
soprasegmentali, tratti
soprasegmentali, tratti
Definizione
Per il parlante comune la comunicazione orale consiste di suoni che possono essere trascritti ortograficamente o foneticamente. Così, una parola come casa può essere resa in forma scritta come una sequenza di quattro caratteri alfabetici distinti e disposti secondo un ordine. I suoni così rappresentati sono considerati segmenti, cioè porzioni di una parola. La loro trascrizione è perciò detta segmentale. Ma esistono alcune caratteristiche del modo in cui questa parola può essere pronunciata che non sono rappresentabili con la trascrizione segmentale: si tratta, ad es., della forza, del tono, dell’➔accento, della durata (➔ quantità fonologica), del ➔ ritmo elocutivo. Tali caratteristiche, di solito, si estendono su un dominio più ampio dei confini di un singolo segmento sonoro e sono perciò denominate soprasegmentali.
La classificazione di fatti segmentali e soprasegmentali è tradizionalmente fondata sulla diversità delle proprietà degli eventi fonetici e acustici ai quali essi sono associati: in genere, ma non mancano eccezioni e casi intermedi, i tratti segmentali sono percepibili e categorizzabili in maniera intrinseca e si possono spesso opporre in maniera assoluta e binaria, mentre quelli soprasegmentali si distinguono e classificano in maniera relativa e gradiente, in quanto si distribuiscono lungo un continuum.
Ad es., in italiano l’opposizione sonoro ~ non sonoro (che contraddistingue coppie di foni come [p] ~ [b]) è un tratto segmentale, perché la sonorità appartiene intrinsecamente al meccanismo con cui il suono è prodotto; mentre la capacità di occupare il nucleo sillabico (➔ sillaba) è una proprietà gradiente. Infatti, le ➔ vocali sono dotate in massimo grado e le consonanti occlusive non sonore in minimo grado; nondimeno, in gradi intermedi, essa è propria anche di altri foni (cfr. la scala di sonorità; ➔ fonologia): ad es., una parola trisillabica come albero /ˈalbero/ nello stile informale può essere realizzata [ˈalbro], per cui la seconda sillaba perde la vocale e la posizione di nucleo sillabico è occupata da [b]. Perciò l’opposizione sillabico ~ non sillabico è un esempio di tratto soprasegmentale.
La ragione della denominazione con prefisso sopra- è da ascriversi al fatto che tali tratti sono spesso proprietà che concernono più di un fono consecutivo della catena parlata e, in particolare, unità dell’ordine della sillaba, della parola fonologica (➔ parola italiana, struttura della), del sintagma fonologico, del piede e del sintagma intonativo, come si vedrà nei §§ 2 e 3. In tal senso, il termine soprasegmentale (coniato da Hockett 1942) ricopre un ambito simile a quello di ➔ prosodia (di Firth 1948) e di prosodema (di Hjelmslev 1936).
Secondo una tipologia proposta da Trubeckoj (1939), i tratti soprasegmentali possono avere funzione: (a) distintiva, cioè sono portatori di significati diversi; (b) demarcativa, cioè marcano il confine di altre unità linguistiche; (c) culminativa, cioè segnalano l’apice di un valore gradiente.
Tra i più importanti fenomeni soprasegmentali della lingua italiana si annoverano la prominenza accentuale (che, ad es., distingue sillabe toniche e atone; ➔ accento), la durata (che oppone foni lunghi e brevi, con e senza rilevanza fonologica; ➔ quantità fonologica), il tono, la sillaba, la giuntura (➔ sandhi), il ritmo e l’➔intonazione (che in italiano supporta l’espressione di fenomeni informativi e ha la funzione di distinguere le modalità di frase assertiva e interrogativa).
Giuntura
Con il termine giuntura (introdotto dalla linguistica americana) si indica un fatto fonetico che segnala un confine tra unità grammaticali; si tratta, quindi, di unità con funzione demarcativa.
In italiano può essere utile ricorrere a tale risorsa per spiegare la realizzazione sorda della fricativa coronale intervocalica (➔ fricative) al confine di morfema (per es.: ri[s]alire e non *ri[z]alire) nelle varietà italiane settentrionali (➔ Milano, italiano di), che pure presentano una sistematica ➔ sonorizzazione intervocalica. Infatti, in tali casi la rappresentazione morfofonologica sarà /ri+salire/, dove il simbolo ‹+› indica appunto una giuntura di morfema, e ciò permette di concludere che la fricativa è sorda perché non è in posizione intervocalica.
Il confine di parola (indicato da ‹#›) è un altro esempio di giuntura: può essere manifestato da una pausa, ma più spesso è privo di espressione materiale e mostra la sua presenza solo per i vincoli che innesca su altri fenomeni fonologici. Ad es., in italiano la sillaba tonica finale di parola (cioè al confine di #) presenta un nucleo vocalico breve anche se in sillaba libera (al contrario di quanto avviene in altre posizioni di parola): beltà. In breve, la nozione di giuntura può essere applicata ogni volta che si definisce il confine di un dominio linguistico (ad es. il piede, la parola fonologica, il sintagma fonologico, il sintagma intonativo).
Accento e prominenze metriche
Per i parlanti la nozione di accento è generalmente intuitiva, tanto che, in genere, non si ha difficoltà a indicare su quale vocale della parola esso cada. Tuttavia, da un punto di vista linguistico, si tratta di una proprietà della sillaba (➔ fonologia; ➔ sillaba) che, seppure manifestata attraverso una maggiore prominenza percettiva, è tuttavia addebitabile a un preciso tramite fonetico: in italiano, all’incremento di durata della rima sillabica, o tramite allungamento del solo nucleo, occupato da una vocale, come nella sillaba tonica libera (ad es. la sillaba /ˈpa/ di pane si realizza [paː]), o tramite allungamento di nucleo e coda, come accade nella sillaba tonica implicata (ad es. la sillaba /ˈpar/ di parte si realizza [par]). Tale proprietà culminativa dell’accento riguarda un dominio linguistico: è la prominenza sillabica maggiore tra quelle della stessa parola fonologica (o prosodica; ➔ prosodia). Entro tale dominio possono esistere prominenze subordinate (accenti secondari) e non-prominenze (sillabe atone): ad es., nella catena la luce, l’accento su /ˈlu/ domina l’intera sequenza, compreso l’articolo, che in isolamento è tonico ma davanti al nome prende un accento secondario.
Un’altra caratteristica dell’accento italiano è la sua distribuzione e funzione distintiva: può associarsi a qualsiasi sillaba (per questo l’accento italiano è detto libero) della parola fonologica e, quindi, determinare il cambiamento di significato delle parole lessicali, come si vede negli esempi seguenti: mèta ~ metà, àncora ~ ancòra, princìpi ~ prìncipi, càpitano ~ capitàno. In altre lingue, come il francese (dove l’accento cade sempre sull’ultima sillaba) o il polacco (dove cade sempre sulla penultima), tale funzione distintiva manca e l’accento svolge piuttosto una funzione demarcativa di confine di parola fonologica.
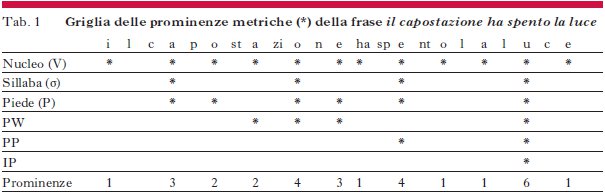
L’esempio della sequenza la luce mostra che l’accento è espresso attraverso due gradi. Per rappresentare questo fenomeno, i costituenti su cui esso può collocarsi sono inseriti in una struttura gerarchica, in cui ogni ramo presenta almeno un elemento più forte, che perciò domina l’altro o gli altri elementi (come si vedrà in tab. 1 e in fig. 1).
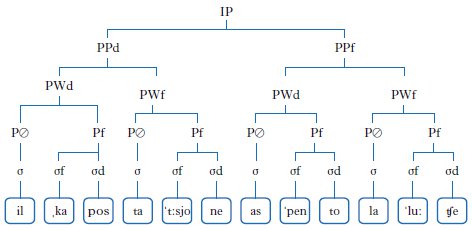
Il tratto fonologico soprasegmentale che rende conto di questa distribuzione distingue una posizione forte e una debole. Quindi, in una sequenza come la luce /ˌlaˈluːʧe/ la sillaba [luː] sarà comparativamente più forte di [la], ma quest’ultima sarà a sua volta più forte di [ʧe]; infatti, il tratto forte ~ debole è un caso di opposizione gradiente, nel senso che si applica ricorsivamente a vari livelli della derivazione fonologica, ogni volta che un costituente può essere adeguatamente strutturato internamente in un componente prominente (obbligatorio) distinto da altri. Così, il tratto forte ~ debole determina anche la gerarchia fonologica che distingue il nucleo (forte) rispetto ai margini (deboli) della sillaba, sia essa tonica che atona. Similmente, la stessa opposizione costituisce tutte le altre strutture della gerarchia metrica: il piede metrico è costituito da una sillaba forte e da una o più deboli (ad es., la parola luce è un esempio di piede trocheo con la testa [luː]).
La parola fonologica (PW, phonological word) ha la struttura interna formata da un piede forte e almeno un piede debole. Il sintagma fonologico (PP, phonological phrase) è, a sua volta, strutturato internamente allo stesso modo (la PW forte è la testa obbligatoria e le altre eventuali PW deboli sono facoltative). Infine, l’insieme di più PP costituisce un sintagma intonativo (IP, intonational phrase), a sua volta costituito dalla relazione tra un PP forte che domina uno o più PP deboli (ad es., la frase il capostazione ha spento la luce è un IP dominato dal PP ha spento la luce).
La tab. 1 illustra una possibile (non l’unica) realizzazione della frase il capostazione ha spento la luce. Lo stesso tratto soprasegmentale forte ~ debole è usato a vari livelli di derivazione fonologica, con domini linguistici diversi, per rendere conto dell’organizzazione metrico-prosodica. A livello della struttura interna della sillaba, differenzia il nucleo (in italiano è occupato solo da vocali = V) dai margini (attacco e coda) (➔ fonologia); a livello intersillabico, differenzia sillabe toniche e atone; a livello di piede metrico, distingue piedi forti (come il trocheo zione), deboli (come il dattilo caposta) e piedi degeneri (cioè privi di ramificazione forte ~ debole, come il o ha); a livello di parola fonologica, distingue la testa (il piede forte) dal costituente modificato (il piede debole); a livello di sintagma fonologico, differenzia la testa del PP (la PW portatrice della prominenza relativamente maggiore, ad es. la luce in ha spento la luce); infine, a livello di sintagma intonativo, nelle frasi relativamente neutre, cioè con focus intonativo sulla parte finale dell’enunciato (focus ampio), il tratto forte si associa all’ultima prominenza (all’ultimo PP). La riga finale della tab. 1 mostra il risultato della somma dei singoli indici di prominenza (*) sintetizzandone il valore finale con un numero che è la somma dei singoli indici associati per ogni punto della catena fonica (in pratica ogni vocale): la sillaba [ˈluː] porta la massima prominenza (valore 6).
La rappresentazione di tab. 1 mostra anche che la differenziazione tra accento secondario e accento primario (tipica, ad es., dei composti come capostazione [ˌkapostaˈtːsjone]) si realizza a livello di PW ed è una variazione di grado di prominenza accentuale. In alternativa alla griglia, il medesimo sistema di distribuzione del tratto forte ~ debole è rappresentabile mediante un albero metrico (cfr. fig. 1), nel quale ogni nodo è etichettato con il simbolo del livello di derivazione corrispondente e dotato di un tratto forte o debole. La massima accentuazione sulla sillaba [ˈluː] qui non è espressa mediante un indicatore numerico, come nella rappresentazione a griglia di tab. 1, ma dal fatto che tutti i nodi della ramificazione dell’albero di cui essa è il terminale sono f.
Dunque, il tratto forte ~ debole costituisce un fattore strutturante di una complessa gerarchia che comprende diverse grandezze soprasegmentali, come la sillaba, l’accento, il piede metrico, la parola fonologica, il sintagma fonologico e intonativo. Naturalmente, l’espressione fonetica di tale opposizione fonologica può mutare a seconda del livello della gerarchia. Così, la sillaba forte è in generale caratterizzata da una rima (nucleo + coda sillabici) di durata maggiore, mentre la PW o il PP forti si distinguono per un incremento sia di durata che di tono. Di seguito, vengono discusse le manifestazioni di tale gerarchia di forza attraverso fenomeni di durata (e quantità), di tono, di intonazione e di ritmo.
Durata e quantità
Si è osservato che la durata vocalica è correlata al tratto di accento e quindi alla struttura sillabica. Tuttavia, in italiano, la variazione di durata vocalica non ha funzione distintiva, a differenza di quanto accade in latino (cfr., ad es., coppie minime come ŏs «osso» ~ ōs «bocca», pŏpŭlus «popolo» ~ pōpŭlus «pioppo», mălum «il male» ~ mālum «mela»; ➔ coppia minima; ➔ latino e italiano). Perciò, in italiano la quantità vocalica è fonologicamente irrilevante, anche se una variazione di durata vocalica viene sfruttata con funzione demarcativa di accento. Invece, la durata delle consonanti (per gran parte del sistema consonantico italiano) può avere valore distintivo: si vedano le seguenti coppie minime: ca[s]a ~ ca[sː]a, co[p]ia ~ co[pː]ia, ca[r]o ~ ca[rː]o. Perciò, si può concludere che l’italiano possiede opposizioni di quantità consonantica, che distinguono consonanti scempie e geminate.
Quindi, mentre la quantità è un concetto fonologico, la durata è una misura fonetica. Perciò, i valori di durata hanno carattere relativo: un segmento è lungo o breve in relazione ad altri segmenti di pari grado e natura linguistica, e non in senso assoluto. In particolare, essi dipendono dalla velocità di eloquio, per cui se un parlante articola in maniera più rapida, i suoi foni risulteranno più brevi, se confrontati con quelli di un altro parlante che sia più accurato e sorvegliato nella pronuncia. Inoltre, la durata vocalica è sensibile alla prossimità del confine finale di sintagma intonativo (IP): come si è già osservato in tab. 1 e in fig. 1, l’ultima sillaba tonica, ma anche le eventuali atone finali, sono soggette al fenomeno detto allungamento prepausale (dovuto a un significativo rallentamento della velocità elocutiva alla fine di ogni IP; nell’esempio il capostazione ha spento la luce, l’ultima vocale tonica [u] è specificamente più lunga della altre vocali accentate della medesima frase). Tale allungamento è uno dei fattori fonetici che manifestano la maggiore forza fonologica dei costituenti metrici in fine di IP.
Ritmo
Che le lingue possiedano un ritmo sembra essere un’evidenza intuitiva che i parlanti attribuiscono normalmente ad alcune manifestazioni poetiche (ugualmente, certi idiomi sono qualificati come più ritmici di altri, o certi modi di parlare vengono considerati popolarmente più cadenzati di altri).
In realtà, anche il comportamento di alcune unità linguistiche nel linguaggio ordinario sembra manifestare specificità che possono trovare una spiegazione se inquadrate in un modello ritmico. Per modello ritmico si intende un sistema di relazioni tra prominenze foniche che si alternano nella catena parlata. Le prominenze di cui si parla sono della stessa natura fonica di quelle già esaminate nel caso dell’accento. Quindi, si tratta ancora di opposizioni forte ~ debole. Per quanto riguarda i fenomeni che richiedono una spiegazione ritmica, si consideri che alcune lingue, come l’inglese, presentano maggiore tolleranza alla compressione della durata temporale delle sillabe atone, ossia delle vocali atone, mentre altre, tra cui l’➔italiano standard, sono assai più refrattarie a ridurre la durata di queste vocali. Inoltre, la maggiore tolleranza alla comprimibilità delle atone si accompagna con una maggiore predisposizione a ridurne il ➔ timbro: le vocali atone tendono, perciò, a differenziarsi nettamente dalle toniche, centralizzandosi o dando luogo a complesse evoluzioni diacroniche.
Viceversa, nelle lingue come l’italiano, l’incomprimibilità della durata delle atone si coniuga con una minore differenziazione tra il sistema vocalico tonico e atono. Le lingue del primo tipo, infine, presentano diffusi fenomeni di ➔ assimilazione e coarticolazione tra foni adiacenti, che hanno portato alla creazione di strutture sillabiche particolarmente complesse, con margini sillabici occupati da numerosi foni consonantici (indicati con C: per es., CCVCC, come in ingl. stealth /ˈstɛlθ/ «furtività», o CCCVCCC, come in ingl. strengths /ˈstrɛƞθs/) «forze». Le lingue del secondo tipo (cui appartiene anche l’italiano standard), invece, hanno spiccata tendenza a sillabe semplici, prive di margini (del tipo V, come in aria /ˈaː.rja/; in questo e negli esempi che seguono, il puntino indica il confine sillabico) o con attacco al massimo triconsonatico e, soprattutto, con coda al massimo monoconsonantica (di tipo CV(C), come in parte /ˈpar.te/; o CCV(C), come in stormo /ˈstor.mo/; o CCCV(C), come in strillo /ˈstril.ːo/).
Queste sistematiche concordanze tipologiche possono trovare una spiegazione unitaria se si ammette che le lingue del primo tipo (come l’inglese) tendano a mantenere temporalmente costanti gli intervalli tra un accento lessicale e il successivo; mentre le lingue del secondo tipo (come l’italiano) tendano a fare la stessa cosa con gli intervalli tra un confine sillabico e il successivo. In sostanza, nel primo caso l’alternanza del tratto forte ~ debole è regolata sull’‘orologio’ dell’accento e nel secondo su quello della sillaba.
Secondo una bipartizione di Pike (1947), le prime sono lingue isoaccentuali e le seconde isosillabiche (➔ fonetica; ➔ pronuncia). Naturalmente, si tratta di una tipologia binaria, quindi ritenuta, nella letteratura scientifica corrente, giustamente troppo semplice. Tanto più che la stratificazione interna alle singole lingue è spesso tutt’altro che omogenea: alcuni dialetti meridionali (ad es., nella Puglia settentrionale e a Matera; ➔ meridionali, dialetti) sembrano tendere verso il tipo isoaccentuale, mentre i dialetti centrali e alcuni settentrionali sono di tipo isosillabico. Tuttavia, una osservazione del ritmo linguistico può contribuire a fornire una cornice esplicativa a diversi fenomeni apparentemente irrelati.
Tono e intonazione
Da un punto di vista fonetico, tono e ➔ intonazione sono riconducibili allo stesso fenomeno fisico. Si tratta della variazione della frequenza di vibrazione delle corde vocali (o frequenza fondamentale o F0), che si sviluppa lungo l’intera durata dell’enunciazione di una catena fonica. In tal senso, si può constatare che ogni voce umana dispone di un repertorio di variazioni tonali fortemente vincolato alla fisiologia e all’anatomia del parlante. Sicché le altezze (o target) tonali di cui ogni parlante dispone costituiscono un insieme finito. In sostanza, la F0 può salire o scendere, oppure rimanere più o meno stabile nel tempo. L’ampiezza (o range) di questa variazione verso l’alto / basso dipende grandemente dalle caratteristiche fisiche del parlante (dimensioni corporee, sesso, età, ecc.). Esiste, inoltre, una sorta di condizionamento biologico, prelinguistico, che opera anche a livello percettivo e che ci porta ad associare frequenze alte e basse rispettivamente a sorgenti (ad es., a parlanti) fisicamente piccole e grandi.
Tuttavia, le cose cambiano se si osserva il fenomeno dal punto di vista fonologico. Il fenomeno fisicamente continuo della curva melodica può avere una pertinenza fonologica (ad es., in quanto fattore che distingue una frase assertiva da una interrogativa; ➔ illocutivi, tipi; ➔ curva melodica) a condizione che si riesca a scomporlo in un insieme di parti discrete e che si individui un significato o una funzione da esso veicolati. Nelle lingue tonali (come, ad es., il cinese mandarino) il compito è semplificato dal fatto che in esse ogni sillaba è portatrice di un tono discreto che è assegnato a livello grammaticale o lessicale ed è pertanto un tratto segmentale. Quindi, il contorno intonativo linearizza una sequenza di toni discreti.
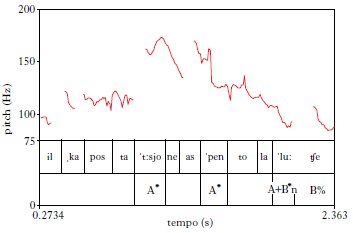
L’italiano non è una lingua di questo tipo. Sul piano fonologico, tuttavia, anche la curva melodica dell’italiano può essere rappresentata come una serie di cosiddetti bersagli o target tonali che si succedono nel tempo. Quindi, una curva continua viene rappresentata fonologicamente mediante una successione di toni discreti di due tipi: Alto e Basso (se ne può vedere un esempio in fig. 3). L’altra condizione per una fonologia dell’intonazione è trovare una funzione linguistica che sia sistematicamente espressa attraverso una certa sequenza di toni. Ad es., in italiano l’opposizione tra modalità frasale assertiva e interrogativa (del tipo sì-no) è veicolata da una differenza di contorno intonativo specificamente associato alla parte finale della frase: la sillaba finale dell’interrogativa è caratterizzata da un tono soprasegmentale Alto.
Un altro esempio di tratto tonale con valore soprasegmentale è quello relativo all’espressione di ordini. In italiano, enunciati come qui!; a casa!; mangia subito la pasta! sono comunemente riconosciuti come espressione di tale intenzione comunicativa. I rispettivi contorni intonativi hanno infatti in comune un andamento complessivo a tre target, di tipo Basso-Alto-Basso, che si realizza in una forma più o meno condensata, a seconda dell’estensione temporale e del numero di costituenti della frase cui si sovrappone (tipicamente, qui! presenta un movimento molto più compresso di mangia subito la pasta!).
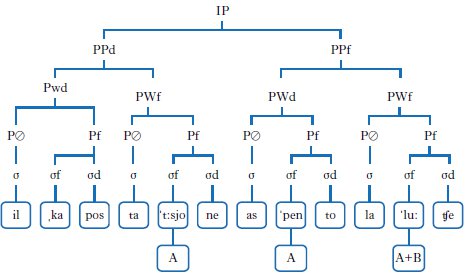
Per rappresentare la struttura fonologica del tono e dell’intonazione, può essere utile prendere nuovamente in considerazione la gerarchia metrica presentata in tab. 1 e in fig. 1. Quelle rappresentazioni definiscono alcuni punti di diverso grado di prominenza (o forza) distribuiti lungo la catena il capostazione ha spento la luce. Quei punti sono percettivamente salienti e quindi costituiscono il vettore privilegiato per veicolare l’ulteriore informazione tonale. Si associa, quindi, un tono fonologico Alto (A) o Basso (B) a ogni prominenza metrica. Ad es., la modalità assertiva neutra italiana potrebbe essere rappresentata come in fig. 2.
Commutando il tono A+B finale con un tono B+A (o A) si può ottenere la rappresentazione della frase interrogativa chiusa (o sì-no) in numerose varietà di italiano. Come si vede, il contorno intonativo continuo è stato scomposto in un numero finito (in questo caso 3) di target tonali discreti. In tal modo, anche in una lingua non tonale, come l’italiano, è possibile rappresentare la fonologia dell’intonazione mediante una concatenazione di tratti tonali A ~ B.
Naturalmente, la rappresentazione esemplificativa che è stata appena data è ancora grossolana, perché in essa sono saturate con toni solo alcune delle possibili posizioni di prominenza metrica: nella letteratura scientifica questi toni associati ai punti di prominenza maggiore si chiamano accenti tonali (AT). Occorrerebbe aggiungere un secondo tipo di toni associati ai confini di sintagma intonativo (IP) e di sintagma fonologico (PP). Per definirli si deve fare appello a un tratto soprasegmentale che è stato già esaminato: la giuntura. Infatti, i toni di cui si parla sono i cosiddetti toni di confine (boundary tones o BT), cioè toni che si trovano alla fine di un dominio sintagmatico (PP, IP). Nell’interrogativa di molte varietà italiane è il tono di confine finale di IP (associato con l’ultima sillaba dell’IP) che è A, in contrapposizione a quanto avviene nelle assertive, in cui tale tono è B (come si vede in fig. 3). Inoltre, l’approccio fonologico all’intonazione consente di rimodulare i toni fonologici in funzione del variare della lunghezza del materiale segmentale a disposizione. Così, se la frase in questione diventa la luce, allora l’interrogativa (la luce?) sarà sempre espressa da un AT di tono B + A (o A) sulla sillaba [ˈluː], mentre l’assertiva presenterà un AT di tono A + B sulla medesima sillaba. Parimenti, attraverso un approccio fonologico si riesce a rappresentare la focalizzazione (➔ focalizzazioni) intonativa di alcuni costituenti della frase. Ad es., se la frase in questione è la risposta a una domanda del tipo chi ha spento la luce?, allora il capostazione sarà l’elemento focalizzato (normalmente in lettere maiuscole nelle trascrizioni). La resa intonativa di tale frase è caratterizzata da un picco ascendente-discendente sul costituente focalizzato. Quindi, l’AT associato alla sillaba [ˈʦjo] sarà B + A. Il problema del cosiddetto allineamento tonale rispetto ai costituenti segmentali è di grande importanza nella caratterizzazione fonologica dei contorni intonativi.
Studi
Firth, John Rupert (1948), Sounds and prosodies, «Transactions of the Philological Society», pp. 127-152 (rist. in Id., Papers in linguistics, 1934-1951, London, Oxford University Press, 1957, pp. 120-138).
Hjelmslev, Louis (1936), On the principles of phonematics, in Proceedings of the 2nd international congress of phonetic science (London, July 22-26 1935), edited by D. Jones & D.B. Fry, Cambridge, Cambridge University Press, pp. 49-54.
Hockett, Charles F. (1942), A system of descriptive phonology, «Language» 18, pp. 3-21.
Pike, Kenneth L. (1947), Phonemics. A technique for reducing languages to writing, Ann Arbor, University of Michigan Press.
Trubeckoj, Nikolaj S. (1939), Grundzüge der Phonologie, «Travaux du Cercle linguistique de Prague» 7 (trad. it. Fondamenti di fonologia, Torino, Einaudi, 1971).