
trascrizione fonetica
trascrizione fonetica
Definizione
S’intende con trascrizione fonetica un sistema di rappresentazione grafica dei foni di una lingua (➔ fonetica) realizzata attraverso specifici alfabeti (➔ alfabeto fonetico), elaborati appositamente, solo in parte coincidenti con i simboli della scrittura corrente, utilizzati prevalentemente in seno alle scienze linguistiche.
Grafemi e fonemi
Essendo le lingue sistemi di comunicazione orale, una parte di esse ha sviluppato nel tempo una forma di scrittura. I sistemi di scrittura alfabetica, idealmente i più vicini a rendere i suoni di una lingua, si prestano solo parzialmente e in modo approssimativo a tale scopo. I simboli dell’alfabeto, denominati ➔ grafemi (indicati di solito, come in quest’opera, fra parentesi uncinate: per es., ‹a›), non equivalgono per numero ai suoni presenti in una lingua, cioè ai fonemi, causando inevitabili contrazioni e sovrapposizioni di segni. Inoltre, il valore fonetico dei grafemi è destinato a modificarsi nel tempo, per effetto di molteplici fattori. Inventario grafematico e inventario dei foni difficilmente sono in corrispondenza diretta. La scrittura è infatti un codice secondario conservativo, che non registra, o lo fa solo con estrema lentezza, le evoluzioni fonetiche a cui va incontro la pronuncia di una lingua nel corso degli anni.
Per questo motivo, più fonemi possono essere resi da uno stesso grafema o, viceversa, più grafemi possono identificare lo stesso suono. Questa situazione non è esclusiva delle lingue contemporanee dotate di tradizione scritta, ma si apprezza in tutto il percorso storico-evolutivo di una lingua, sebbene in misura progressivamente minore. In alcune lingue, le divergenze sono notevolissime: ad es., la pronuncia dell’inglese contemporaneo non traspare quasi mai dalla grafia, anche se tale distanza era molto meno rilevante in passato. In italiano, come anche in spagnolo, il grado di corrispondenza tra i due livelli (grafematico e fonematico), per una serie di concause storiche, è invece decisamente più alto (➔ lingue romanze e italiano): i grafemi del nostro alfabeto che hanno valore univoco sono infatti undici, anche se le incongruenze non mancano.
Per secoli, fino circa alla metà del Seicento, ‹v›, suono assente in latino, ha rappresentato sia /u/ che /w/ (la differenza nella grafia fra ‹v› e ‹u› si affermò infatti solo nella metà del Settecento), mentre ‹ti› seguito da vocale valeva [ʦi]: basti menzionare la grafia antica di parole come iustitia «giustizia» e gratia «grazia» (➔ Trissino). Nell’italiano di oggi, entrambi i fonemi /g/ e /ʤ/, rispettivamente occlusiva velare sonora e affricata alveopalatale sonora, sono riflessi nella scrittura dal grafema ‹g›: mago e magia; per contro, i due diversi segni grafici ‹g› e ‹gh› equivalgono al fonema /g/: lago e laghi. Incongruenze di questo tipo si rilevano in italiano anche per ‹c›, ‹e›, ‹o›, ‹s› e ‹z›, per questo definiti grafemi polivalenti. D’altra parte, è sufficiente spostare il raggio d’osservazione oltre l’italiano per accorgerci che molte ambiguità si ravvisano anche in tutte quelle lingue neolatine che hanno adottato l’alfabeto romano, un codice di scrittura inizialmente forgiato sui suoni della sola lingua latina (➔ ortografia).
La trascrizione fonetica
La trascrizione fonetica risolve queste contraddizioni presentandosi come l’unica forma di scrittura non ambigua in cui tra segni grafici e suoni sussiste perfetta biunivocità. La trascrizione fonetica ha validità universale, poiché può essere applicata, con pari efficacia, in tutte le lingue; inoltre è una rappresentazione economica, priva di ridondanza.
Non sorprende pertanto che forme di decodifica fonetica siano state costantemente impiegate, con intento descrittivo, nell’interpretazione e nello studio di fenomeni linguistici, in diacronia come in sincronia, o in campo dialettologico. La trascrizione fonetica si è presto rivelata indispensabile anche per rappresentare i suoni delle lingue che non sono mai state scritte o di quelle che usano altri sistemi di scrittura.
Con un intento meramente prescrittivo, la trascrizione fonetica trova la sua massima espressione invece in ambito didattico: si pensi ai vantaggi che derivano dal suo impiego nell’insegnamento delle lingue straniere o alla sua utilità nei dizionari. L’uso della trascrizione fonetica travalica inoltre il settore propriamente linguistico: la sua applicazione si è dimostrata vantaggiosa anche nel settore tecnologico, ad es. per affinare le sempre più sofisticate interazioni verbali uomo-macchina, o nel settore medico, nella diagnosi come nella riabilitazione delle persone con disturbi primari o secondari del linguaggio.
I sistemi di trascrizione fonetica
La trascrizione fonetica si avvale di alfabeti appositamente elaborati, il cui uso necessita di caratteri tipografici specifici, i cosiddetti font fonetici. Per compensare l’inadeguatezza dei sistemi di scrittura, essi comprendono, oltre ai simboli dell’alfabeto romano, anche lettere inventate e svariati segni diacritici (trattini, apici, apostrofi, ecc.).
Il più noto strumento di trascrizione è l’Alfabeto Fonetico Internazionale, comunemente denominato IPA (sigla dell’espressione inglese International Phonetic Alphabet; ➔ alfabeto fonetico). Elaborato in Francia nel 1886 per finalità didattiche, rappresenta oggi l’unico sistema di trascrizione fonetica che può vantare un’elevata adeguatezza descrittiva insieme a un’applicazione universale. È periodicamente aggiornato e affiancato dalla pubblicazione di un periodico ufficiale (il «Journal of the International Phonetic Association», in sigla JIPA).
La trascrizione fonetica secondo i principi codificati dall’IPA segue norme diverse da quelle presenti nelle scritture correnti, una caratteristica quest’ultima dettata dall’esigenza di differenziare l’ortografia comune dalla trasposizione fonica. La trascrizione fonetica è sempre racchiusa tra parentesi quadre, l’accento lessicale precede la sillaba accentata (telefono [teˈleːfono]), l’indicazione della lunghezza di un fono è affidata al diacritico [ː] (rosso [ˈrosːo]). La trascrizione non rende le lettere maiuscole a inizio frase o nei nomi propri, non prevede l’inserimento di spazi tra parole, sebbene siano previsti dei simboli per indicare pause maggiori (∥) o minori (∣). I simboli dell’IPA sono ripartiti in Tavole, per la precisione: Vocali, Consonanti polmonari, Consonanti non polmonari, Soprasegmentali, Toni e accenti di parola, Altri simboli, Diacritici (cfr. Pullum & Ladusaw 19962).
Trascrizione fonetica larga e stretta
I documenti programmatici e teorici dell’IPA (fra tutti citiamo lo Handbook of the International Phonetic Alphabet Association 1999: 28-30) distinguono due forme di rappresentazione, rispettivamente identificate come trascrizione fonetica larga (ingl. broad transcription) e trascrizione fonetica stretta (ingl. narrow transcription).
La prima è contrassegnata da una forma grafica semplificata, e il numero dei diacritici impiegati è minimo, poiché risponde a precipue esigenze pratiche; la trascrizione larga è di solito usata in campo linguistico, non solo specificamente fonetico, ad es. nei dizionari, nei lessici, nelle grammatiche o nei manuali di pronuncia.
La trascrizione stretta, per contro, ha lo scopo di evidenziare l’esatta modalità articolatoria con cui è stata prodotta una sequenza fonica. È usata in ambito squisitamente fonetico e fonologico, ad es. nella descrizione di varietà dialettali o substandard, nell’analisi di tratti sociofonetici, ecc. La rappresentazione stretta è corredata da simboli diacritici, i quali modificano la natura articolatoria del simbolo base, e richiede alte competenze di fonetica strumentale per l’interpretazione dei dati spettro-acustici o articolatori, insieme a un’elevata capacità di discriminazione uditiva. Ad es., la trascrizione larga del lessema invito è [inˈvito], mentre quella stretta è [iɱˈviːto], con l’indicazione dell’allofono labiodentale (➔ allofoni) e della lunghezza della vocale tonica (➔ quantità fonologica).
Nella fonologia postlessicale, vale a dire in un dominio di osservazione più ampio del singolo segmento, la trascrizione stretta rende anche l’insieme dei fenomeni di coarticolazione che si verificano all’interno del flusso verbale continuo, come pure la distribuzione delle prominenze accentuali: ad es., i bambini sono in casa [ibamˈbiːnisoniŋˈkaːsa].
Le due forme di trascrizione non devono essere intese come contrapposte, il loro uso è direttamente vincolato alle finalità che si intendono perseguire: entrambe condividono il medesimo alfabeto fonetico come pure i principi dell’IPA, sebbene il numero dei grafismi sia direttamente proporzionale al grado di accuratezza descrittiva e di profondità interpretativa che si vuole adottare. Tuttavia la trascrizione fonetica, per quanto dettagliata, rimane pur sempre un’astrazione della complessa realtà fonica dei nostri messaggi verbali.
La trascrizione tra barre oblique segnala infine una rappresentazione fonologica, guidata cioè da principi distintivi e funzionali: ad es., bianco [ˈbjaŋko] ma, in trascrizione fonologica, /ˈbjanko/, essendo [ŋ] un allofono di /n/, la cui ricorrenza è prevedibile in italiano dal contesto (➔ variante combinatoria).
Altre forme di trascrizione fonetica
Parallelamente allo sviluppo e alla diffusione dell’IPA, altri sistemi di trascrizione sono stati elaborati negli anni, sebbene la loro diffusione sia stata circoscritta a determinati sottoambiti scientifici o a specifiche aree geografiche. Gli studi di filologia e dialettologia romanza si contraddistinguono per l’impiego, pressoché sistematico, del sistema cosiddetto Ascoli-Merlo, dal nome dei dialettologi che lo idearono (Graziadio Isaia ➔ Ascoli e Clemente Merlo; ➔ dialettologia italiana). Questo sistema (o una delle sue numerose varianti), codificato nel XIX secolo, è stato applicato nella compilazione degli ➔ atlanti linguistici e in diverse opere di fonologia e dialettologia romanza.
Più recentemente è stato elaborato un nuovo metodo di trascrizione fonetica per ovviare ai problemi tipografici insiti nell’impiego della rappresentazione IPA. Questa forma di decodifica fonetica, denominata SAMPA (Speech Assessment Methods Phonetic Alphabet), trae origine dall’IPA, ma se ne distanzia per l’impiego esclusivo di caratteri ASCII (cfr. Wells 1994 e 1998). Concepito da un gruppo internazionale di fonetisti nel 1987-1989, SAMPA (o la sua più recente versione estesa, X-SAMPA) è stato applicato inizialmente in ambito europeo, italiano compreso, per poi diffondersi rapidamente anche in altre lingue come arabo, turco, cantonese, ecc. L’alfabeto SAMPA, pur partendo da un numero base di elementi, è stato di volta in volta adattato e integrato alle caratteristiche fonetiche delle diverse lingue. Per maggiori approfondimenti sull’elenco dei simboli proposti in ciascuna lingua e sull’equivalente simbolo IPA rinviamo alla pagina web http://www.phon.ucl.ac.uk/home/sampa.
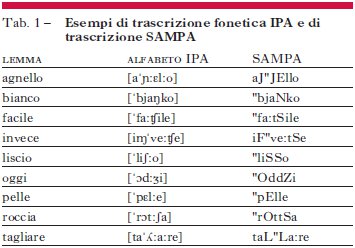
Relativamente all’italiano, riportiamo qui di seguito alcune corrispondenze tra IPA e SAMPA (ma si confrontino anche la trascrizione fonetica IPA e la trascrizione SAMPA delle parole elencate nella tab. 1):
Alfabeto IPA SAMPA
[ɛ] E
[ɔ] O
[ʧ] tS
[ʤ] dZ
[ʃ] S
[ɲ] J
[ʎ] L
[ŋ] N
[ɱ] F
[ˈ] "
[ː] :
desonorizzazione _0
sonorizzazione _V
Studi
Handbook of the International Phonetic Association. A guide to the use of the International Phonetic Alphabet (1999), Cambridge, Cambridge University Press.
Pullum, Geoffrey K. & Ladusaw, William A. (19962), Phonetic symbol guide, Chicago - London, The University of Chicago Press (1a ed. 1986).
Wells, John C. (1994), Computer-coding the IPA: a proposed extension of SAMPA, disponibile presso il sito http://www.phon.ucl.ac.uk/home/sampa/home.htm.
Wells, John C. (1998), Computer readable phonetic alphabet, in Hand-book of standard and resources for spoken language systems, edited by D. Gibbon, R. Moore & R. Winski, Berlin-New York, Mouton de Gruyter, part IV, section B.