
statistica
Scienza che ha per oggetto lo studio dei fenomeni collettivi suscettibili di misura e di descrizione quantitativa: basandosi sulla raccolta di un grande numero di dati inerenti ai fenomeni in esame, e partendo da ipotesi più o meno direttamente suggerite dall’esperienza o da analogie con altri fenomeni già noti, mediante l’applicazione di metodi matematici fondati sul calcolo delle probabilità, si perviene alla formulazione di leggi di media che governano tali fenomeni, dette leggi statistiche; spesso la raccolta dei dati viene limitata a un campione più ristretto, opportunamente predeterminato in modo da rappresentare fedelmente le caratteristiche generali. Concepita inizialmente come attività descrittiva di certi fatti sociali e in particolare come attività amministrativa dello Stato, la s. ha via via ampliato i suoi confini, fino a diventare una vera e propria ‘scienza del collettivo’, disciplina con finalità non solo descrittive dei fenomeni sociali e naturali, ma orientata anche a finalità di ricerca nei vari ambiti scientifici.
Cenni storici
La s. come attività amministrativa indispensabile alla vita delle comunità risale a tempi remotissimi. Nel mondo greco possono considerarsi documenti statistici le tavolette di Pilo (13° sec. a.C.); nell’antica Roma si ha, da Servio Tullio in poi, il census, enumerazione sistematica e periodica dei cittadini e dei loro beni. Dopo la caduta dell’Impero Romano, le rilevazioni statistiche decaddero, per tornare in auge con il fiorire della civilizzazione araba. Con Carlomagno, le corporazioni religiose e il clero presero l’abitudine di compilare liste riguardanti i beni della Chiesa, le nascite, i battesimi e le morti, preparando così il terreno ai registri parrocchiali del 16° secolo. Il primo censimento moderno della popolazione, distinta per sesso, professione, condizione sociale e nazionalità, fu effettuato nel 1440 a Venezia. Di grandissima importanza fu anche il contributo della Chiesa che, dopo il Concilio di Trento, introdusse l’obbligo canonico di registrare i matrimoni, le nascite e le morti.
La s. cominciò ad avere carattere autonomo rispetto alle altre discipline (17° sec.) a opera di V.L. von Seckendorff e soprattutto di H. Conring. Il primo, nel 1656, attribuì alla nuova disciplina il compito di descrivere la vita degli Stati sotto il triplice aspetto del territorio, del governo e delle finanze. Conring migliorò considerevolmente il nuovo indirizzo; una diversa corrente sorgeva, a opera dello storico A.L. von Schlözer e di altri, intesa a fondare la descrizione delle cose notevoli dello Stato sui dati quantitativi, raccolti in forma tabellare. Gradualmente le due correnti si fusero dando luogo a quello che può essere considerato il ramo descrittivo della s. moderna. Nel frattempo, però, era già iniziato in Inghilterra un nuovo importante indirizzo detto degli aritmetici politici. Fondatore della scuola fu J. Graunt che, in particolare, costruì una tavola di mortalità e calcolò la popolazione della città di Londra. A tale lavoro fece presto seguito uno analogo su Dublino, a opera di W. Petty, che si pose per primo il problema di determinare il periodo di tempo occorrente per il raddoppio della popolazione. Il celebre astronomo E. Halley, autorevole seguace della corrente, ideò un metodo per il calcolo delle tavole di mortalità e lo applicò alle liste mortuarie della città di Breslavia. La s. demografica giunse a maturità con J.P. Süss;milch che, sull’indirizzo di Graunt, ricercò le leggi scientifiche del movimento della popolazione.
Accanto a questo indirizzo demografico si andò sviluppando l’indirizzo enciclopedico matematico, che ebbe il suo massimo sviluppo in Francia e impiegò come strumento di indagine la matematica e soprattutto il calcolo delle probabilità ed estese le applicazioni della tecnica statistica a ogni scienza. Il matematico e astronomo belga L.-A.-J. Quételet è da considerarsi il fondatore non solo della nuova corrente, ma di tutta la s. moderna. Nel 1835 egli formulò la teoria dell’‘uomo medio’, per la quale il tipo fisico di una popolazione è identificato dalle medie aritmetiche dei caratteri fisici dei suoi componenti e lo stesso tipo possiede anche gli attributi medi intellettuali e morali.
In tempi più recenti la s. ha conosciuto un’espansione senza precedenti, considerando anche la tendenza moderna di abbandonare i modelli rigidamente causali, per rivolgere l’attenzione piuttosto all’indagine sulle correlazioni e sulle interdipendenze in un quadro di riferimento che sempre più spesso è di carattere prevalentemente probabilistico e riguarda non il dato individuale, ma dati collettivi più o meno vasti.
La statistica metodologica
La s. metodologica (chiamata anche metodologia s.) è costituita dal complesso degli strumenti concettuali, delle tecniche e dei procedimenti matematici che servono alla descrizione, all’analisi di fatti osservati e alla miglior utilizzazione delle informazioni che essi forniscono ai fini della previsione di fatti non osservati. Secondo una classificazione largamente diffusa la s. metodologica si divide in s. descrittiva e in s. inferenziale (o induttiva).
Statistica descrittiva
I metodi della s. descrittiva si propongono di effettuare un’analisi dei dati per scoprirne la struttura e le anomalie (analisi esplorativa) e di operare una sintesi dei dati in modo da far emergere e chiarire le caratteristiche essenziali (analisi descrittiva). Nell’analisi preliminare dei dati si possono individuare le seguenti fasi: a) predisposizione dei dati in una forma utile alle analisi successive; b) verifica della qualità dei dati, accertando l’esistenza di errori, osservazioni mancanti o altre particolarità; c) esame di eventuali modifiche da apportare ai dati (per es., eliminazione di errori o trasformazione di una o due variabili); d) calcolo di alcuni indici sintetici quali la media o lo scarto quadratico medio. Lo studio del mondo fenomenico porta alla considerazione di elementi della realtà che, per loro natura, presentano un’attitudine a variare a seconda delle situazioni in cui si manifestano. Tali fenomeni vengono tradizionalmente denominati fenomeni collettivi, in quanto si manifestano, con intensità diverse, in una pluralità di soggetti. La s. interviene come metodologia per il loro studio.
Con il termine unità statistiche s’intendono i soggetti in corrispondenza dei quali si manifesta un dato fenomeno oggetto di studio, che prende il nome di carattere. I possibili modi di manifestarsi del carattere in corrispondenza delle unità statistiche sono detti modalità. I caratteri possono essere qualitativi e quantitativi. I caratteri qualitativi si manifestano secondo modalità che sono essenzialmente ‘attributi’, per es., il colore degli occhi (azzurro, castano, verde, nero ecc.), il gruppo sanguigno, la nazionalità. Quantitativi sono, invece, i caratteri che assumono come modalità numeri cardinali. In una data popolazione finita di N unità, dette xi, la modalità che il carattere assume in corrispondenza all’unità i, N(xi) la frequenza
assoluta e f(xi) = N(xi)−−−−−N quella relativa, quan-
do la rappresentazione del ‘modo di manifestarsi’ di un certo carattere avviene in termini di modalità-frequenze, si parla di variabile statistica. In modo molto informale, una variabile statistica X è un ‘oggetto’ che assume, in una data popolazione, le modalità x1, x2, ..., xk rispettivamente con frequenze assolute N(x1), N(x2), ..., N(xk), e con frequenze relative f(x1), f(x2), ..., f(xk). Se il carattere oggetto di studio è quantitativo o perlomeno qualitativo ordinato, e supponendo che x1<x2<...<xk, si possono definire le frequenze cumulate (relative) come:
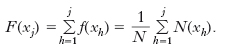
La funzione F(∙), che a ogni modalità xj associa la corrispondente frequenza relativa cumulata, è detta funzione di ripartizione. Per sintetizzare le informazioni raccolte e mettere in evidenza le caratteristiche salienti della distribuzione, si ricorre innanzitutto al calcolo della media aritmetica, armonica, geometrica, e più in generale della media esponenziale.
La sintesi di una distribuzione di frequenza mediante una media (o mediante la mediana, la moda, o i quantili), che in qualche modo svolga il ruolo di indice di posizione, è di per sé estremamente incompleta e parziale, in quanto nulla ci dice sulla dispersione della distribuzione, cioè sul ‘grado di diversità’ delle modalità che la corrispondente variabile statistica può assumere. A questo scopo s’introducono gli indici di variabilità. Gli indici di variabilità rispondono all’obiettivo di misurare l’‘attitudine a variare’ del fenomeno oggetto di studio, ossia la sua attitudine ad assumere modalità diverse in corrispondenza di unità diverse. Le due più usuali maniere di formalizzare la nozione di variabilità sono quelle basate sui concetti di dispersione (attorno a un polo di riferimento) e di mutua variabilità delle modalità del carattere. Nel caso della dispersione l’idea di base è quella di studiare la variabilità facendo riferimento a come le modalità del fenomeno oggetto di studio sono disperse attorno a qualche ‘polo’ (media) di riferimento, usando come indici di variabilità lo scostamento semplice dalla media, lo scarto quadratico medio (deviazione standard) o il suo quadrato, denominato varianza.
Molto spesso, per le unità di una certa popolazione, si osservano le modalità assunte da più caratteri. Il principale oggetto d’interesse, in questa nuova situazione, sono le relazioni tra caratteri, cioè il ‘modo’ in cui due o più caratteri si manifestano congiuntamente in una stessa popolazione. Limitandoci a due soli caratteri, data una distribuzione di frequenze di una variabile statistica bivariata (X, Y) si possono ricostruire facilmente anche le distribuzioni di frequenze delle sue due componenti X e Y singolarmente considerate, ossia, come anche si dice, le sue distribuzioni di frequenze marginali. Quanto all’indipendenza tra due variabili statistiche: siano X e Y due variabili statistiche (corrispondenti a caratteri di qualsiasi natura, qualitativa o quantitativa), che assumono rispettivamente le modalità x1, x2, ..., xk e y1, y2, ..., ym con frequenze relative congiunte f(xj, yh) (j=1, 2, ..., k; h=1, 2, ..., m); in simboli: f(xj, yh)= freq. rel. {X=xj, Y=yh} j=1, 2, ..., k; h=1, 2, ..., m. Inoltre, indichiamo con
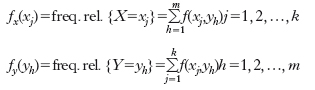
le frequenze relative rispettivamente delle due variabili statistiche X e Y. Le variabili statistiche X e Y sono indipendenti se le frequenze relative congiunte f(xj, yk) sono uguali al prodotto delle corrispondenti frequenze relative marginali. Se due variabili statistiche X e Y sono indipendenti, la conoscenza delle sole frequenze (relative) marginali consente di determinare, di costruire anche le frequenze (relative) congiunte, le quali individuano completamente il ‘modo’ in cui le due variabili statistiche si associano (cioè il modo in cui le due variabili statistiche si presentano congiuntamente). Quindi, l’indipendenza corrisponde a una struttura di associazione estremamente semplice.
L’indipendenza tra due variabili statistiche è un fenomeno assai raro nella pratica applicativa. Molto più comuni sono invece le situazioni in cui vi è una dipendenza (connessione) tra le due variabili statistiche considerate. In termini molto intuitivi, due variabili statistiche sono tanto più connesse quanto più le loro frequenze relative congiunte sono differenti da quelle che si avrebbero nel caso d’indipendenza. Il più importante indice di connessione è l’indice χ–quadrato dovuto a K. Pearson e indicato di solito col simbolo χ2. Nello studio della dipendenza lineare alla variabile statistica doppia (X, Y) si sostituisce una variabile statistica del tipo (X, α+βX); equivalentemente, si può anche dire che alla variabile statistica Y si sostituisce una variabile statistica del tipo α+βX, cioè una funzione lineare della variabile statistica X. Precisando i valori di α e β in modo tale da rendere minima la perdita globale di informazione sui dati, si ottiene la retta di regressione di Y rispetto a X.
Un capitolo importante della s. descrittiva, che ha avuto un fortissimo impulso grazie alla diffusione degli calcolatori, è la cluster analysis. Con questa tecnica dato un gruppo di N oggetti o individui, ognuno dei quali misurato su p variabili, si trova uno schema di classificazione per raggruppare gli oggetti in g classi, il più possibile omogenee, e si determina il numero e le caratteristiche delle classi. Gli scopi dell’operazione possono essere svariati: trovare una ‘vera’ tipologia, applicare modelli prefigurati, fare previsioni basate sui gruppi, verificare delle ipotesi, facilitare l’analisi dei dati, suggerire nuove ipotesi, ridurre la mole dei dati. Alla molteplicità degli usi fa riscontro la molteplicità dei metodi proposti. I più diffusi rientrano in una delle due seguenti categorie: a) metodi gerarchici; b) metodi di partizione e ottimizzazione. I primi, a loro volta, si distinguono in agglomerativi (quando si procede a fusioni successive) e partitivi (quando si suddividono progressivamente i cluster); entrambi i casi escludono la possibilità di correggere errori di classificazione iniziale. Tale possibilità sussiste invece nei metodi di partizione e ottimizzazione che sono iterativi e si fondano in generale sulla minimizzazione di funzioni-obiettivo.
Nello stesso indirizzo della cluster analysis rientrano tecniche quali l’analisi delle componenti principali, l’analisi fattoriale e l’analisi discriminante. L’analisi delle componenti principali è una tecnica che permette di spiegare la variabilità di un fenomeno osservando il comportamento di questo al variare di altri fenomeni; l’analisi fattoriale, invece, cerca di individuare quei fattori che determinano una data dipendenza tra le variabili osservate, e parte dal presupposto che esistano dei fattori che causano direttamente o indirettamente la correlazione lineare già esistente tra le variabili; l’analisi discriminante, infine, si applica ai casi in cui si cerca di individuare quei criteri che, in base alle caratteristiche di un oggetto, consentono di classificarlo in uno dei diversi gruppi preesistenti. L’analisi permette inoltre di valutare il grado di discriminazione nel processo di classificazione.
Negli anni 1960, per merito soprattutto di alcuni studiosi francesi (J.-P. Benzecri, J.-M. Bouroche, L. Lebart e altri), si è sviluppata una teoria compatta, l’analisi delle corrispondenze, che, utilizzando nozioni avanzate di algebra lineare, permette di trattare unitariamente queste diverse tecniche, le quali consentono, attraverso l’individuazione di alcuni autovettori di matrici opportunamente determinate, di rendere leggibili masse anche enormi di dati e di individuare affinità e differenze fra gli individui e fra i caratteri (sia qualitativi sia quantitativi) e i legami fra questi e quelli, anche mediante un’efficace rappresentazione grafica nella quale trovano collocazione gli individui insieme con i caratteri.
Statistica inferenziale
Si ha un’inferenza statistica quando, sulla base dell’informazione fornita dall’osservazione di alcuni fatti e poi registrata in s., si formulano supposizioni o previsioni riguardanti altri fatti rimasti incerti. È evidente lo stretto legame tra s. inferenziale e teoria matematica della probabilità: l’incertezza riguardo ai fatti d’interesse si può infatti esprimere mediante probabilità, mentre l’acquisizione di nuova informazione corrisponde al calcolo di probabilità condizionate.
Diversi sono i problemi tipici della s. inferenziale. Se effettuiamo un esperimento ξ, in una data situazione, possiamo ottenere evidentemente diversi risultati; i dati che si ottengono effettivamente dall’esperimento costituiscono pertanto solo un punto di uno spazio di possibili dati. È abbastanza naturale allora impostare l’analisi su tale spazio, insieme dei possibili risultati sperimentali, che indichiamo con Z. Per effettuare un’analisi statistica occorre dotare Z di una struttura matematica. Lo spazio Z viene reso misurabile associandolo a un’appropriata σ-algebra A. In questo contesto un modello statistico probabilistico per l’esperimento ξ è una terna (Z, A, P), ove P è una famiglia di misure di probabilità sullo spazio misurabile (Z, A). L’elemento essenziale del modello statistico è proprio P. I dati z, z ∈ Z che si ricavano da ξ, una volta che l’esperimento è stato condotto, costituiscono la premessa per inferire su P. Le misure di probabilità P possono essere indicizzate da un parametro ϑ, ϑ ∈ Θ: P = (Pθ: ϑ ∈ Θ); cioè, a ogni ϑ è associata una misura di probabilità Pθ (o una funzione di densità p(z/ϑ)) che assegna la probabilità ai sottoinsiemi di A. Θ è detto spazio dei parametri. Il modello statistico può essere presentato nella forma semplificata
Per ogni scelta di ϑ in Θ selezioniamo una funzione di densità che regola il meccanismo aleatorio che genera i risultati sperimentali. Quando Θ è un sottoinsieme di uno spazio euclideo, il modello viene detto parametrico, altrimenti viene detto non parametrico. I tipici problemi che si presentano nella s. inferenziale sono quelli di stima e di prova delle ipotesi. Il problema della stima consiste nello scegliere un valore ϑ ∈ Θ che plausibilmente ha generato, attraverso il modello, l’osservazione z*. Il problema di prova delle ipotesi consiste nel ripartire l’insieme dei valori ammissibili Θ in due sottoinsiemi Θ 1 e Θ 2, e decidere se il parametro ϑ che ha generato l’osservazione z* appartiene a Θ 1, oppure a Θ 2.
Uno dei principali problemi della s. è quello della robustezza. Si definiscono robusti quei procedimenti induttivi che conservano una buona efficacia anche quando le ipotesi del modello con cui si opera e che specificano le caratteristiche della popolazione da cui sono tratte le osservazioni campionarie non sono valide. Così, per es., è dimostrato che in molti casi stime basate su una media ponderata delle osservazioni, scartando i valori estremi, sono più efficienti della media aritmetica per stimare la media della popolazione. Gli studi sulla robustezza, condotti mediante il metodo della simulazione, riguardano le stime di vari parametri (sia di locazione sia di scala, come, per es., la varianza), la teoria dei test statistici e quella della regressione.
In un’ottica non dissimile si colloca la proposta di inquadrare le tecniche classiche di analisi della varianza, covarianza e regressione in una teoria più ampia, detta dei modelli lineari generalizzati (J.E. Nelson e J.H. Wedderburn). Nell’impostazione classica si ipotizza che il vettore delle osservazioni sia costituito da una componente sistematica avente una struttura lineare in parametri incogniti e da una componente stocastica (errore) distribuita secondo la legge di Gauss, indipendente dalla componente sistematica e con varianza costante. Nella nuova impostazione, invece, si parte dall’ipotesi più generale che la componente stocastica segua una distribuzione con funzione di densità appartenente alla famiglia esponenziale (che comprende, oltre alla legge gaussiana, altre distribuzioni importanti, come la binomiale, la poissoniana, la gamma ecc.) e si contempla una struttura meno rigida della componente sistematica. In particolare, si ha il modello log-lineare quando la distribuzione è poissoniana e la funzione che lega i parametri è logaritmica; se quest’ultima è la funzione di ripartizione della distribuzione normale, il modello si dice probit. I modelli lineari dinamici, che godono della proprietà markoviana, si basano invece su due equazioni lineari, una per le osservazioni e una per i parametri che evolvono nel tempo. La connessione tra il problema della stima dei parametri e questi modelli è data dal filtro di Kalman.
Un posto centrale nella s. occupa il campionamento o teoria dei campioni (➔ campione; sequenziale, analisi). Molto spazio è dedicato alla ricerca nel campo dei processi stocastici. Uno sviluppo particolarmente intenso hanno avuto gli studi riguardanti i processi aleatori di punti che possono essere definiti come i modelli matematici, che si presentano considerando fenomeni rappresentabili come popolazioni disposte in modo aleatorio in un dato spazio, o successioni di eventi che si verificano in modo aleatorio nel tempo. Le proprietà interessanti di questi processi si possono suddividere in due categorie: a) proprietà di conteggio, cioè proprietà legate al numero di punti contenuti in un dato sottoinsieme dello spazio degli stati; b) proprietà di intervallo, cioè legate allo spazio che separa due ‘punti-evento’. Moltissimi problemi statistici possono essere ricondotti a processi di questo tipo (per es., lo studio dei terremoti).
Su un piano diverso merita una segnalazione anche lo studio delle serie temporali mediante i processi ARMA (autoregressive moving average). Si tratta di modelli molto flessibili, miranti a fornire un’adeguata rappresentazione delle serie temporali con un numero minimo di parametri e con algoritmi relativamente semplici.
Astronomia
La s. stellare è la disciplina che applica i metodi statistici allo studio della distribuzione delle stelle nella Galassia. Le funzioni fondamentali della s. stellare sono: la funzione di densità spaziale D(r, l, b), che dà il numero di stelle per unità di volume situate alla distanza r e nella direzione individuata dalla longitudine l e dalla latitudine b, nel sistema di coordinate galattiche; la funzione di luminosità Φ(M), che dà la frazione di stelle con magnitudini assolute comprese fra M−1/2 e M+1/2. I risultati della s. stellare sono stati fondamentali per determinare la struttura della Via Lattea.
Economia
La s. aziendale è una disciplina che utilizza il metodo statistico per trattare fenomeni di rilevanza aziendale. Le più importanti applicazioni della s. riguardano l’analisi dei costi, la misura del lavoro, la razionalizzazione della gestione delle scorte e, in generale, la previsione e la programmazione dell’attività aziendale a breve e medio periodo attraverso le s. del personale, degli impianti, delle vendite, della produzione, degli approvvigionamenti, dei finanziamenti e di tutte le variabili e le informazioni tecniche ed economiche che direttamente e indirettamente possono influire sulle decisioni (fra cui i programmi delle spese pubbliche, i piani d’investimento delle grandi imprese, le prospettive settoriali di produzione e di evoluzione tecnologica, la mobilità della popolazione, i livelli di urbanizzazione ecc.). In particolare, nella sfera delle ricerche commerciali, la s. consente l’analisi dell’andamento delle vendite e delle loro variazioni stagionali, cicliche e tendenziali, la formulazione di previsioni sul loro andamento futuro, lo studio di funzioni di domanda. Nella sfera delle applicazioni industriali, la s. contribuisce a garantire la qualità e l’incremento della produzione, a dimensionare i costi e a contenere i consumi attraverso la riduzione degli scarti e una migliore utilizzazione delle materie prime.
La s. economica è un ramo della s. applicata che studia, con l’ausilio del metodo statistico, i fenomeni economici collettivi, cioè i fatti dell’attività umana risultanti dalla combinazione di numerosi soggetti economici; tali fatti scaturiscono dalle complesse azioni e interazioni originate nell’ambito dei settori istituzionali (imprese, pubblica amministrazione, famiglie) nei loro rapporti reciproci e nelle loro relazioni con i paesi esteri, e si manifestano in attività rivolte alle fondamentali categorie della produzione, della distribuzione, del consumo e della formazione del capitale. La s. economica si occupa quindi della rilevazione dei dati economici e finanziari (operazione che si concreta nell’enumerazione, misurazione e acquisizione di tutti gli elementi d’informazione necessari per la determinazione dei fondi e dei flussi di natura economica e finanziaria); dell’elaborazione e dell’analisi dei dati grezzi al fine anche della descrizione delle caratteristiche strutturali e dinamiche dei fenomeni stessi e della loro comparazione temporale e spaziale; della scoperta di rapporti reciproci tra i fenomeni e della ricerca, attraverso la verifica empirica, di uniformità, regolarità e leggi statistiche (intese in senso probabilistico e non deterministico).
Fisica
L’introduzione di metodi statistici in questioni fisiche trova una valida giustificazione e applicazione in tutti quei problemi ove si tratti di sistemi con un numero di componenti così grande da escludere la possibilità di seguire le vicende di ogni singolo componente. Si consideri, per es., una mole di gas: essa contiene un numero di molecole pari al numero di Avogadro, cioè ben 6∙1023 molecole; è assurdo pensare di risolvere un sistema di un pari numero di equazioni del moto per descrivere l’evoluzione temporale di un tale complesso di particelle e fare previsioni sul suo comportamento. Scartando questo modo di procedere si può soltanto cercare di pervenire alla determinazione dei comportamenti medi del sistema, negli stati di equilibrio termodinamico, con i metodi propri della meccanica statistica.
Principi di meccanica statistica
La meccanica statistica classica, sviluppatasi principalmente per le esigenze della teoria cinetica dei gas e fondata sulla s. di Maxwell-Boltzmann, mostra la propria limitazione nelle ipotesi stesse su cui si basa e cioè: la distinguibilità delle particelle costituenti il sistema e la non esistenza di alcuna limitazione al numero di punti rappresentativi che possono essere presenti in un dato volumetto dello spazio delle fasi. La meccanica statistica classica cessa di valere quando il sistema in esame mostra effetti quantistici, in particolare nel grado di occupazione degli stati, i quali traggono origine dal fatto che in meccanica quantistica cade la validità del concetto di distinguibilità di particelle identiche.
I sistemi quantistici possono essere divisi in due classi a seconda delle proprietà di simmetria delle funzioni d’onda descriventi le particelle identiche che li compongono. Nel caso di particelle dotate di spin semintero le funzioni d’onda risultano antisimmetriche rispetto allo scambio dello stato di due particelle: tali particelle obbediscono al principio di esclusione di Pauli, seguono la s. di Fermi-Dirac e sono dette fermioni. Invece le particelle di spin intero, che mostrano proprietà di simmetria per le funzioni d’onda e per le quali non vale il principio di esclusione di Pauli, seguono la s. di Bose-Einstein e sono dette bosoni. È possibile generalizzare le due s. precedenti, pervenendo alle cosiddette s. intermedie o gentiliane, che tuttavia non hanno trovato applicazioni fisiche. Poiché, per il principio di indeterminazione, le minime indeterminazioni simultanee della posizione (Δx, Δy, Δz) e della quantità di moto (Δpx, Δpy, Δpz) di una particella risultano legate da

dove h è la costante di Planck e h3 è il minimo volume osservabile dello spazio delle fasi di una particella con tre gradi di libertà, anche nella meccanica statistica classica è utile assumere che la migliore determinazione possibile dello stato di una particella, con n gradi di libertà, sia limitata al volume hn.
Statistica di Maxwell-Boltzmann
Un sistema S sia costituito da un numero molto grande di sistemi elementari, o particelle, che penseremo simili tra loro ma distinguibili l’uno dall’altro. Ciascuna particella abbia n gradi di libertà, sia soggetta a forze conservative e fra le varie particelle non si esercitino mutue azioni, all’infuori eventualmente di quelle dovute a urti. Un esempio di un tale sistema è dato da un gas perfetto, ove le particelle sono le molecole del gas (a 3 gradi di libertà se il gas è monoatomico, a 5 se biatomico ecc.). Lo stato (posizione e atto di moto) di ciascuna particella resta determinato, istante per istante, dai valori che nell’istante che si considera competono alle n coordinate lagrangiane, q1, q2, ..., qn, e agli n momenti cinetici corrispondenti, p1, p2, ..., pn, e può quindi essere rappresentato da un punto dello spazio delle fasi, spazio a 2n dimensioni in cui come coordinate cartesiane ortogonali si pensano assunte precisamente le q e le p. Lo stato dell’intero sistema a un dato istante risulterà statisticamente determinato quando sia determinata la legge secondo cui si ripartiscono nello spazio delle fasi gli N punti rappresentativi dello stato delle N particelle del sistema. Al fine di determinare nel modo più semplice tale legge di ripartizione si pensa lo spazio delle fasi suddiviso in tante celle, aventi volume abbastanza grande perché ogni cella contenga un considerevole numero di punti rappresentativi e di stati (il numero dei quali, per quanto detto sopra, è dato dal rapporto tra il volume della cella e hn), ma nello stesso tempo abbastanza piccolo perché le variazioni delle grandezze fisiche rilevanti, come, per es., l’energia, all’interno di una cella si possano considerare trascurabili. Le varie celle si possono numerare e siano N1, N2, ... i numeri di particelle i cui punti rappresentativi cadono nella 1ª, 2ª, ... cella e M1, M2, ... il numero degli stati nelle celle. L’insieme N1, N2, ... individua ciò che si chiama una configurazione statistica del sistema. Una stessa configurazione statistica può ovviamente realizzarsi in più modi, detti complessioni o microstati, e con considerazioni elementari di calcolo combinatorio, tenendo in conto che le particelle sono distinguibili, si trova che il numero W delle complessioni corrispondenti a una stessa configurazione statistica è dato da
Se si ammette, per l’ipotesi ergodica (➔ meccanica), che il sistema possa trovarsi con uguale probabilità in ognuno dei microstati permessi, si può definire la probabilità che S abbia una data configurazione statistica come il rapporto fra il numero di modi in cui può ottenersi la configurazione considerata e il numero di modi in cui possono ottenersi tutte le possibili configurazioni di S, e pertanto essa risulta proporzionale al numero W delle complessioni relative a quella configurazione. Si assume che, fra tutte le configurazioni possibili, quella di massima probabilità descriva lo stato di equilibrio termodinamico del sistema. Per la ricerca di tale configurazione occorre tenere presente che i numeri Ni sono vincolati da due relazioni. Una di esse,
esprime che il numero totale delle particelle è costante ed è N. L’altra esprime il principio di conservazione dell’energia e, poiché dentro ogni cella l’energia non varia sensibilmente, indicando con E1, E2 ... l’energia delle particelle appartenenti alla 1ª, 2ª, ... cella e con ET l’energia totale di S, si ha
Il problema della ricerca della configurazione più probabile si riduce così alla determinazione dei numeri N1, N2, ... in modo che, soddisfacendo alle due relazioni precedenti, rendano massimo W: si riconosce che tale configurazione è quella per la quale risulta
in cui g e β sono parametri che si possono determinare in modo appunto da soddisfare alle relazioni suddette. Tenendo inoltre presente che Ni, tramite Mi, risulta proporzionale al volume della i-esima cella, il risultato precedente può essere così formulato: il numero dN di particelle i cui punti rappresentativi cadono nell’elemento dτ di volume dello spazio delle fasi è dato da
μ essendo il potenziale chimico e T la temperatura termodinamica del sistema, k la costante di Boltzmann, mentre E è l’energia di una particella espressa in funzione delle sue variabili di stato q e p. Questa formula, detta distribuzione (o legge di ripartizione) di Boltzmann (o di Maxwell-Boltzmann), si può considerare il risultato principale della meccanica statistica classica.
Tra le più importanti conseguenze di tale legge vi sono il principio dell’equipartizione dell’energia e la legge di distribuzione delle velocità di Maxwell. Il principio dell’equipartizione dell’energia afferma che, all’energia media di un gas perfetto, ogni grado di libertà traslatorio contribuisce con la quantità kT/2 e ogni grado di libertà oscillatorio con la quantità kT. La legge di distribuzione delle velocità di Maxwell stabilisce che in un gas alla temperatura T il numero di molecole per le quali il modulo della velocità di traslazione è compreso tra v e v+dv è dato da
essendo m la massa di una molecola. Da questa relazione si ricavano facilmente il quadrato della velocità più probabile, della velocità media e della velocità quadratica media, rispettivamente uguali a 2kT/m, 8kT/πm, 3kT/m. L’evoluzione temporale della funzione di distribuzione è descritta, nell’ambito della fisica classica, dall’equazione di Boltzmann (➔ termodinamica).
Statistica di Fermi-Dirac
Il caso di un sistema di fermioni identici, non interagenti, si può trattare dividendo gli stati quantistici di singola particella in gruppi, detti anche celle, contenenti un numero sufficientemente elevato di stati con energie vicine. Si determina quindi il numero W di modi di realizzare la configurazione statistica in cui Ni fermioni sono distribuiti tra gli Mi stati, con energie Ei, della i-ma cella. Tenendo conto della indistinguibilità delle particelle e del principio di esclusione di Pauli, per cui ogni stato potrà essere occupato al massimo da una particella, si ha:
Il numero di occupazione medio di uno stato, cioè il numero medio di particelle, ns, che, all’equilibrio termodinamico, si trovano in quello stato, si ottiene, infine, massimizzando W, con le condizioni

dove N è il numero totale di particelle ed ET l’energia del sistema, e dividendo ogni Ni così determinato per il corrispondente Mi. In questo modo si ricava la funzione di distribuzione di Fermi-Dirac, o fattore di Fermi,
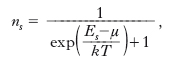
dove μ, definito implicitamente (come funzione della temperatura e della densità ρ=N/V, V essendo il volume del gas) dalla relazione

è il potenziale chimico del sistema, che in questo contesto è detto anche livello di Fermi e corrisponde all’energia degli stati che, per T>0, hanno probabilità 1/2 di essere occupati (per i fermioni, la probabilità di occupazione di uno stato coincide con il numero di occupazione medio dello stato). Il fattore di Fermi è una funzione decrescente, compresa tra 0 e 1, dell’energia Es, che presenta un flesso per il valore Es=μ, intorno al quale varia tanto più rapidamente quanto più la temperatura è bassa, poiché la regione di rapida variazione è dell’ordine di kT (fig. 1). Quando T=0 la distribuzione di Fermi-Dirac è una funzione a gradino, con una discontinuità per Es=μ(T=0)=μ0, tale che il numero di occupazione vale 1 per gli stati con Es<μ0 e vale 0 per quelli con Es>μ0; questo valore limite per l’energia degli stati occupati allo zero termodinamico è detto energia di Fermi, EF (=μ0); a essa si suole far corrispondere una temperatura di Fermi, o temperatura di degenerazione, tramite la relazione EF=kTF. Nel caso di fermioni di spin 1/2 e massa m, con hamiltoniana di singola particella H=p2/2m, si ha
e quindi
il modulo dell’impulso di singola particella corrispondente all’energia EF, detto impulso di Fermi, in questo caso si scrive
Come conseguenza del principio di Pauli, che permette di avere nello stato di impulso nullo solo 2s+1 fermioni di spin s, un gas di fermioni possiede quindi energia e pressione diverse da zero anche allo zero termodinamico.
Statistica di Bose-Einstein
Per un sistema composto da bosoni identici, non interagenti, si procede come per i fermioni, tenendo conto del fatto che, in questo caso, le particelle sono indistinguibili, ma non esistono vincoli sul numero di occupazione di un singolo stato. Il numero W di modi di realizzare la configurazione statistica in cui Ni bosoni sono distribuiti tra gli Mi stati, con energie Ei, della i-ma cella è
Il numero di occupazione medio di uno stato, ns, si ricava massimizzando W, con le condizioni
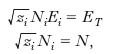
dove N è il numero totale di particelle e ET l’energia del sistema, e dividendo ogni Ni così determinato per il corrispondente Mi. In questo modo si ottiene la funzione di distribuzione di Bose-Einstein, o fattore di Bose,
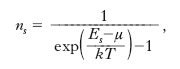
dove μ, funzione della temperatura e della densità ρ=N/V, definita implicitamente dalla relazione √‾‾‾zsns=N, è il potenziale chimico del sistema, necessariamente minore della minima energia accessibile a una singola particella, E0, affinché i numeri di occupazione non siano negativi. A differenza del fattore di Fermi, il fattore di Bose non è limitato, anzi può diventare molto grande se il valore di Es è vicino a μ, come accade per lo stato di energia E0 quando, abbassando la temperatura del sistema, mantenendo costante la sua densità, il potenziale chimico cresce avvicinandosi al suo limite superiore E0; in questa situazione si può presentare il fenomeno, detto condensazione di Bose-Einstein, nel quale una frazione finita delle particelle occupa un singolo stato, lo stato fondamentale; la temperatura, Tc, alla quale ha inizio questo processo, di pura origine quantistica e che ha luogo in assenza di forze tra le particelle, è detta temperatura di degenerazione o temperatura critica. Nel caso di bosoni con spin zero, di massa m, con hamiltoniana di singola particella H=p2/2m, si ha Tc=3,31 ρ2/3 ħ2/mk; per T<Tc il sistema si può considerare una miscela di due fasi termodinamiche: a) una fase gassosa, composta da Ne=N(T/Tc)3/2 particelle distribuite sugli stati eccitati; b) una fase condensata, costituita dalle restanti N0 particelle che occupano lo stato fondamentale, di impulso nullo, e che quindi non contribuiscono né alla energia né alla pressione del sistema. Si osservi che la separazione delle fasi avviene nello spazio degli impulsi e non, come nelle transizioni di fase classiche, nello spazio delle coordinate, con conseguente separazione fisica delle due fasi: il sistema resta omogeneo nello spazio ordinario. Sull’analogia con la condensazione di Bose-Einstein sono basate le teorie che spiegano la superconduzione e la superfluidità. La funzione di distribuzione di Bose-Einstein descrive anche l’equilibrio termodinamico di un gas di fotoni, che sono bosoni, se si tiene presente che, in questo caso, non essendo il numero di particelle una quantità conservata, il potenziale chimico è identicamente nullo: ponendo μ=0 e Es=ℏωs, il fattore di Bose si riduce alla distribuzione di Planck.
Applicabilità della statistica classica
Ambedue le distribuzioni quantistiche, nel caso in cui exp{(Es−μ)/kT}>>1, cioè quando i numeri di occupazione dei singoli stati sono molto minori di 1, si riducono alla forma exp{(μ−Es)/kT}, che è la densità di particelle nello spazio delle fasi ottenuta usando la s. classica di Maxwell-Boltzmann. La condizione scritta sopra è soddisfatta quando risulta
D è detto parametro di degenerazione e λ lunghezza d’onda termica, in quanto h/(2πmkT)3/2 è la lunghezza d’onda di de Broglie di una particella di massa m con energia kT; riscrivendo la condizione per D come

si vede che essa assicura che, nel caso di distanza media tra le particelle molto più grande della loro lunghezza d’onda quantistica media, gli effetti quantistici sono trascurabili. Quando l’ordine di grandezza di D è 1 il sistema è detto degenere e mostra un comportamento che differisce in maniera sostanziale da quello classico, caratterizzato da effetti tipicamente quantistici. La uguaglianza D=1 determina, per densità del sistema fissata, l’ordine di grandezza della temperatura di degenerazione; poiché, per es., nel caso di idrogeno a densità normale, per la temperatura così stimata, si ottiene 1 K, mentre nel caso degli elettroni di conduzione del ferro si ottiene 105 K, si capisce perché, a temperatura ambiente, i gas in condizioni normali possono essere trattati con la s. di Maxwell-Boltzmann, mentre il contributo degli elettroni alla proprietà dei conduttori va determinato usando la s. di Fermi-Dirac. Per temperatura fissata, D=1 determina l’ordine di grandezza della densità di degenerazione. Si osservi infine che la s. di Maxwell-Boltzmann si può considerare intermedia tra le due s. quantistiche (fig. 2), nel senso che le grandezze fisiche calcolate con queste ultime hanno correzioni di segno opposto rispetto alle stesse grandezze calcolate con la s. classica; per es., a temperatura e densità fissate, un gas descritto dalla s. di Fermi-Dirac ha pressione maggiore di quella di un gas classico, mentre se è descritto dalla s. di Bose-Einstein ha pressione minore; si può dire che gli effetti quantistici di scambio tra le particelle conducono alla comparsa di una repulsione efficace tra i fermioni e a una attrazione efficace tra i bosoni.
Linguistica
S. linguistica È l’applicazione del metodo statistico all’esame dei fatti linguistici, e in particolare alla rilevazione delle frequenze medie che le parole e i fonemi (e in genere le unità costitutive di una lingua) hanno nel discorso, e delle eventuali trasformazioni che tali frequenze subiscono nel tempo.
Una cosciente e autonoma esigenza dei computi statistici in linguistica, nel passato condotti in modo asistematico e subordinati a interessi stilistici, pedagogici, psicologici, o tecnici, si è affermata con lo strutturalismo, con le enunciazioni della scuola di Praga, e, in tempi più recenti, con le teorizzazioni di G.K. Zipf, P. Guiraud, Z.S. Harris e altri. Le realizzazioni più immediate delle ricerche statistiche sono i dizionari dell’uso corrente, nei quali i vocaboli sono ordinati secondo la frequenza decrescente con cui compaiono nei testi analizzati.
Medicina
S. sanitaria È la branca della s. che precipuamente si applica alle discipline del settore sanitario. L’impiego della s. in campo medico-biologico si sviluppa nei primi decenni del 20° sec., contemporaneamente alla necessità di estendere il campo di osservazione dal singolo individuo (osservazione qualitativa) a un insieme numericamente variabile di individui (osservazione quantitativa). Il metodo statistico è fondamentale nei diversi passi che devono essere compiuti per fornire una risposta a un quesito scientifico; rappresenta quindi uno strumento essenziale per poter descrivere e interpretare quanto osservato, ma soprattutto per ottenere delle osservazioni che rivestano caratteristiche di validità e di generalizzazione oltre i confini della popolazione impiegata per l’indagine.
Malgrado la obbligatorietà di denuncia di determinate malattie e l’esistenza di s. riguardanti ricoveri ospedalieri o altre informazioni similari, non sempre è possibile su queste basi ottenere una valutazione precisa dello stato di salute della popolazione. A questo scopo vengono avviati sistemi autonomi per la raccolta di informazioni (registri) o indagini campionarie. Per integrare le informazioni che possono essere ricavate dalle fonti sopradescritte o per rispondere a specifici quesiti sperimentali, possono essere avviate indagini ad hoc.
Le tappe principali per l’impostazione corretta di uno studio sono: a) pianificazione: definizione degli obiettivi dello studio, scelta del tipo di studio, della popolazione, delle variabili da misurare, degli strumenti da utilizzare per ottenere le misurazioni, campionamento, pianificazione dell’analisi dei dati, delle fasi dello studio in termini anche temporali, spaziali e di risorse; b) organizzazione: arruolamento della popolazione, degli operatori che devono essere formati, standardizzati e testati per ottenere una omogeneità di procedure, standardizzazione delle tecniche da impiegare, organizzazione delle operazioni sul campo; c) esecuzione: con attenta supervisione delle operazioni e controllo della collaborazione della popolazione; d) valutazione e ricadute: analisi interinali e finali dei dati con valutazione delle loro ricadute.
Si distinguono studi trasversali (nei quali viene effettuato un esame della popolazione a un determinato momento temporale) e studi longitudinali. Questi ultimi possono essere suddivisi in: studi retrospettivi o prospettivi, in funzione del tempo; studi osservazionali o sperimentali, a seconda della presenza o meno di un intervento; studi di tipo caso-controllo o con gruppi a trattamento e gruppi a controllo, a seconda dei gruppi che vengono implicati nell’indagine. Particolare importanza nella s. sanitaria ha il rilevamento dei fattori di rischio.