
probabilità
Nel linguaggio scientifico, in presenza di fenomeni casuali (o aleatori), p. di un evento è il numero, compreso fra 0 e 1, che esprime il grado di possibilità che l’evento si verifichi, intendendo che il valore minimo 0 corrisponda al caso in cui l’evento sia impossibile, mentre il valore massimo 1 corrisponda al caso in cui l’evento sia certo.
Matematica
Calcolo (o teoria) delle probabilità
La disciplina matematica che studia il concetto intuitivo di p., precisandone il contenuto sostanziale e le regole formali e sviluppandole in più ampie teorie, è definita calcolo delle probabilità.
Il concetto di p. sembra del tutto ignoto agli antichi, anche se era implicitamente presente. I primi studi conosciuti di questioni di p. si riferiscono al gioco dei dadi, e sono il De aleae ludo di G. Cardano e una lettera di G. Galilei. Uno sviluppo più ampio si ebbe con una corrispondenza tra B. Pascal e P. Fermat, originata intorno al 1650 da problemi posti a Pascal da un accanito giocatore d’azzardo, il cavaliere de Méré. Lo studio di tali problemi fu intrapreso da vari autori, e nel 1657 apparve quello che può essere considerato il primo trattato di p., De ratiocinio in ludo aleae, di C. Huygens. Ma il contributo più importante, in questa fase di sviluppo, è dovuto a G. Bernoulli che nel suo libro Ars coniectandi, apparso postumo nel 1713, ne ha dato una prima trattazione sistematica. Un’altra tappa fondamentale si ha con la Théorie analytique des probabilités, di P.-S. de Laplace, apparsa nel 1812, che presenta in una teoria organica gli sviluppi classici del calcolo delle probabilità. Nel 20° sec. è stata chiarita (in particolare da F.P. Cantelli) la nozione di variabile casuale. Sono state introdotte e studiate (B. De Finetti, A.N. Kolmogorov, P. Lévy) le distribuzioni infinitamente divisibili (o indefinitamente decomponibili), e con il loro ausilio si arrivò alla forma più completa del teorema centrale di convergenza, con il contributo essenziale, oltre ai tre citati sopra, di W. Feller, A. Kincin, B. Gnedenco. Ma i contributi più importanti sono dati dallo studio dei processi aleatori, che ha inizio con i processi a catena introdotti da A. Markov, e si è sviluppato poi con i fondamentali contributi di Kolmogorov, Lévy, J.L. Doob, Kincin, Feller, K.L. Chung.
Nel linguaggio comune, ogni volta che si presenti una molteplicità di alternative e non si disponga di sufficienti elementi per decidere quale di queste alternative si verificherà, si parla di p. delle varie alternative. Il tentativo di precisare il concetto di p. si è sviluppato storicamente attraverso l’analisi del modo in cui esso viene usato nei vari contesti in cui interviene e ha fatto emergere due modi principali di uso del termine p.: a) la p. di un evento intesa come espressione di una proprietà fisica dell’evento stesso e delle condizioni in cui esso si verifica (punto di vista ontologico); b) la p. di un evento come il grado di fiducia che un individuo nutre nel verificarsi dell’evento in questione, e perciò riguardante lo stato delle nostre conoscenze sull’evento in un determinato istante (o intervallo di tempo) più che le obiettive proprietà dell’evento stesso (punto di vista epistemico). In modo impreciso (e talvolta polemico) taluni chiamano oggettivo il punto di vista ontologico sulla p. e soggettivo quello epistemico. Il primo presuppone la nozione (intuitiva) di eventi equiprobabili. Si parla di eventi equiprobabili quando non vi è ragione sufficiente che, delle varie modalità di cui è suscettibile un fenomeno, una si verifichi più spesso delle altre.
Il calcolo delle p. ha avuto uno sviluppo enorme agli inizi del 20° sec., e ciò è collegato all’importanza sempre maggiore che esso ha assunto nelle applicazioni. Infatti, in tutte le scienze sperimentali si riconosce una situazione che può essere inquadrata nel seguente schema generale: a) si considera un insieme I di sistemi fisici per i quali ha senso parlare del verificarsi dell’evento A; b) si suppone che ciascun sistema dell’insieme I soddisfi un complesso di condizioni, che denoteremo con il simbolo C e che rappresenta le condizioni di preparazione dell’esperimento in cui si verifica l’occorrenza dell’evento A; c) si suppone che tutte le altre condizioni che, in aggiunta al complesso di condizioni C, possono influenzare il verificarsi dell’evento A si presentino in modo completamente casuale all’interno dell’insieme I; d) si verifica sperimentalmente il numero di occorrenze dell’evento A su un grande numero, diciamo N, di sistemi scelti a caso nella famiglia I, e denoteremo N(A∣C) tale numero; e) al crescere di N le quantità N(A∣C)/N (frequenze relative dell’evento A) tendono a stabilizzarsi intorno a un numero fisso indipendente da N e dal collettivo I; tale numero, che si denota P(A∣C), è detto la p. condizionata di A dato C. Talvolta il complesso di condizioni C viene considerato fissato una volta per tutte e perciò lo si omette dalle notazioni scrivendo semplicemente P(A) invece che P(A∣C) e parlando di p. dell’evento A senza specificare sotto quali condizioni si valuta questa probabilità. Ogni insieme I di sistemi, che soddisfi le condizioni a, b, c è chiamato collettivo statistico, o ensemble, oppure insieme di sistemi indipendenti e identicamente preparati. Il fenomeno descritto al precedente punto e è detto anche legge empirica del caso oppure legge di stabilizzazione delle frequenze relative. Il termine ‘legge’ va inteso nel senso che le grandezze osservabili cui si riferiscono le leggi statistiche sono le frequenze relative, cioè grandezze che non riguardano i singoli, ma i collettivi statistici; di queste grandezze, le leggi statistiche non dicono quali valori assumeranno, ma quali valori tenderanno ad assumere.
Leggi delle probabilità
Le regole con cui dalle p. di alcuni eventi si deducono le p. di eventi da essi composti sono dette leggi della probabilità. Nella costruzione del modello matematico alcune di queste leggi vengono assunte come assiomi e tutte le altre ne discendono. Esiste più di un sistema di assiomi per la p. e ciascuno di questi sistemi conduce a un modello matematico diverso. Gli assiomi che definiscono i vari modelli probabilistici si suddividono nelle categorie seguenti.
Assiomi di normalizzazione
Questi, insieme con l’assioma di additività, sono comuni a tutti i modelli probabilistici; essi sono i due seguenti: (PN1) qualunque sia C, la p. di un evento A è un numero compreso tra 0 e 1; (PN2) per ogni evento C si ha: P(C∣C)=1.
Assiomi di struttura
Riguardano la struttura globale dell’insieme degli eventi relativamente a operazioni tra essi. La congiunzione di due eventi A, B è l’evento che corrisponde all’accadere di entrambi e si denota A⋃B; la disgiunzione di A e B è l’evento corrispondente all’accadere di almeno uno di essi e si denota A⋂B; la negazione di A è l’evento corrispondente al non accadere di A e si denota Ac, o Ā. In modo analogo, si definiscono la congiunzione A1⋃A2⋃A3⋃ … e la disgiunzione A1⋂A2⋂A3⋂ … di un qualsiasi numero finito di eventi.
Un evento A si dice evento composto dagli eventi di un dato insieme (finito o no) se esso può essere ottenuto a partire da questi applicando un numero finito di volte le operazioni di congiunzione, disgiunzione, negazione. Ciò conduce al postulato di compatibilità (PC1) fondamentale per la p. classica: l’insieme degli eventi di cui si considera la p. è un insieme chiuso per le operazioni di congiunzione, disgiunzione, negazione. Poiché le proprietà di queste operazioni sono identiche a quelle dei consueti connettivi logici booleani e, o, non, una famiglia di eventi, chiusa rispetto a esse, viene detta un’algebra booleana (o un reticolo booleano), il cui modello matematico naturale è costituito da una famiglia di sottoinsiemi di un insieme S chiusa per le operazioni di intersezione, unione, complemento. Così, supponendo assegnato uno spazio S, ogni evento sarà identificato a un sottoinsieme di S. Lo spazio S è detto, secondo le interpretazioni, spazio degli eventi o dei campioni (sample space) o degli stati o delle configurazioni o delle traiettorie … La relazione di inclusione A⊆B (A è contenuto in B) corrisponde alla relazione di implicazione tra eventi (A implica B).
Nella sua formulazione del calcolo delle p., A.N. Kolmogorov ha introdotto una forma più forte del postulato di compatibilità (PC2), cioè: l’insieme degli eventi è chiuso non solo per le operazioni di unione e intersezione finite e negazione, ma anche per la congiunzione di una famiglia numerabile di eventi. Un’algebra booleana con questa proprietà è detta una σ-algebra booleana (o σ-algebra). In alcune situazioni i postulati di compatibilità vengono sostituiti dal seguente (PC3): esistono eventi le cui congiunzioni o disgiunzioni non rappresentano eventi fisicamente significativi; essi vengono detti incompatibili, in caso contrario compatibili.
Assioma di additività finita
Traduce la proprietà che le p. di eventi mutuamente esclusivi si addizionano: (PA) se A e B sono eventi mutuamente esclusivi, allora la p. dell’evento A⋂B è sempre ben definita e risulta: P(A⋂B)=P(A)+P(B).
Assiomi di continuità
Riguardano eventi composti da infiniti eventi. Il prototipo di essi è il postulato di numerabile additività (o di σ-additività) di Kolmogorov (P1) : se (An) è una successione di eventi mutuamente esclusivi, allora la loro unione è un evento fisicamente significativo e risulta P(⋂∞n=1An)=∑∞n=1P(An).
Assiomi di condizionamento
Questi assiomi esprimono il modo di variare della p. di un evento A quando si acquisiscano informazioni sul verificarsi di un altro evento B. Nel modello classico questa p. è definita come segue (C1): se A, B, C sono tre eventi tali che A sia compatibile con B e B sia compatibile con C, allora, se è P(B|C)≠0, risulta essere (formula elementare delle p. condizionate):
[1] formula2.6
Gli assiomi di Kolmogorov e Rényi
I principali modelli probabilistici classici sono il modello della p. elementare, il modello di Kolmogorov e il modello di Rényi. Ciascuno di essi include come caso particolare il precedente. Il modello della p. elementare è caratterizzato dai postulati (PN1), (PN2), (PA), (PC1) e dalla formula [1], mentre il modello di Kolmogorov mantiene i primi tre e l’ultima, rafforza il quarto con (PC2), e introduce (P1). Entrambi questi modelli si riferiscono al caso in cui tutte le p. sono valutate rispetto a un unico complesso di condizioni C, supposte fissate una volta per tutte. Il modello di Rényi generalizza quello di Kolmogorov introducendo le p. di uno stesso evento riferite a una molteplicità di condizionamenti possibili. Nel modello di Rényi, come in quello di Kolmogorov, l’insieme ℱ di tutti gli eventi è una σ-algebra booleana di sottoinsiemi di un insieme S, lo spazio degli stati. Si considera poi una famiglia ℱ0⊆ℱ di eventi, i cui elementi rappresentano le condizioni sotto cui si valutano le probabilità. A ogni evento B della famiglia ℱ e C della famiglia ℱ0 si associa la p. P(B∣C) dell’evento B sotto la condizione C, e poi si richiede che valgano i postulati di normalizzazione e la formula (C1). Nel caso in cui la famiglia ℱ0 si riduca all’unico insieme S, il modello di Rényi si riduce a quello di Kolmogorov. Nel modello probabilistico classico lo spazio degli eventi è rappresentato da un insieme S, gli eventi da sottoinsiemi di S, e le p. da una funzione P che a un evento A associa un numero P(A) in modo tale che gli assiomi di normalizzazione e finita additività siano soddisfatti. Se la famiglia ℬ di tutti gli eventi è una σ-algebra booleana e la funzione P soddisfa il postulato di numerabile additività, la terna (S, ℬ, P) è detta uno spazio di probabilità. Per tali spazi sono anche frequenti le notazioni: (Ω, ℱ, P) o, omettendo la σ-algebra, (Ω, P).
Dipendenza e indipendenza statistica
Se A1, A2, …, An sono eventi, l’evento A1⋃A2⋃ … ⋃An è detto l’evento congiunto di A1, A2, …, An e corrisponde al verificarsi di ciascuno di questi eventi. La p. P(A1⋃A2⋃ … ⋃An) è detta p. congiunta degli eventi A1, …, An. Se per j≠k gli insiemi Aj e Ak hanno intersezione vuota, gli eventi A1, A2, …, An sono detti eventi disgiunti o mutuamente esclusivi. Nel caso di eventi mutuamente esclusi;vi, vale l’identità:
che è detta teorema (o principio) delle p. totali.
Se B è un evento e P(B)>0, per ogni evento A la p. condizionata di A dato B è definita dalla formula:
L’identità:
valida per ogni evento A e per ogni successione di eventi disgiunti B1, B2, …, Bn la cui unione contiene A, è detta teorema (o principio) delle p. composte.
Dal teorema delle p. composte segue la formula di Bayes:
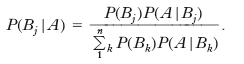
Gli eventi Bj vengono chiamati ipotesi, o cause, e costituiscono le diverse alternative che possono spiegare un evento A osservato sperimentalmente. Le p. P(Bj) sono dette p. a priori, o iniziali, prescindendo dal verificarsi o meno dell’evento A; le p. a posteriori, o finali, P(Bj/A) esprimono le p. delle ipotesi dopo che si è osservato l’evento A; il teorema di Bayes indica come l’osservazione di A modifica le p. delle ipotesi, facendo passare dalle p. a priori alle p. a posteriori. Gli eventi di una data famiglia I sono detti condizionatamente indipendenti dato C (oppure su C) se comunque scelti n eventi A1, A2, …, An della famiglia risulta:
Se la condizione C è supposta fissata una volta per tutte ed è omessa dalle notazioni, gli eventi in questione si dicono indipendenti e l’uguaglianza di sopra si scrive:
Variabile casuale
Sia ξ una grandezza osservabile relativa a un dato sistema fisico. Se le nostre informazioni sul sistema non sono sufficienti a farci prevedere con esattezza il valore della grandezza ξ, può accadere che si possano prevedere almeno le frequenze relative di questi valori, ottenute in un gran numero di misure di ξ in condizioni di preparazione identiche. In questo caso, si dice che ξ è una variabile casuale (o aleatoria, o stocastica, o numero aleatorio). Per es., nel lancio di un dado regolare, i possibili risultati sono i numeri 1, 2, … 6, e prima di effettuare la prova non si sa quale di tali numeri apparirà; possiamo dire soltanto che ciascuno di essi ha p. 1/6; il risultato è quindi una variabile casuale che assume i valori 1, 2, … 6, ciascuno con p. 1/6. La grandezza ξ può assumere valori numerici, vettoriali, tensoriali …; corrispondentemente, essa sarà detta una variabile casuale scalare, vettoriale, tensoriale ecc.
La caratteristica fondamentale di una variabile casuale è data dall’insieme delle p. dei suoi valori o, come si dice, dalla sua distribuzione di probabilità. Quando il numero dei possibili risultati è finito o numerabile, la distribuzione di p. della variabile casuale è individuata dai possibili valori e dalle rispettive p. pi, con pi>0 e Σipi=1; più in generale dati uno spazio di p. (Ω, ℱ, P) e uno spazio (misurabile) S, una variabile casuale da Ω a valori in S è una funzione (misurabile) ξ definita su Ω e a valori in S. A seconda delle interpretazioni della funzione ξ, S viene detto spazio dei valori, spazio degli stati, spazio delle fasi …, mentre Ω viene detto spazio delle traiettorie, o delle configurazioni, o spazio campione (sample space) …. Associando a un sottoinsieme A dello spazio degli stati S il numero Pξ(A)=Prob(ξ∈A)=Prob{che ξ appartenga ad A}, si ottiene una distribuzione di probabilità su S che viene chiamata distribuzione della variabile casuale ξ. La relazione fondamentale, che collega Pξ (che è una distribuzione di p. su S) con P (che è una distribuzione di p. su Ω), è:
dove f è una qualsiasi funzione sufficientemente regolare. Una variabile casuale ξ è detta variabile reale (rispettivamente complessa) se il suo spazio dei valori S è l’insieme dei numeri reali R (rispettivamente complessi). Se S è uno spazio vettoriale, la variabile casuale ξ è detta a valori vettoriali (o multivariata) e se S= Rn la sua distribuzione talvolta è detta distribuzione multivariata di ordine n. Se ξ è una variabile casuale a valori in Rn, fissata una base e=(e1, e2, …, en) di Rn, esistono n variabili causali ξ1, …, ξn [ξj=ξj(e)] tali che:
ξ=∑∞j=1ξjej. Le variabili casuali ξj sono dette
componenti della variabile casuale ξ nella base (ej); esse determinano univocamente la distribuzione di p. di ξ. Una variabile casuale ξ è detta continua se ciascuno dei suoi valori ha p. nulla; è detta discreta se esiste una successione (xk) di valori di ξ tali che
∑∞k=1P(xk)=1, cioè tale che la ξ assume con
p. 1 uno dei valori della successione (xk). Se ξ è una variabile casuale reale e Pξ la sua distribuzione (che è una misura di p. su R) la funzione Fξ: R→[0,1] definita dalla relazione
viene detta funzione di distribuzione della variabile casuale ξ e gode delle seguenti proprietà: (a) se x>y, allora Fξ(x)>Fξ(y);
lim x→+∞ Fξ(x)=1; lim x→−∞Fξ(x)=0; (b) se (xn) è una
successione di numeri che tende decrescendo a x (xn↓x), allora lim F(xn)=F(x), cioè la F è continua da destra. Si dice che la distribuzione di p. Pξ di una variabile casuale reale ξ ammette una densità di p. (rispetto alla misura di Lebesgue) se esiste una funzione pξ(x) tale che:
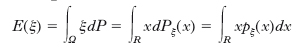
(dove l’ultima uguaglianza vale se ξ ammette densità) è detto valor medio o media o valore d’attesa o speranza matematica o valore di aspettazione della variabile casuale ξ ed è spesso indicato anche con ‹ξ›. Il numero positivo
è detto varianza o dispersione o scarto quadratico medio della variabile casuale ξ ed è spesso indicato con σ2(ξ); la sua radice quadrata (positiva) è detta deviazione standard di ξ. Spesso nei più comuni problemi di fisica statistica la densità di p. è rappresentata dalla curva di Gauss che esprime la legge normale di distribuzione delle p. (➔ errore).
La disuguaglianza di Čebyšëv
con ε>0 arbitrario, mostra che la dispersione di una variabile casuale ξ è una misura di quanto la ξ è concentrata intorno al suo valor medio. I numeri
μk=E(ξk), (rispettivamente E([ξ−E(ξ)]k)
vengono chiamati momenti (rispettivamente momenti centrati) di ordine k della variabile casuale ξ (k=1, 2, …). Il momento di ordine 2 di ξ è detto anche covarianza.
Per la convergenza di variabili casuali ➔ convergenza.
Data una successione ξn di variabili casuali indipendenti e delle loro medie E(ξn) e la successione delle somme parziali, Sn=ξ1+… +ξn, si dice che per ξn vale la legge (debole) dei grandi numeri se [Sn−E(Sn)]/n tende in p. a 0; se cioè, per ogni ε>0,
Vale la legge forte dei grandi numeri se [Sn−E(Sn)]/n tende quasi certamente a 0; se cioè, per ogni ε>0, tende a 1 la p.
del contemporaneo verificarsi di tutte le diseguaglianze dall’n-ma in poi. Una condizione sufficiente per la validità della legge forte (e a fortiori della legge debole) è che le ξn siano indipendenti e abbiano la stessa distribuzione di p., con E(ξn)<∞. Il teorema di Bernoulli (➔) è un caso particolare della legge dei grandi numeri in cui le ξn assumono i soli valori 0 e 1, rispettivamente con probabilità q e p. 2.9 Teorema del limite centrale. Dato un insieme ξn di variabili casuali indipendenti, tutte con la stessa distribuzione di p. e tali che μ=E(ξn)<∞ e σ2=Var(ξn)<∞, il teorema del limite centrale afferma che per tutti gli a e b e per n→∞ risulta
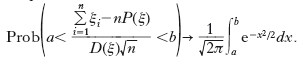
Detto in altro modo, all’aumentare delle dimensioni del campione (n→∞) la distribuzione della media ∑ni=1ξi/n tende (in distribuzione) alla distribuzione normale con media μ e varianza σ2/n, e ciò indipendentemente dai dettagli della distribuzione originale.
Fisica
Mentre in fisica classica il concetto di p. trova applicazione praticamente soltanto in meccanica statistica, esso domina in meccanica quantistica (➔ meccanica) e in generale nella fisica quantistica, dove lo stato di un sistema è definibile soltanto mediante le ampiezze di p. che le sue osservabili (➔) hanno di assumere determinati valori. Così, la p. che una particella sia a un certo istante in un certo elemento di volume dτ vale ∣ψ∣2dτ, essendo ψ l’ampiezza di p., soluzione dell’equazione di Schrödinger per la particella in questione (∣ψ∣2 dà la densità di p.).
Grande importanza ha anche la p. di transizione da uno stato all’altro fra quelli possibili per un sistema quantistico. Nel caso di un atto di assorbimento, la p. di transizione da uno stato n a uno m è data, nell’ipotesi che la transizione sia di dipolo elettrico, da
dove amn, bmn, cmn sono gli elementi di matrice delle componenti del dipolo elettrico relativi agli stati m, n. La p. (o coefficiente) di emissione spontanea è data da
dove νmn è la frequenza della radiazione emessa nella transizione; per quanto riguarda poi l’emissione stimolata, essa è caratterizzata dal fatto che si ha Bm→n=Bn→m. Oltre alle transizioni suaccennate sono possibili anche quelle di altri tipi, per es. di dipolo magnetico, di quadrupolo elettrico ecc., caratterizzate da una loro probabilità. P. quantistica Con l’avvento della meccanica quantistica il ruolo della p. nelle teorie fisiche cambia radicalmente: non si tratta più di una descrizione incompleta, sovrapposta a una soggiacente teoria esatta, ma di una necessità fondamentale poiché, per il principio di indeterminazione di Heisenberg, la conoscenza esatta di alcune grandezze implica che, dei valori di altre grandezze, è possibile conoscere solo le distribuzioni di p. e che queste ultime hanno dispersione non nulla (infinita nel caso di grandezze complementari). A questo nuovo ruolo della p. ha corrisposto lo sviluppo di un nuovo formalismo matematico, la p. quantistica, e la corrispondente teoria dei processi stocastici quantistici. Spesso si dice che la differenza tra p. classica e p. quantistica consiste nel fatto che, mentre nella prima si addizionano le p. di eventi disgiunti, nella seconda si addizionano le ampiezze di eventi disgiunti, dove l’ampiezza di un evento è un numero complesso il cui quadrato è la p. dell’evento stesso. Una formulazione più precisa di quest’assetto è che il teorema classico delle p. composte,
[1] formula
nel caso particolare in cui i Bj siano eventi mutuamente disgiunti, non ulteriormente decomponibili, dei quali almeno uno accade con certezza, è rimpiazzato nel caso quantistico dal principio delle ampiezze composte:
[2] formula
dove le ampiezze ψ(A/Bj), ψ(Bj) sono collegate alle corrispondenti p. dalla formula
[3] P(A/Bj) = ∣ψ(A/Bj)∣2; P(Bj) = ∣ψ(Bj)∣2.
La funzione ψ(Bj) è detta funzione d’onda e la formula [3] è detta l’interpretazione statistica della funzione d’onda. Il principio delle ampiezze composte è la formulazione precisa del principio di sovrapposizione. In generale, il membro sinistro della [1] è diverso da quello della [2]. La differenza tra i due è un numero reale espresso come somma di più termini, detti termini d’interferenza. L’uso della [2] per calcolare delle p. è tutt’altro che intuitivo e, se da una parte il successo ottenuto con l’applicazione di questa formula in moltissimi problemi di teoria quantistica giustifica l’idea che essa abbia un fondamento profondo, dall’altra il successo nell’utilizzazione è diverso dalla comprensione e ciò ha stimolato molti tentativi di dedurre sia il principio di sovrapposizione, sia il carattere complesso della funzione d’onda e la relativa interpretazione statistica, da affermazioni con un contenuto fisico più diretto e intuitivo.