
dati, struttura di
dati, struttura di
dati, struttura di modalità di organizzazione delle informazioni all’interno di un insieme di dati. Un tipico esempio elementare di struttura di dati è costituito da un dizionario, per le traduzioni da una prima lingua a una seconda, che contiene, come dati, i lemmi della prima lingua e i corrispondenti di ciascuno di essi nella seconda. L’utilizzabilità del dizionario risiede nella sua organizzazione alfabetica; esso diviene fonte di informazione quando è definita una relazione (in questo caso l'ordinamento alfabetico) all’interno del suo insieme di dati. È tale struttura a permettere la consultazione in modo efficiente: la ricerca in esso di un vocabolo sarebbe risolubile anche senza tale ordinamento perché l’appartenenza di un elemento a un dato insieme finito è un problema sempre decidibile; tuttavia l’ordinamento aumenta l’efficienza e determina la diminuzione dei passi di calcolo da compiere e, quindi, riduce la complessità dell’algoritmo di risoluzione.
Una relazione definita all’interno di un insieme è rappresentabile con un grafo, in cui i nodi rappresentano gli elementi dell’insieme e gli archi collegano gli elementi tra loro in relazione. I grafi possono quindi essere considerati come i modelli più generali per rappresentare strutture informative. La relazione più semplice che è possibile definire in un insieme consiste nell’ordinare tutti i suoi elementi: è una relazione di ordinamento totale (o lineare), in cui dati due qualsiasi elementi dell’insieme è sempre possibile stabilire quale di essi preceda l’altro nell’ordinamento stabilito. L’ordinamento naturale in R o l’ordinamento alfabetico nell’insieme delle parole di un linguaggio sono esempi di ordinamento totale. Un insieme strutturato di dati totalmente ordinati è detto lista e può schematicamente essere rappresentato con una sequenza di informazioni, etichettate con A, B, ..., F:
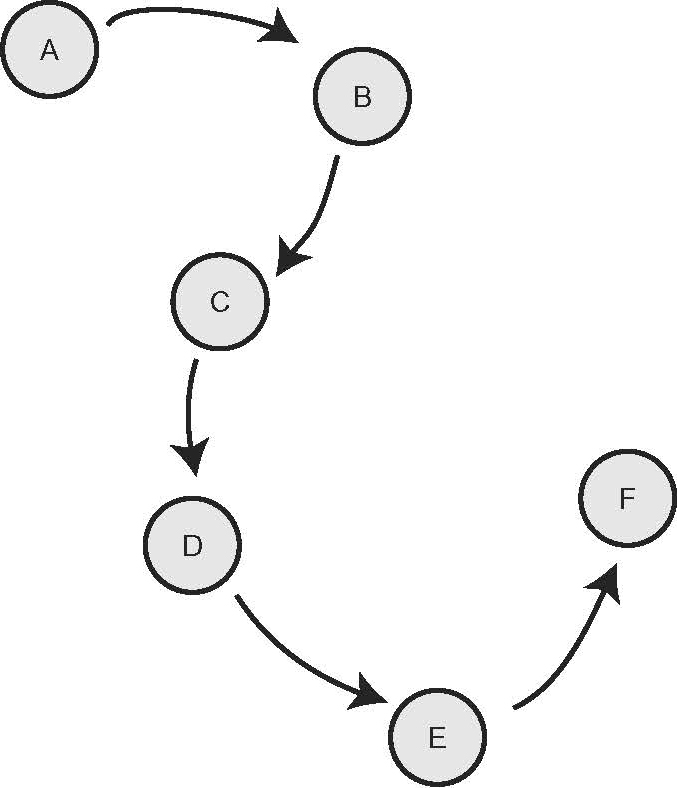
Se si suppone che i dati contenuti in A, B, C, ... siano numeri interi e si vuole rappresentare la struttura di questi dati, si deve utilizzare un tipo di dato che incorpori due informazioni: 1) il numero contenuto: qual è il nodo del grafo che si considera; 2) il dato successivo nell’ordinamento: a quale nodo punta l’arco del grafo.
L’implementazione di questo tipo di dato si effettua utilizzando puntatori, cioè celle di memoria che contengono l’indirizzo del successivo nodo del grafo. Un file in cui sia stato memorizzato un programma è una struttura lineare, così come un brano musicale registrato su un nastro magnetico. Ma tra il modo in cui è registrato il file su un supporto di memoria e il modo in cui è registrato un brano musicale sul nastro vi è una differenza essenziale. Sul nastro i diversi brani si susseguono sequenzialmente anche da un punto di vista fisico. Quando invece è memorizzato un file, esso è generalmente registrato in parti collocate in differenti posizioni di memoria; spetta agli appositi puntatori la ricostruzione complessiva del file.
Le strutture più semplici da realizzare sono le strutture lineari in quanto le operazioni di inserzione, modifica e cancellazione dei dati sono ammesse soltanto all’inizio e alla fine della lista. Due, in particolare, sono quelle che rivestono maggiore importanza:
• la coda: è una struttura lineare in cui si può aggiungere (scrivere) un elemento solo in coda e si può togliere (leggere) un elemento solo in testa:
Una coda simula la situazione tipica di persone in coda, o in fila, davanti allo sportello di un ufficio: il primo a entrare è anche il primo a uscire e perciò questa modalità di lettura-scrittura dei dati in una coda si chiama anche fifo (dall’inglese first in-fìrst out);
• la pila: è una struttura lineare in cui si può aggiungere o togliere un elemento solo dalla stessa estremità:
Una pila simula la situazione di un insieme di persone che siano salite in un ascensore dalla porta stretta: l’ultimo a entrare è anche costretto a uscire per primo, per cui tale modalità è anche chiamata lifo (last in-fìrst out).
Tra le liste, la pila è la struttura più semplice in quanto vi è un solo punto di accesso: è questo il modo in cui le variabili sono assegnate alle celle di memoria di un elaboratore. La parte di memoria direttamente gestita dal sistema operativo (quella dove le variabili sono allocate staticamente) ha una struttura a pila ed è perciò anche detta stack (termine inglese per «pila»). La parte di memoria dove le variabili sono allocate dinamicamente non ha invece una struttura lineare, poiché la sua organizzazione è realizzata dal programma attraverso i puntatori; per questo è detta heap (che significa «mucchio» e rimanda all’idea di un insieme di celle di memoria non ancora organizzate; è appunto il programma a organizzarle puntando successivamente a una o a un’altra).