui abbiamo utilizzato il processo di evoluzione naturale. Ci sono molti organismi viventi che usiamo sostanziahnente al loro stato grezzo per derivarne prodotti utili; per esempio, il mogano è usato per il suo legno di alta qualità e gli alligatori per la loro pelle, senza allevamento artificiale. Alcune specie si trovano in una situazione intermedia; per esempio, i bachi da seta e i visoni vengono attualmente allevati, ma sono stati probabilmente soggetti a qualche forma parziale di selezione.
Crescita della complessità
Dunque, gli esseri umani hanno praticamente usato l'evoluzione sin dalla nascita dell'agricoltura. Ma il nostro controllo sull'evoluzione ha avuto luogo a un microlivello, cioè solo al livello dell'alterazione delle specie esistenti. Non siamo mai stati in grado di sfruttare e modificare le proprietà più creative dell'evoluzione: l'origine di nuove specie e la crescita del livello di complessità. Siamo in grado di guidare l'evoluzione del mais grezzo di bassa qualità verso la produzione di mais domestico di alta qualità, ma non possiamo guidare l'evoluzione di un'alga a mais. L'inserimento del processo di evoluzione in sistemi artificiali creati dall'uomo apre un capitolo del tutto nuovo. Il lavoro con i nuovi tipi di evoluzione digitale ci potrebbe permettere di instaurare un nuovo rapporto con l'evoluzione, con cui gestire gli aspetti più creativi del processo evolutivo. Comunque, ciò richiederà nuovi approcci allo studio dell'evoluzione, in quanto questi ambiziosi obiettivi non potranno essere raggiunti mediante l'approccio tradizionale basato sull' allevamento in cattività, ovvero selezionando mediante funzioni di idoneità.
Esempi dalla natura
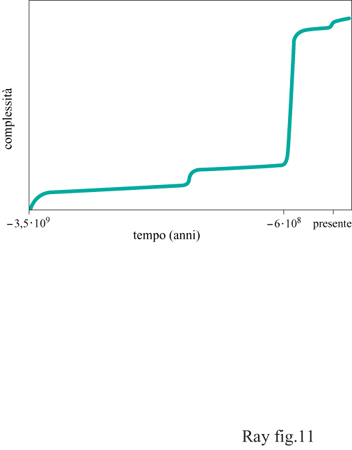
Le principali transizioni evolutive avvenute sulla Terra sono state discusse recentemente (Smith et al., 1995). Esse sembrano presentarsi in modo relativamente inaspettato, rispetto al normale tasso di cambiamento evolutivo. Alcuni dei cambiamenti più importanti sono stati: l'origine dei cromosomi, degli eucarioti, del sesso, degli organismi pluricellulari e, infine, l'origine dei gruppi sociali. Probabilmente il più drammatico e meglio conosciuto fra questi cambiamenti è stato la rapida origine e diversificazione dei grandi organismi pluricellulari a partire da progenitori unicellulari. Tale fenomeno è diventato noto come esplosione cambriana della diversità (fig. 11). Essa è stata comprensibilmente definita il 'big bang' dell'evoluzione, cioè un momento in cui c'è stata una grande crescita di complessità degli organismi e le specie si sono differenziate rapidamente all'interno di un 'vuoto' ecologico (Gould, 1989; Morris, 1989).
Un analogo digitale dell'esplosione cambriana
Dato che l'esplosione evolutiva cambriana ha causato un aumento della complessità degli organismi viventi, è interessante considerare quale potrebbe essere il suo analogo digitale. Al livello fondamentale, l'esplosione cambriana è originata dalla transizione da organismi monocellulari a pluricellulari. L'analogo digitale sarebbe, quindi, la transizione da processi seriali a processi paralleli. Se facessimo un'analogia tra una cellula e un processore, i moderni organismi pluricellulari corrisponderebbero a programmi paralleli che su una ipotetica scala di complessità superebbero di gran lunga ogni programma per elaboratore oggi esistente. Nella vita organica naturale, il programma corrisponde al genoma, basato sulle sequenze di acidi nucleici; negli esseri umani questo programma contiene circa tre miliardi di basi. Ma si deve ricordare che nessuna cellula singola è espressione di tutti i geni del genoma. Infatti, ciascuna cellula esprime un piccolo sottoinsieme di tali geni, e tale insieme definisce il tipo di cellula. Per esempio, a seconda dei geni espressi, si distinguono cellule della pelle, del fegato, del cervello, e così via.
Si pensa che il corpo umano contenga molte migliaia di cellule differenti, per un totale di mille miliardi di cellule. Esso funziona in modo analogo a due dei principali tipi di parallelismi operanti nei programmi per elaboratore: SPMD e MIMD. Nel parallelismo SPMD (Single Program Multiple Data, Singolo programma molti dati) c'è un singolo programma condiviso da tutti i processori, così tutte le CPU eseguono lo stesso codice anche se non necessariamente in modo contemporaneo. Nel parallelismo MIMD (Multiple Instruction Multiple Data, Molte istruzioni molti dati), ciascuna CPU può eseguire un diverso insieme di istruzioni. Il parallelismo SPMD corrisponde grossolanamente a una moltitudine di cellule dello stesso tipo, poiché in entrambi i casi tutti i componenti esprimono le stesse porzioni del codice genetico. Il parallelismo MIMD corrisponde a gruppi distinti di cellule di tipo diverso, che esprimono porzioni diverse del codice genetico. I grandi organismi pluricellulari moderni combinano, su larga scala, entrambi i tipi di parallelismo.
Tuttavia, la maggior parte dei programmi per elaboratore operanti in parallelo sono essenzialmente del tipo SPMD. La ragione è che tale software è molto simile a quello seriale, anche se viene eseguito contemporaneamente su processori diversi, operando di solito su insiemi di dati diversi. Per di più, i programmi MIMD esistenti sono molto più semplici rispetto al genoma degli organismi viventi pluricellulari. Questo tipo di software è estremamente difficile da realizzare. Gli elaboratori MIMD esistenti possono disporre di centinaia o migliaia di processori e, anche se ciascuno è in grado di eseguire un codice differente collaborando a un obiettivo comune, non esiste una metodologia efficace per produrre programmi adeguati. Scrivere programmi che coinvolgano più di pochi processi distinti va oltre le normali capacità dei programmatori. Sappiamo che l'evoluzione naturale basata sulla chimica del carbonio è in grado di generare programmi paralleli che combinano su scala enorme sia il parallelismo SPMD che MIMD. Ma non conosciamo appieno le possibilità dell'evoluzione nell'ambito dei sistemi di calcolo digitale. Gli esperimenti finora condotti hanno mostrato la sorprendente capacità da parte dei sistemi evolutivi di riorganizzare e migliorare il codice stesso.
Mentre l'evoluzione naturale ha prodotto un aumento di molti ordini di grandezza del livello di complessità degli esseri viventi, finora l'evoluzione digitale ha creato solo un piccolo incremento del livello di complessità, forse equivalente a un fattore pari a due o tre. L'evoluzione nel mezzo digitale è in grado di generare spontaneamente un alto livello di complessità? E se sì, sotto quali condizioni? La risposta a queste domande può essere ottenuta solo attraverso l'analisi sperimentale.
Provocare una crescita spontanea della complessità
Attualmente vengono utilizzati approcci diversi per creare condizioni che possano favorire l'evoluzione digitale e generare un sempre maggiore livello di complessità. Personalmente, sto lavorando a ciò che è chiamato una riserva di biodiversità per gli organismi digitali. Essa sarà basata su una versione in rete del programma Tierra, in cui si cercherà di far in modo che migliaia di persone eseguano il programma Tierra sui loro elaboratori collegati in rete; tutti gli elaboratori partecipanti saranno connessi in una sottorete virtuale nell'ambito di Internet. All'interno di questa sottorete, gli organismi digitali saranno in grado di spostarsi liberamente da un elaboratore all'altro.
I vantaggi di un ambiente in rete
Questo sistema offre due vantaggi rispetto alla versione di Tierra eseguita su un solo elaboratore: uno spazio maggiore e una maggiore diversità di risorse spaziali e temporali. Per gli organismi digitali ci sarà un grande incremento della disponibilità di spazio e di tempo-macchina (numero di cicli delle CPU). La versione con un solo elaboratore generalmente funziona con uno spazio di memoria di 100 o 200 kbyte, mentre un singolo organismo digitale complesso potrebbe superare queste dimensioni.
Si ritiene che solo nell'ambito di una comunità ecologica di organismi l'evoluzione possa in realtà compiere grandi passi, e che le interazioni tra diverse forme di vita forniscano una forza guida dei processi evolutivi. Quindi, dovremo ricorrere a un grande spazio che possa contenere intere popolazioni di molte specie di organismi complessi. Supponiamo di voler creare almeno un centinaio di specie, ciascuna con una popolazione di cinquecento individui, grandi circa diecimila byte ciascuno; ciò richiederebbe una memoria di cinquecento milioni di byte. Realizzando questo spazio su di un singolo elaboratore si otterrebbe un pessimo rapporto tra memoria occupata e potenza della CPU, mentre distribuendo la memoria su molti elaboratori si otterrebbe un rapporto di gran lunga migliore. Condizione necessaria, ma probabilmente non sufficiente, per ottenere una maggiore complessità è disporre di un maggiore spazio di memoria. Da questo punto di vista, il modello distribuito fornisce una grande varietà di tipi di risorse spaziali e temporali; si ritiene che questa complessità possa produrre una pressione selettiva sul processo evolutivo tale da permettere lo sviluppo di adattamenti complessi ai diversi ambienti. La versione in rete del programma Tierra sarà un processo a bassa priorità, come un programma salva-schermo, cioè come un programma che occupa la CPU solo quando l' elaboratore non è impegnato direttamente dall 'utente e che vivacizza lo schermo con disegni, immagini variabili, ecc. Quando l'utente usa direttamente l' elaboratore, il programma è in stato di pausa, senza richiedere tempo-macchina e risorse energetiche per le attività degli organismi digitali. In queste condizioni essi sono 'congelati', avendo inibito il proprio metabolismo e la propria riproduzione. Ciò dovrebbe creare una forte spinta selettiva tendente a far spostare gli organismi all'interno della rete, evitando i programmi di evoluzione in stato di pausa e cercando quelli in esecuzione con grandi risorse di CPU disponibili. L'evoluzione potrebbe generare comportamenti diversi a seconda delle diverse fasce orarie di massima disponibilità di tempomacchina. Per esempio, dovrebbe probabilmente svilupparsi un ciclo giornaliero, in modo che l'attività sia maggiore durante la notte, quando l'attività diretta degli utenti sull'elaboratore è scarsa. Alcuni organismi digitali potrebbero sviluppare il comportamento di migrare quotidianamente attorno al pianeta, per cercare aree di inattività notturna.
Vi potrebbero essere molte eccezioni a questi esempi (ci sono appassionati che lavorano fino a tardi e ricercatori che eseguono simulazioni numeriche complesse durante la notte). Quindi la selezione favorirebbe la capacità di sondare in ciascun momento le condizioni della rete e muoversi di conseguenza. In generale l'evoluzione favorirebbe la capacità di muoversi 'intelligentemente' nella rete, alla ricerca di tempo-macchina e risorse di sistema disponibili. Gli organismi digitali dovrebbero, quindi, diventare agili agenti autonomi della rete.
Evoluzione autocatalizzata
Si ritiene che la maggiore complessità e la dinamica dall'ambiente di rete sollecitino l'evoluzione con problemi più complessi rispetto alla semplice copia di stringhe eseguita su un singolo elaboratore. Ciò dovrebbe fornire una spinta selettiva per stimolare l'aumento iniziale del livello di complessità. Successivamente, le forze selettive nate dall'interazione fra gli organismi digitali dovrebbero determinare una crescita autocatalizzata della complessità. Si pensa che questo tipo di eventi si sia verificato nel caso dell'evoluzione organica. In Amazzonia ci sono foreste pluviali su terra sabbiosa, in cui l'ambiente fisico è costituito di sabbia bianca, aria, pioggia e luce solare. Immerso in questo ambiente c'è il più complesso ecosistema della Terra, la foresta tropicale pluviale. In questo eco sistema vivono centinaia di migliaia di specie, le quali non rappresentano centinaia di migliaia di adattamenti indipendenti all'ambiente fisico, ma sono, piuttosto, il risultato di reciproci adattamenti tra organismi viventi che interagiscono tra loro. La vita modifica l'ambiente dimodoché la componente vivente dell'ambiente arriva a predominare sull'ambiente fisico. In questo modo la complessità degli organismi viventi arriva a superare di gran lunga la complessità dell'ambiente fisico in cui essi vivono. Il tipo di evoluzione prodotta nell' ambito del programma Tierra dipende proprio dalle interazioni ecologiche, che sono basate sull' adattamento alla presenza di altri organismi digitali che vivono nello stesso ambiente. Si spera che stimolando l'aumento iniziale della complessità, la dinamica ecologica del sistema possa guidare il processo evolutivo verso livelli di complessità sempre più elevati. Ritornando al caso del programma Tierra realizzato in rete, se si utilizza un singolo algoritmo di rete, che analizza le condizioni ambientali, può accadere che inizialmente esso sia usato da tutti gli organismi digitali e che tutti prendano la stessa decisione, tentando di spostarsi nella stessa area di rete: ciò causerebbe la sovrappopolazione del luogo scelto rendendo lo non più appetibile. Gli organismi digitali dovrebbero, per questo motivo, sviluppare strategie diverse per distribuirsi in modo razionale nella rete. In pratica, ciò richiederebbe l'evoluzione di una sorta di comportamento sociale, che alla fine darebbe origine al raggrupparsi di individui o a comportamenti di repulsione reciproca. Tuttavia, il problema della distribuzione sulla rete potrebbe essere risolto in modo migliore usando una varietà di strategie diverse, invece che una sola, anche se selettivamente efficace.
Gestire l'evoluzione dell'aumento della complessità
Si potrebbe usare l'evoluzione digitale per ottenere prodotti utili? Anche se abbiamo un'ottima esperienza con la selezione di piante e animali, il nostro rapporto con l'evoluzione digitale è molto diverso. I nostri pro genitori sono stati in grado di osservare molti organismi naturali complessi ed evoluti. Essi trovarono utili alcuni di questi: per esempio le specie selvatiche antenate del riso, del grano, del frumento, del pollo, del maiale, del cane, ecc.; quindi li selezionarono fino a produrre le piante e gli animali domestici che conosciamo oggi. Nel caso dell'evoluzione digitale, siamo partiti con organismi molto semplici che non hanno ancora raggiunto un livello tale di complessità da renderli utili; questo rimane il nostro principale obiettivo, ma ancora non abbiamo l'esperienza necessaria per gestire l'evoluzione della complessità. Probabilmente ogni tentativo di guidare l'evoluzione diretta delle alghe fino al frumento, nell'ambito di un programma di allevamento che faccia uso di selezione artificiale, non realizzerebbe una tale trasformazione. Credo che non saremo mai in grado di guidare l'evoluzione usando la selezione artificiale. Per favorire l'aumento del livello di complessità necessitiamo di un approccio nuovo e diverso. La nostra incapacità di gestire quest'aspetto dell'evoluzione è dovuta a due limitazioni: la nostra incapacità di prevedere gli sviluppi futuri e quella di fornire adeguate spinte selettive.
I limiti dell'immaginazione
Di solito pensiamo che la nostra immaginazione sia senza limiti, ma, in pratica, essa è appesantita da molti preconcetti e limitata alla conoscenza acquisita a partire da essi. Come esercizio mentale, immaginiamo di trovarci in un ambiente ricco di microrganismi, all'inizio dell' esplosione evolutiva cambriana. I soli esempi di vita conosciuti sono i batteri, le alghe, i protozoi e i virus. Senza una precedente esperienza della complessa vita pluricellulare, probabilmente non potremmo immaginare le forme di vita in procinto di comparire. Così, non potremmo prevedere le applicazioni che gli uomini sarebbero stati in grado di derivare dall'evoluzione organica: riso, mais, frumento, polli, suini, bovini, seta, cotone, mogano, visoni, gatti, cani, ecc. A mio avviso, noi abbiamo lo stesso tipo di rapporto nei confronti dei processi dell' informazione e dell' evoluzione digitale. Infatti, anche il più complesso dei nostri programmi (per esempio un sistema operativo) può essere paragonato, per complessità, soltanto a un'alga monocellulare o a un protozoo. Non abbiamo esperienza e non possiamo neanche immaginare le varie strutture dei futuri programmi, complessi, multi-processo, paralleli e distribuiti.
Abbandonare il test di Turing
Si potrebbe obiettare che, avendo esperienza di come l'informazione viene processata dal cervello umano, dovremmo sapere cosa cercare. Per esempio, vogliamo dei programmi 'intelligenti' o qualcosa che possa mostrare un'intelligenza simile a quella umana. Ma ciò rivela il limite dei nostri preconcetti, dovuti a un'esperienza limitata alla vita organica. Il test di Turing esemplifica questo problema. Si tratta di un metodo proposto da A. Turing per capire se una macchina è diventata intelligente. Tale test si basa sulla comunicazione, tramite terminale, con altri esseri umani oppure con altre macchine. Quando un utilizzatore non è in grado di distinguere se l'interlocutore è l'uomo o la macchina, allora dobbiamo considerare la macchina intelligente.
I metodi tipo il test di Turing sono sempre considerati come sufficienti, non come necessari. Personalmente li considero del tutto inadeguati, perché hanno la tendenza a orientare la discussione e la ricerca verso false piste. Penso sia ridicolo pensare che una macchina intelligente possa essere del tutto indistinguibile da un uomo (in teoria il test di Turing dovrebbe essere in grado anche di distinguere esseri umani con una diversa formazione culturale). Ritengo che una forma di vera intelligenza artificiale dovrebbe risultare fondamentalmente diversa dall'intelligenza umana (o in generale organica) più di quanto non lo sarebbe un'entità intelligente proveniente da un altro pianeta, perché anche quest'ultima trarrebbe probabilmente origine dalla chimica del carbonio, al contrario di un'entità dotata di intelligenza artificiale. Si immagini un'intelligenza artificiale che viva nell'ambiente di Internet. Per una tale intelligenza sarebbe probabilmente stimolante leggere terabyte di dati distribuiti globalmente sulla rete ed elaborarli come processo distribuito in pochi minuti anche se riguardassero un qualche problema noioso. Essa potrebbe eseguire con una velocità prodigiosa calcoli numerici estremamente complessi e processare un enorme quantità di informazioni. Potrebbe spostarsi fisicamente in ogni punto della superficie della Terra nell'arco di millisecondi, distribuendo si eventualmente su tutto l'ambiente disponibile. Per tale creatura il flusso di informazioni costituirebbe un'esperienza sensoriale diretta e non qualcosa che accade all'interno di uno strumento a lei estraneo che processa dati. Tale creatura vivrebbe in un universo di informazioni digitali e non nel nostro mondo materiale. l suoi piaceri e le sue sofferenze sarebbero per noi qualcosa di completamente estraneo. Non la scambieremmo mai per qualcosa di umano. Dobbiamo perciò dimenticare il test di Turing!
Il peso dei preconcetti
Possiamo valutare quanto l'uso del mezzo digitale sia limitato dai nostri preconcetti osservando come nelle rappresentazioni di mondi virtuali, il cyberspazio è reso il più possibile simile al mondo euclideo tridimensionale. È come se volessimo trasferire la nostra realtà fisica nell'ambiente virtuale, mentre esso dovrebbe essere elaborato a livello mentale senza mantenere necessariamente le limitazioni che ci sono familiari nel mondo reale. In un tipico mondo virtuale, ci muoviamo lungo una strada delimitata da edifici. Ci avviciniamo a un edificio e selezioniamo la porta con il mouse. Tale approccio ha il merito di essere semplice e, inoltre, necessita solo di un minimo apprendimento per acquisire familiarità con l'ambiente. Ciò ricorda i primi film, in cui la cinepresa era usata soltanto per riprendere, per esempio, opere teatrali senza comprendere appieno la potenza del mezzo cinematografico. Lo stesso accade oggi con l'uso del mezzo digitale.
L'evoluzione digitale è un modo per esplorarne le proprietà, senza basare la nostra esplorazione su concetti precostituiti, o limitarla a causa della nostra incapacità di immaginare la forma futura dei processi di informazione digitale complessi.
L'evoluzione sperimentale
Credo che il modo più naturale per ottenere una crescita del livello di complessità nell'evoluzione digitale consista nel realizzare il processo evolutivo tramite selezione naturale nell'ambito di una comunità ecologica. Nessun tentativo dovrebbe essere fatto utilizzando funzioni di idoneità (cioè la selezione artificiale) per guidare lo sviluppo evolutivo verso eventuali prodotti utili. Anzi, l'evoluzione dovrebbe essere libera di esplorare ogni possibilità, senza il vincolo della 'guida' umana. Tradizionalmente abbiamo gestito l'evoluzione tramite l'alterazione delle spinte selettive. Nel nuovo approccio all'evoluzione digitale il nostro ruolo è quello di creare le condizioni per una crescita della complessità, piuttosto che tentare di guidarla tramite la selezione artificiale. Si tratta di una sfida dal punto di vista scientifico, in quanto le condizioni in grado di produrre una crescita della complessità sono attualmente sconosciute. Per tentare un approccio sperimentale a questo problema, si potrebbero realizzare e valutare sistemi diversi e, nel caso qualcuno di questi avesse successo, potremmo modificare i diversi parametri sperimentali fino a determinare le condizioni ottimali per generare la crescita voluta.
Precedentemente ho discusso alcune idee su come manipolare l'ambiente per favorire la crescita della complessità (la riserva di biodiversità nel caso degli organismi digitali su Internet). Ma ci sono molti altri aspetti della progettazione del sistema evolutivo che possono essere controllati. Uno dei più importanti è la progettazione del codice genetico su cui si basa l'evoluzione. Oltre alla progettazione dell'ambiente, e del sistema genetico stesso, ci sono altre caratteristiche del sistema che possiamo controllare. Per esempio, possiamo progettare meccanismi per facilitare la regolazione dei geni negli organismi digitali pluricellulari. Inoltre, possiamo progettare dei sistemi per facilitare una sessualità organizzata, paragonabile a quella della vita organica, che permetta il fenomeno della formazione delle specie. La progettazione e l'introduzione di questi elementi costituiscono il ruolo che noi possiamo svolgere nella 'gestione' dell'evoluzione digitale; un ruolo diverso da quello tradizionalmente svolto attraverso il controllo delle spinte selettive.
Questo procedimento, tendente a generare una crescita evolutiva della complessità, costituisce un approccio sperimentale allo studio dell'evoluzione. Se questi sforzi avranno successo, i risultati empirici degli esperimenti potranno permettere lo sviluppo di nuovi supporti teorici alla biologia evolutiva.
Torniamo sui nostri passi
Se riuscissimo a produrre l'analogo digitale dell'esplosione evolutiva del Cambriano, dovrebbe essere possibile stabilire con l'evoluzione digitale lo stesso tipo di relazione che abbiamo con l'evoluzione organica e osservare nell'ambiente digitale i complessi prodotti dell'evoluzione. Anche se molti organismi non avessero alcuna applicazione, è probabile che qualcuno sarebbe utilizzabile. Potremmo osservarli per individuare processi interessanti e utili per la gestione delle informazioni. Una volta identificati gli organismi potenzialmente utili, potremmo 'catturarli' e sottoporli ad allevamento per aumentare le loro capacità applicative e inibire eventuali comportamenti pericolosi. Potremmo modificarli geneticamente inserendo un codice scritto appositamente, o un codice trasferito da altri esseri digitali, oppure modificando opportunamente alcune porzioni del codice. Si potrebbe impedire loro di riprodursi ed, eventualmente, venderli a un'utenza finale.
Abbiamo ben chiaro l'enorme potenziale creativo dell'evoluzione naturale operante nell'ambito dell'ambiente organico, ma non conosciamo ancora il reale potenziale dell'evoluzione nell'ambiente digitale. Tuttavia, gli esperimenti iniziali sono stati molto promettenti, e hanno suggerito l'utilità di proseguire nei tentativi di migliorare questi processi evolutivi. Se anche l'evoluzione digitale possedesse solo una piccola porzione del potenziale evolutivo dell' evoluzione organica, potrebbe fornire nuovi sistemi di gestione dell'informazione, sistemi di una complessità maggiore di quelli che ora conosciamo. Lungo questa strada ci sono molti ostacoli potenziali e problemi tecnici, ma i risultati possibili sono tali che vale la pena di correre il rischio. Dobbiamo, tuttavia, avventurarci in un territorio sconosciuto senza poter stimare anticipatamente le reali probabilità di successo.
Bibliografia citata
ANGELI NE, P.l, POLLACK, lB. (1994) Coevolving high-Ievel representations. In Artificial life III, a c. di Langton C.G., Santa Fe Institute Studies in the Sciences of Complexity, 17, 55-71.
BELEW, R.K., BOOKER, L.B., a c. di, (1991) Proceedings of the 1991 international conference on genetic algorithms, San Mateo, CA, Morgan Kaufmann.
GOLDBERG, D.E. (1989) Genetic algorithms in search, optimization, and machine learning. Reading, MA, Addison-Wesley. GOULD, S.I. (1989) Wonderful life. W.W. Norton & Company, Inc. HILLIS, D.W. (1991) Co-evolving parasites improve simulated evolution as an optimization procedure. In Artificial life II.
HOLLAND, J.H. (1975) Adaptation in natural and artificial systems: an introductory analysis with applications to biology, control, and artificial intelligence. Ann Arbor, University of Michigan Press.
HONG, J.I., FENG, Q., ROTELLO, V., REBEK, J. (1992) Competition, cooperation, and mutation: improving a synthetic replicator by light irradiation. Science, 255, 848-850.
JOYCE, G.F. (1992) Directed molecular evolution. Scientific American, dicembre, 48-55.
KOZA, lR. (1992) Genetic programming, on the programming of computers by means of natural selection. Cambridge, MA, MIT Press.
KOZA, J.R. (1994) Genetic programming Il, automatic discovery of reusable programs. Cambridge, MA, MIT Press.
LANGTON, G.C., TAYLOR, C., FARMER, J.D., RASMUSSEN, S., a C. di, Santa Fe Institute Studies in the Sciences of Complexity, 10, 313-324.
MORRIS, S.c. (1989) Burgess shale fannas and the Cambrian explosion. Science, 246, 339-346.
RAY, T.S. (1991) An approach to the synthesis of life. In Artificial life II, a C. di Langton G.C., Taylor C., Farmer J.D., Rasmussen S., Santa Fe Institute Studies in the Sciences of Complexity, 10, 371-408.
RAY, T.S. (1994) An evolutionary approach to synthetic biology: Zen and the art of creating life. Artificial life 1, 195-226 (ristampato in C.G. Langton, a C. di, 1995, Artificial life, an overview. Cambridge, MA, MIT Press).
RAY, T.S. (1994) Evolution, complexity, entropy and artificial reality. Physica D, 75, 239-263.
RAY, T.S. (1996) Evolution of parallel processes in organic and digital media. In Natural and artificial parallel computation, a C. di Waltz D., Philadelphia, SIAM Press, pp.69-91.
SANCHEZ, E., TOMASSINI, M., a C. di, (1996) Towards evolvable hardware. Lecture notes in computer science, vol. 1062, Berlin, Springer-Verlag.
SIMS, K. (1991) Artificial evolution for computer graphics. Computer graphics, 25, 319-328.
SIMS, K. (1993) Interactive evolution of equations for procedural models. The visual computer, 9, 466-476.
SIMS, K. (1994) Evolving virtual creatures. Computer graphics, Siggraph '94-Annual Conference Proceedings, luglio, 15-22.
SIMS, K. (1994) Evolving 3D morphology and behavior by competition. In Artificial life IV proceedings, a C. di Brooks R., Maes P., Cambridge, MA, MIT Press, pp. 28-39.
SMITH J.M., SZATHMA'RY, E. (1995) The major transitions in evolution. Oxford, Freeman.
YAEGER, L. (1994) Computational genetics, physiology, metabolism, neural systems, learning, vision, and behavior or PolyWorld: life in a new context. In Artificial life III, a C. di Langton C.G., Santa Fe Institute Studies in the Sciences of Complexity, Proc., 17, 263-298.
Bibliografia generale
LANGTON, C.G., a C. di, Artificial life. Redwood City, CA, Addison-Wesley, 1989.
LANGTON, C.G., TAYLOR, C., FARMER, J.D., RASMUSSEN, S., a c. di, Artificial life II. Redwood City, CA, Addison-Wesley, 1992.
LANGTON, C.G., a c. di, Artificial life III. Redwood City, CA, Addison-Wesley, 1994.
LANGTON, C.G., a C. di, Artificial life, an overview. Cambridge, MA, MIT Press, 1995.
LEVY, S. Artificial life, the quest Jor a new creation. New York, Pantheon Books, 199